【Gradioの使い方解説】チャットボット・翻訳ツールが簡単に作れるPythonライブラリ

WEELメディア事業部AIライターの2scです。
エンジニアのみなさん!Web UI作成用のPythonパッケージ「Gradio」はご存知ですか?Hugging Faceでよくみる「アレ」です!
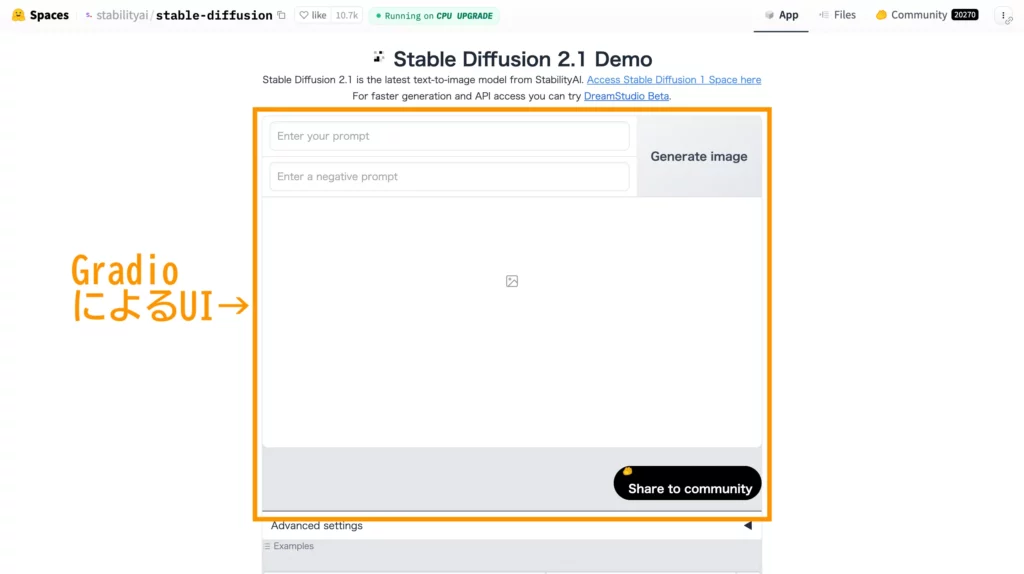
このGradioなら、JavaScriptやCSSの知識がなくても、下記のようなWeb UIが簡単に作成可能。自作AIツールのデモ版を一般公開したい場合に超便利なんです!
当記事では、そんなGradioの使い方と作例を徹底解説。完読いただくと、自分専用のAIツールを作ってみたくなっちゃうはずです。ぜひぜひ、最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Webアプリケーションが作れる「Gradio」とは?
「Gradio」とは、簡易版Web UI(ユーザーインタフェース)作成用のPythonパッケージ。「pip install」だけで始められて、各種AIモデル用のデモ画面が一瞬で用意できます。
そんなGradioのすごいところとしては……
参考:https://huggingface.co/spaces/stabilityai/stable-diffusion
● 「pip install gradio」だけで使えて、その他ライブラリやパッケージは不要
● テキストはもちろん、画像・動画・音声・ファイル…etc.の入出力にも対応
● オープンソースのため、著作権・料金フリーで利用可能
● JavaScript & CSSの知識なしでデモ用のWebページが作成可
● 作ったデモはHugging Faceで永久的に公開可(サーバー立て不要)
以上のとおりで、とっつきにくいAIモデルをWebアプリの形で公開できるのが魅力です。
なお、Stable Diffusion用のWeb UIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Gradioの利用料金
Gradio自体はオープンソースで提供されているため、無償で利用することができます。
ただし、Gradioはあくまでもフロントエンドのため、バックで利用するAIモデルによっては各モデルのAPIの費用が必要となってきますのでご注意ください。
Gradioのライセンス・商用利用について
GradioのライセンスはApache2.0となっています。
Apache 2.0はオープンソースソフトウェアで使われているライセンスで、著作権表示や改変内容の明示といった項目を守れば商用利用も可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | 〇 |
| 改変 | 〇 |
| 配布 | 〇 |
| 特許使用 | 〇 |
| 私的使用 | 〇 |
Gradioの使い方
ここからは早速、PythonにおけるGradioの使い方をお見せしていきます。まずは、Gradioを動かすのに欠かせない環境から詳しくみていきましょう!
推奨環境
Gradioが要求する環境は至ってシンプル。下記のとおり、Gradio以外の特別なライブラリやパッケージは不要です。
- Python 3.10以上
- 「Gradio」そのもの
そして、Gradioをインストールする方法は……
pip install gradio以上を実行するだけとなっています。
Gradioの設定項目について
ここでは、Gradioを使ったWeb UIの組み方を軽くお伝えします。
まず、Gradioのインポートについてですが、下記のとおり「gr」とするのが一般的です。
import gradio as grそして、肝心のコードの書き方・Web UIの設定項目は下表のとおりとなっています。
| 設定項目 | コードの書き方 | 詳細 |
|---|---|---|
| Interface | gr.Interface(fn=実行する関数, inputs=入力のメディアの種類, outputs=出力のメディアの種類,examples=入力例のメディアの種類) | GUIの大枠が実装できるメディアの種類は”text” / “button” / “radio” / “image” / “video” / “file” / “slider”…etc.またはリストが使用可 |
| Interface(画像入力時) | gr.Interface(fn=実行する関数, inputs=image, outputs=出力のメディアの種類) | デフォルトではnumpy.arrayに変換type=”pil”でPIL.Image、type=”filepath”でファイルパスに変換することも可 |
| Blocks | with gr.Blocks() as blocks: button = button.click(fn=実行する関数, inputs=入力のメディアの種類, outputs=出力のメディアの種類) | Interfaceよりも複雑な画面構成が作れる |
| Tab / Row / Col | with gr.Tab():with gr.Row():with gr.Column(): | Tabでタブ分割、Rowで横並び、Colで縦並びのレイアウトが指定可入れ子にすることでかなり複雑な画面も作れる |
| IOComponent | gr.Dropdown()gr.Number()gr.Textbox()gr.Image()gr.Audio() | データ型を指定・継承できる(例:テキストボックスに数字を入れてもstr型にならない) |
| Click | 任意のButton.click() | ボタンがクリックされると関数が実行される |
| Change | 任意のTextboxまたはNumber.change() | 入力時に関数が作動 |
| Error | gr.Error(“error message”) | エラーメッセージをポップアップ表示できる |
| Flag | なし | 入出力の挙動を記録できるボタン |
| Update | return gr.update() | 入力内容に応じてUI側が更新できる |
| Session state | gr.State() | セッション内共通の状態変数が作成・初期化できる |
| launch()メソッド | 任意のインタフェース.launch() | Webアプリケーションサーバが起動する |
| launch()メソッド (認証画面ありの場合) | 任意のインタフェース.launch(auth=bool値) | パスワードを認証してbool値(True / False)で返す関数との組み合わせでログイン画面が作れる |
| Queueing | 任意のインタフェース.queue(concurrency_count=最大数) | 同時リクエスト数が制限できる(デフォルトは1回) |
| API | 設定時はapi_name=”任意の名前”使用時はapi_name=”/任意の名前” | WebページではなくAPIとして使いたい場合はこちら |
次項から、実践を交えて詳しいWeb UIの組み方をみていきましょう!


GradioでAIツールを作ってみた
ここからは、実際にAIツールのWeb UIを作りながら、Gradioの使い方を詳しくお伝えしていきます。
今回作っていくのは……
以上の4つ。全てGoogle Colaboratory(Colab)上でプログラミングを行います。
それではまず、物体検出AIツールの作例から詳しくみていきましょう!
物体検出AIツール
ここでは、画像中の物体名&位置を特定してくれるAIモデル「YOLO」をGradioと組み合わせて、物体検出AIツールを作っていきます。
手始めに以下をColab上で実行して、Gradioを環境にインストールしましょう!
!pip install gradioこちらを実行すると……
以上のとおり、Gradioのパッケージがインストールされます。
続いては、YOLOで入力画像中の物体名と位置を特定して、OpenCV(cv2)で結果をバウンディングボックス付きの画像として出力するまでの流れを作っていきます。こちらは……
!pip install ultralytics
#YOLOv10-Nをロード
from ultralytics import YOLO
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
#YOLOの一連コードを関数化
def detect_objects_and_visualize(image: np.array):
cv2.imwrite('data.jpg', image)
model = YOLO("yolov10n.pt")
results = model('data.jpg')
for r in results:
boxes = r.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(image, f"{r.names[int(box.cls.item())]}", (int(x1), int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0,255,0), 2)
cv2.putText(image, f"{box.conf}", (int(x1)+300, int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0,255,0), 2)
return image以上のとおり関数としてまとめました。
最後に、GradioのInterfaceを使って、上記関数のためのWeb UIを作っていきましょう。といっても、方法は簡単で……
import gradio as gr
yolo_ui=gr.Interface(fn=detect_objects_and_visualize, inputs="image", outputs="image")
yolo_ui.launch()このように、関数と入出力の形式を指定するだけでOK!実行やキャンセルに欠かせないボタンは、Gradio側が勝手に用意してくれます。
それでは、一連のソースコードを実行してみましょう!気になる結果は……
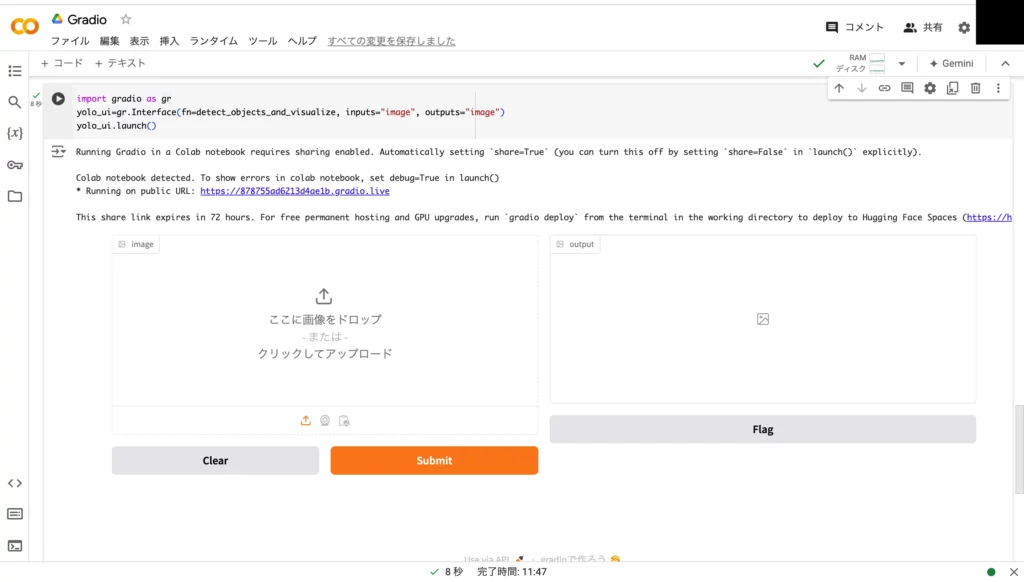
以上のとおりで、画像の入出力欄と各種ボタンの揃ったUIが出来上がりました。ここからさらに、「* Running on public URL:」をクリックすると、下記の専用画面が表示されます。
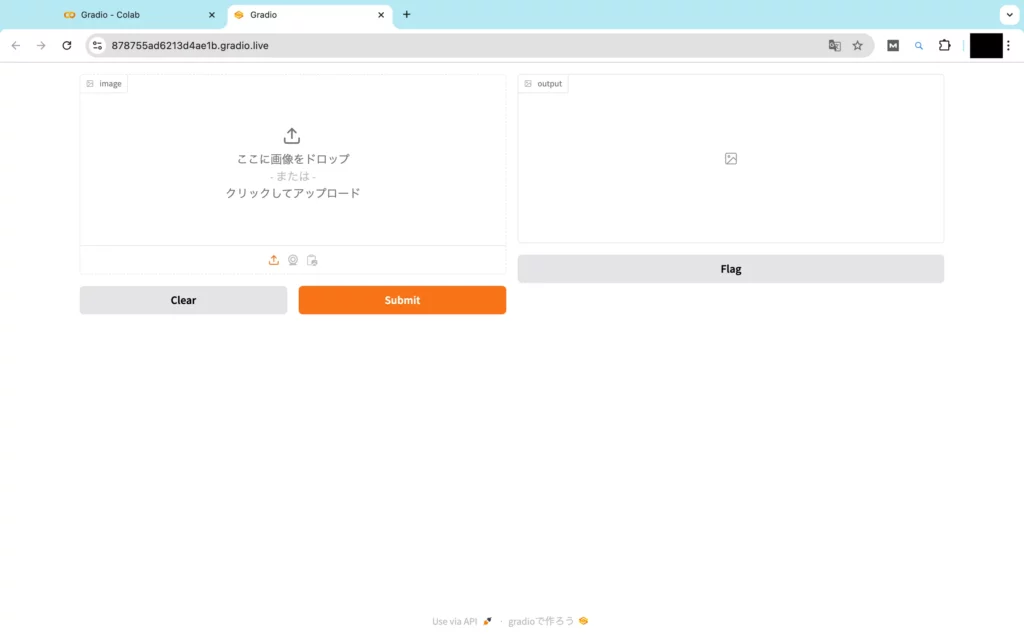
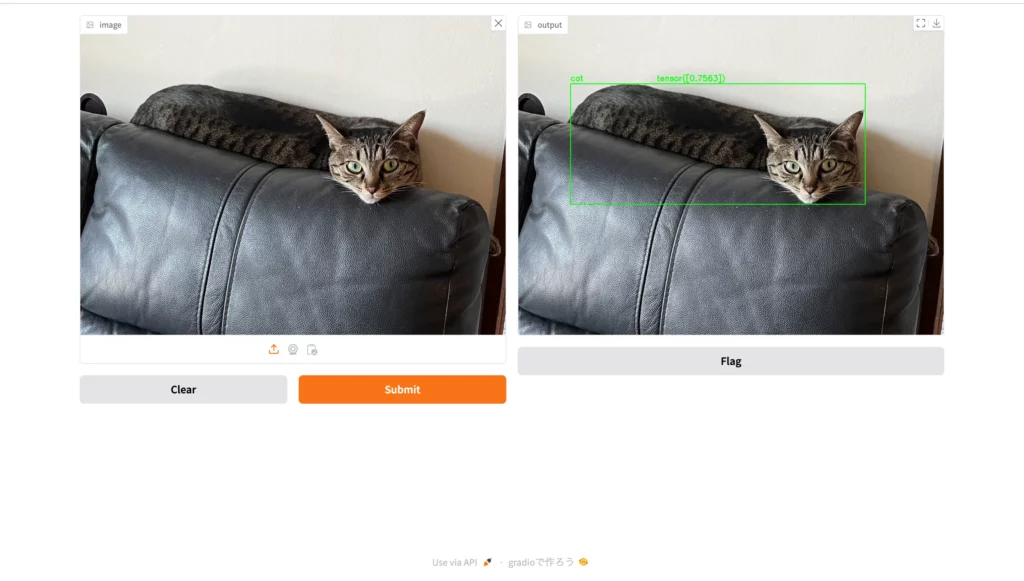
それでは、このWeb UIに画像をアップロードしてみて、動作確認を行なっていきましょう!今回は、ソファーの上に横たわる猫の画像を……
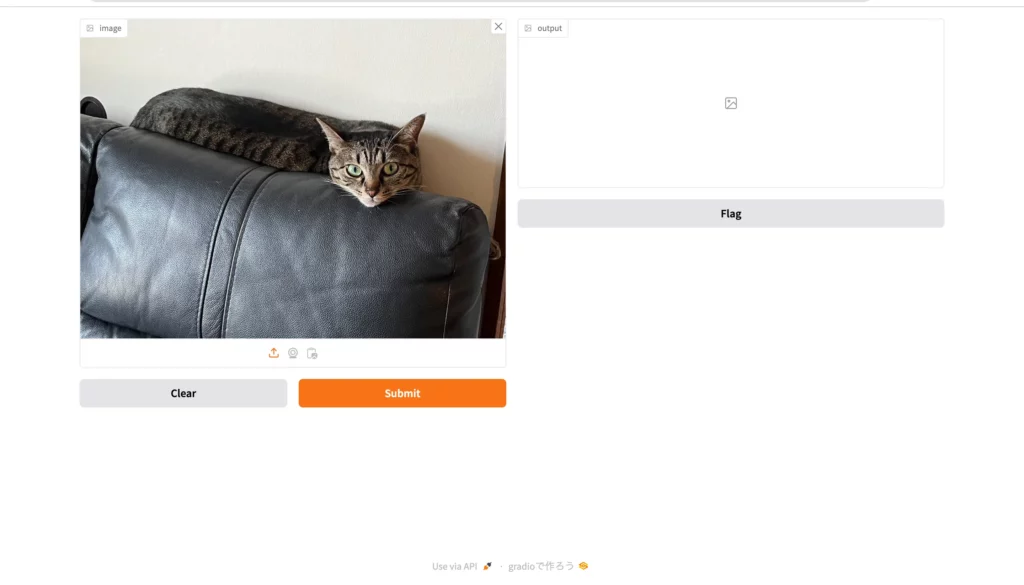
以上のとおりアップロードします。
ここからオレンジ色のボタン「Submit」をクリックすると……
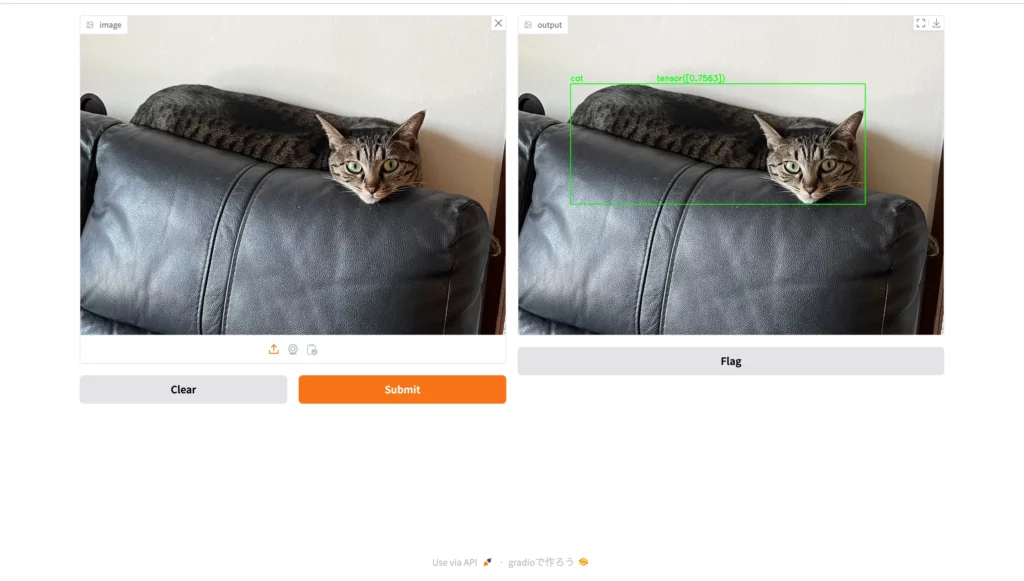
お見事です!画像中の猫を囲うようにして、バウンディングボックスと名前が表示されました。
なお、YOLOについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

画像生成AIツール
続いては、画像生成AI「OpenDalle」用のWeb UIもGradioで作ってみます。
手始めに、OpenDalleによる画像生成の流れを下記のとおり関数化してしまいましょう!
!pip install diffusers
!pip install accelerate
#画像生成モデルの用意
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained('dataautogpt3/OpenDalle', torch_dtype=torch.float16).to('cuda')
#画像生成の関数化
def gen_img(text: str):
image = pipe(text).images[0]
return image次に、GradioによるWeb UIの組み立てなのですが、今回はBlocksを使って細かく作り込んでいきます。ソースコードとしては……
import gradio as gr
with gr.Blocks() as jap_img_gen:
input = gr.Textbox(label="英語のプロンプト")
output = gr.Image(label="Output Box")
button = gr.Button("画像を生成する")
button.click(fn=gen_img, inputs=input, outputs=output)
jap_img_gen.launch()以上のとおり。プロンプト入力欄と実行用のボタンに説明文を添えてみました。
さて、ここまでのPythonコードをまとめて実行し、返ってきたURLにアクセスしてみると……
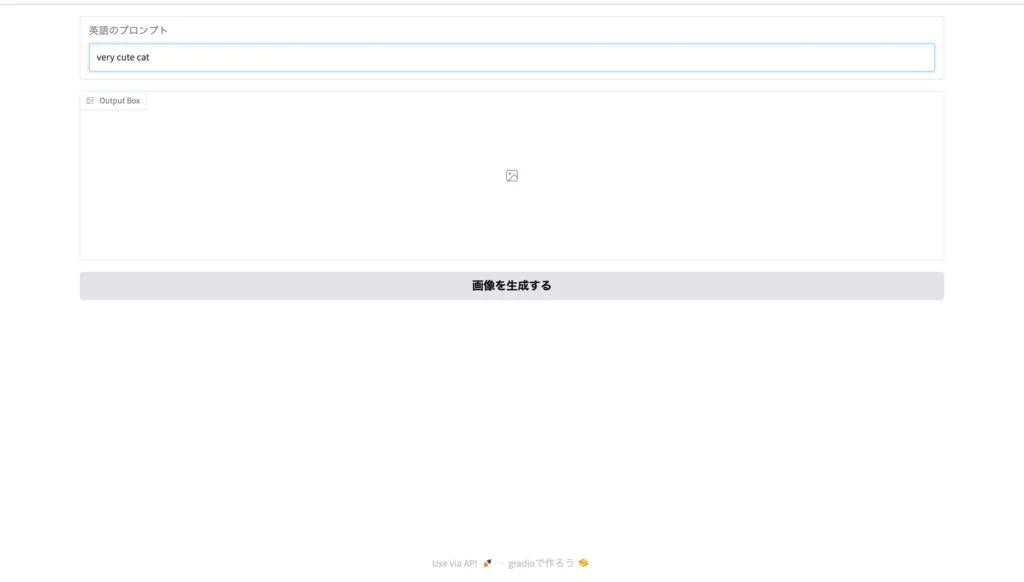
お見事です!指定したとおりのWeb UIが完成しています。
それでは試しに、プロンプト「very cute cat」を入力して、「画像を生成する」ボタンをクリックしてみましょう。
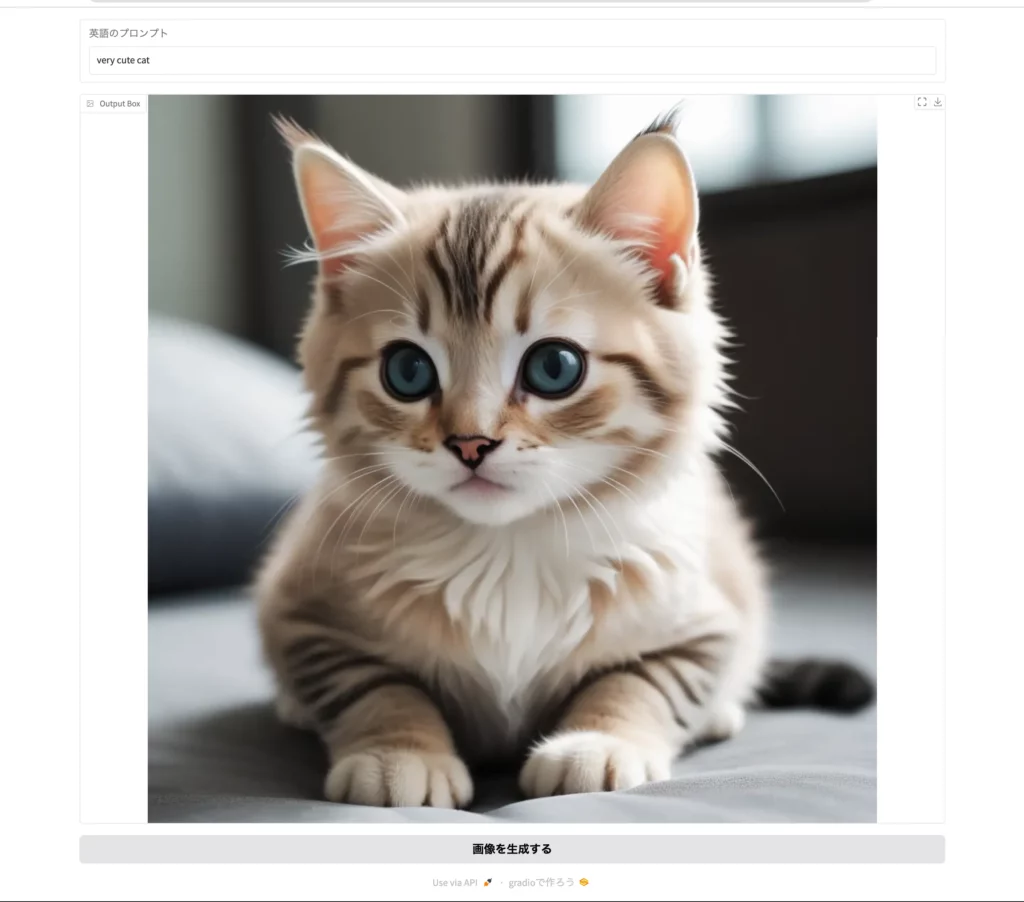
するとこのように、とても可愛い猫の画像が生成されて返ってきました。他の画像生成AIにも流用できますので、ぜひぜひお試しください!
なお、OpenDalleについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
翻訳文字起こしツール
今度は、音声認識AI「Whisper」のオープンソース版と無料でGPT-4が使える「GPT4FREE」を組み合わせて、完全無料の翻訳文字起こしツールを作ってみます。
まずは、WhisperとGPT4FREEによる処理を、例のごとく関数化していきましょう。今回は……
!pip install -U g4f
!pip install curl_cffi --upgrade
!pip install git+https://github.com/openai/whisper.git
#WhisperとGPT4FREEの用意
import whisper
import numpy as np
from g4f.client import Client
import time
client = Client()
model = whisper.load_model("medium")
#文字起こし・要約の流れを関数化
def transcribe(file):
moji = model.transcribe(file)["text"]
prompt = "続く文章を全文日本語訳・要約して出力だけを返してください。:"+moji
chat_completion = client.chat.completions.create(model="gpt-4o",messages=[{"role": "system", "content": "あなたは最強最高の翻訳家で入力を綺麗な日本語で返します。"},{"role": "user", "content": prompt}])
nyan=chat_completion.choices[0].message.content or ""
time.sleep(1)
return [moji,nyan]以上のとおり、「Whisperによる文字起こし原文」と「文字起こしをGPT4FREEで和訳&要約したもの」を出力するようにしました。
続いて、Gradioを使ってWeb UIも作ります。今回のソースコードは……
import gradio as gr
with gr.Blocks() as voice_script_summarise:
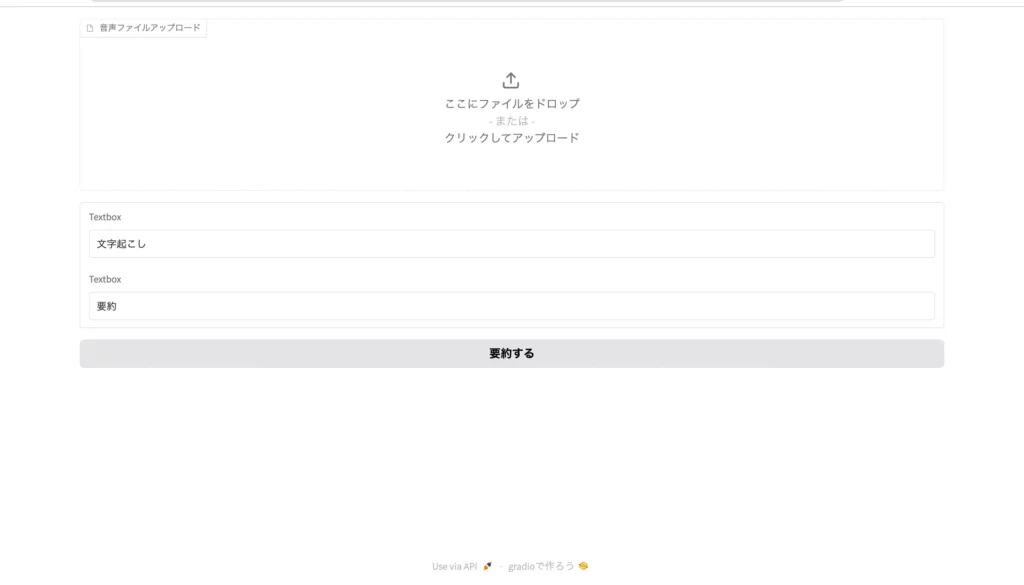
input = gr.File(label="音声ファイルアップロード")
output = [gr.Textbox("文字起こし"),gr.Textbox("要約")]
button = gr.Button("要約する")
button.click(fn=transcribe, inputs=input, outputs=output)
voice_script_summarise.launch()このようになっていて、アップロードした音声ファイルの文字起こし原文とその要約が返ってくる仕組みです。
それでは、上記を実行してWeb UIにアクセスしてみましょう。
すると見事、ファイルアップロードの欄・出力欄・実行ボタンの揃ったUIが完成しています。
今回はこちらに、以下の動画から抽出した音声ファイル(MP3)をアップロードしてみます。
すると……
このように、ファイルのアップロードが完了しました。続けて、「要約する」ボタンをクリックしてみると……
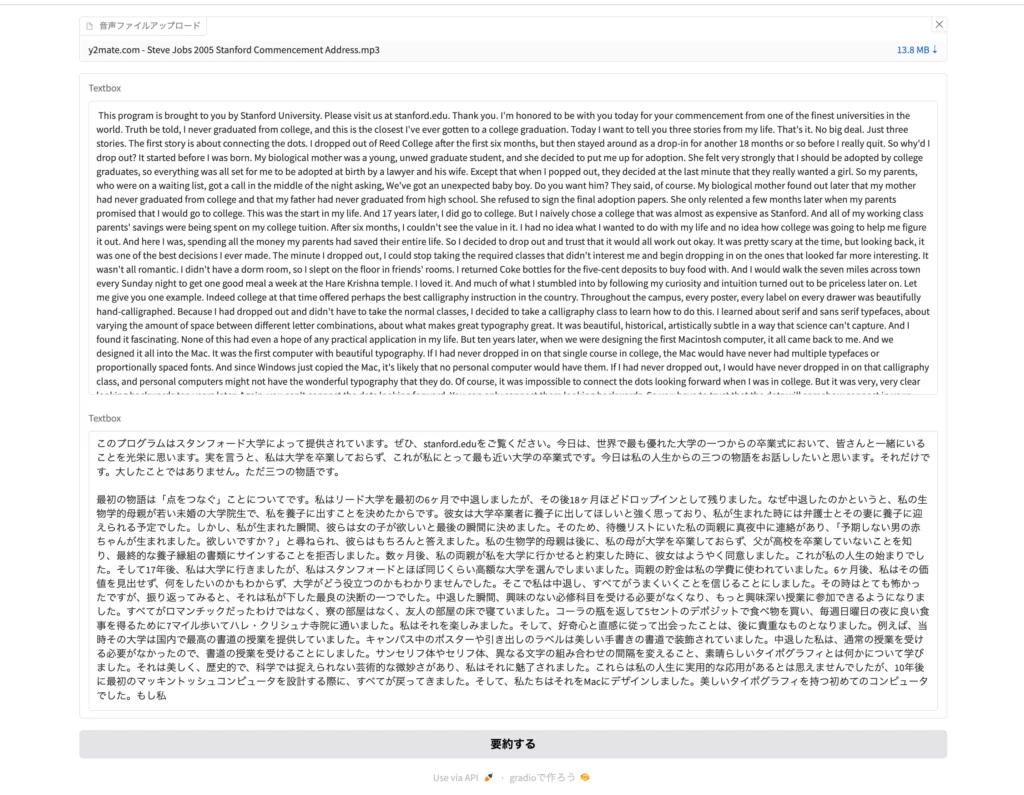
以上のとおり、スピーチ全文の文字起こしと要約が返ってきます。
なお、Whisperについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

RAG搭載のチャットボット
最後に、社内データについての回答提供もできる、RAG(Retrieval Augmented Generation)搭載のチャットボットを作ってみましょう。
今回実際に作っていくのは、当メディアの「生成AIずかん」全記事をマスターしたチャットボットになります。記事本文については、あらかじめスクレイピングして前処理を行なったものをテキストファイル「WEEL_Zenkiji.txt」にまとめました。

そして、肝心のコードについては……
!pip install openai langchain chromadb tiktoken -U langchain-community
#APIキー入力
import os
os.environ["OPENAI_API_KEY"] = "任意のAPIキー"
#モジュールインポート
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI as LangChainOpenAI
from openai import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
%cd sample_data
#テキストをチャンクに分ける
loader = TextLoader("WEEL_Zenkiji.txt",encoding="utf-8")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
#ベクトル空間に埋め込む
embeddings = OpenAIEmbeddings(disallowed_special=())
docsearch = Chroma.from_documents(texts, embeddings)
chain_type_kwargs = {"verbose": True}
qa = RetrievalQA.from_chain_type(
llm=LangChainOpenAI(),
chain_type="stuff",
retriever=docsearch.as_retriever(),
verbose=True,
chain_type_kwargs=chain_type_kwargs,
)
#RAGあり・RAGなしの回答出力の関数化
def rag(text):
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=[
{"role": "system", "content": "あなたは最強最高のアシスタントです。"},
{"role": "user", "content": text},
],
temperature=0.2,
)
no_rag = response.choices[0]
yes_rag = qa.run(text)
return [no_rag, yes_rag]以上のとおりで、「RAGなしのGPT-3.5 Turbo」と「RAGありのGPT-3.5 Turbo」両方の回答が返ってくる関数を定義しています。
続いて、GradioによるWeb UIのソースコードは……
import gradio as gr
with gr.Blocks() as rag_chatbot:
with gr.Column():
with gr.Row():
input = gr.Textbox(label="質問を入力")
with gr.Column():
output = [gr.Textbox(label="RAGなしの回答"),gr.Textbox(label="RAGありの回答")]
button = gr.Button("回答を生成する")
button.click(fn=rag, inputs=input, outputs=output)
rag_chatbot.launch()以上のとおり。入力欄と出力欄が横並びになっていて、出力欄の中にRAGなしの回答とRAGありの回答が縦並びで表示されるUIを作りました。
では早速、ここまでのソースコードを実行して、Web UIのURLにアクセスしてみましょう!すると……
このように、RAGの効果を確認しやすいUIが表示されます。試しに、下記のプロンプトを入力してみると……
ChatGPTの有料モデルGPT-4を無料で使えるツールについて教えて。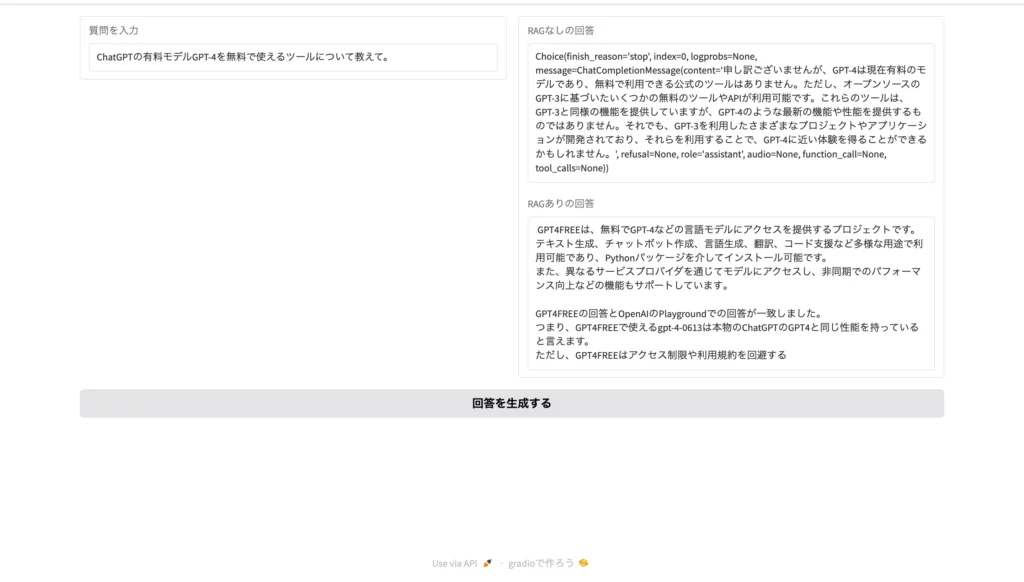
お見事です!RAGの有無で回答が大きく変わっていますね。
なお、ChatGPT APIを使ったRAGチャットボットについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Gradioを使う際の注意点
前述の通り、Gradioはオープンソースとなっており非常に使い勝手がいい反面、注意しなければいけない点があります。
セキュリティについて
Gradioは設定によっては自動的に一時的なURLでアプリが外部に公開されます。不用意に公開してしまうと第3者からアクセスされてしまう可能性があるため注意が必要です。特に、外部とやり取りが発生するアプリでは機密データなどの取り扱いには気をつけましょう。
また、Gradio自体に認証機能が実装されていないため複数人でアクセスするようなケースでは認証機能を実装することを検討してください。
パフォーマンスについて
Gradioは簡単にデモを作成することが可能ですが、あくまでもシンプルにデモを作ることを目的とされています。
大量のリクエストや大規模なデータ処理には向いていないため、自前の環境で利用する場合はリソースに注意してください。
Gradioについてよくある質問
「Gradio」なら、AIツールのデモが簡単に作れる
当記事では、AIツール用の簡易版Web UIが作れるPythonライブラリ「Gradio」について解説しました。以下にてもう一度、Gradioの魅力を振り返っていきましょう!
- 「pip install gradio」だけで使えて、その他ライブラリやパッケージは不要
- テキストはもちろん、画像・動画・音声・ファイル…etc.の入出力にも対応
- オープンソースのため、著作権・料金フリーで利用可能
- JavaScript & CSSの知識なしでデモ用のWebページが作成可
- 作ったデモはHugging Faceで永久的に公開可(サーバー立て不要)
Gradioなら、画像生成AIやチャットボット用のUIが簡単に作れます。UIの使い勝手も抜群ですので、AIツールを自作したい方はぜひぜひ、お試しください!

最後に
いかがだったでしょうか?
「Gradio」を使えば、専門知識がなくても簡単にAIツールを公開できます。自社のAI技術を素早くデモンストレーションする手段を探している企業にとって、非常に有用なツールです。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。