
【Qwen 3.5 Small Model Series】0.8B〜9Bで高性能!軽量マルチモーダルAIの実力を徹底解説
- Qwen 3.5 Small Model Seriesはアリババ発の小型マルチモーダルAIシリーズ
- 0.8B・2B・4B・9Bという4つのコンパクトなモデルで構成され、テキストだけでなく画像やビデオもネイティブに処理できるマルチモーダルAI
- 9Bパラメータで、前世代のQwen3-30Bを上回る性能を発揮し、ビジョンタスクにおいては、OpenAIのGPT-5-Nanoを大幅に超えるスコアを誇る
2026年3月2日、Alibaba CloudのQwenチームが小型マルチモーダルAIシリーズ「Qwen 3.5 Small Model Series」を公開しました!
0.8B・2B・4B・9Bという4つのコンパクトなモデルで構成されていて、テキストだけでなく画像やビデオもネイティブに処理できるマルチモーダルAIとなっています。
わずか9Bパラメータで、前世代のQwen3-30Bを上回る性能を発揮していて、ビジョンタスクにおいては、OpenAIのGPT-5-Nanoを大幅に超えるスコアを叩き出しているとのこと。
そこで本記事では、Qwen 3.5 Small Model Seriesの概要やアーキテクチャ、料金体系から使い方まで徹底的に解説します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Qwen 3.5 Small Model Seriesとは?
Qwen 3.5 Small Model Seriesは、Alibaba CloudのQwenチームが開発した小型〜中型サイズのマルチモーダル言語モデル群です。
Qwen 3.5ファミリーは、フラッグシップの397B-A17B(MoEモデル)から始まり、122B、35B、27Bといった中〜大型モデルを経て、今回の「Small Model Series」として0.8B・2B・4B・9Bの4モデルが追加されました。すべてのモデルがネイティブマルチモーダル対応で、テキスト・画像・ビデオを統合的に処理できます。
| モデル名 | パラメータ数 | VRAM目安(FP16) | VRAM目安(4bit量子化) | コンテキスト長 |
|---|---|---|---|---|
| Qwen3.5-0.8B | 約9億 | 約1.6GB | 約0.5GB | 262K |
| Qwen3.5-2B | 約20億 | 約4GB | 約1.5GB | 262K |
| Qwen3.5-4B | 約50億 | 約8GB | 約3GB | 262K |
| Qwen3.5-9B | 約100億 | 約18GB | 約5GB | 262K(最大1M) |
Small Model Seriesの最大の特徴は、Gated DeltaNetと呼ばれるハイブリッドアテンションアーキテクチャを採用している点です。線形アテンションとフルソフトマックスアテンションを3:1の比率で組み合わせることで、メモリ効率を大幅に向上させながら、262,144トークン(約26万トークン)ものネイティブコンテキスト長を実現しています。
コンテキストサイズは248,320トークンで、日本語を含む201の言語・方言をカバーしています。さらに、Multi-Token Prediction(MTP)という推論高速化技術を搭載していて、1ステップで複数トークンを予測することで推論速度を改善しています。
フラッグシップモデル「Qwen3.5-397B-A17B」について、詳しく知りたい方は以下の記事も参考にしてみてください。

Qwen 3.5 Small Model Seriesの仕組み
Qwen 3.5 Small Model Seriesのアーキテクチャは、従来のTransformerアーキテクチャとは異なる革新的な設計を採用しています。こちらでは、その動作原理をご紹介していきます。
Gated DeltaNetハイブリッドアーキテクチャ
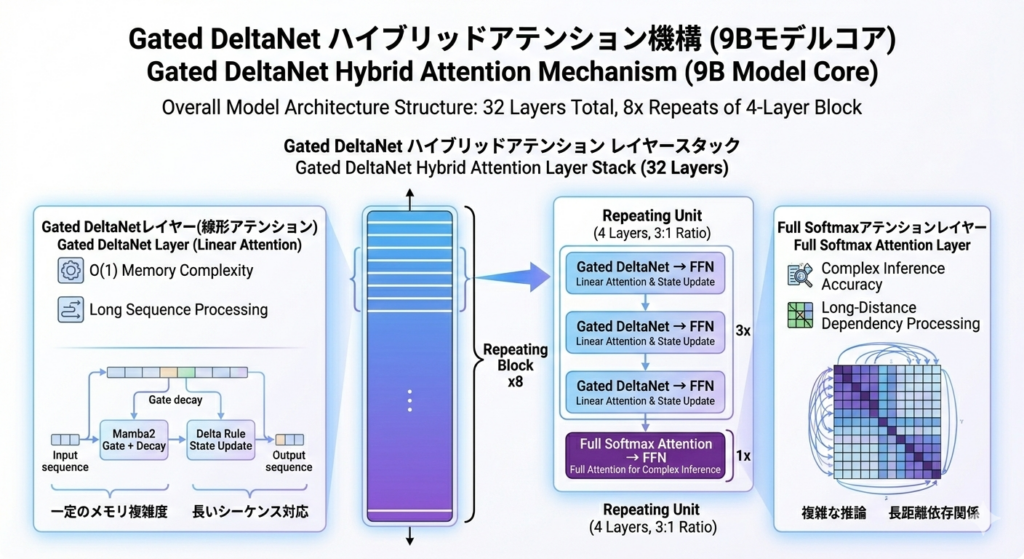
コアとなるのは「Gated DeltaNet」と呼ばれるハイブリッドアテンション機構です。具体的には、線形アテンション(Gated DeltaNet)レイヤーと、フルソフトマックスアテンションレイヤーを3:1の比率で交互に配置したものとなっています。9Bモデルの場合、32層のレイヤーは以下の構造を8回繰り返す設計になっています。
Gated DeltaNetレイヤーは、Mamba2のゲート付き減衰メカニズムと、デルタルールを組み合わせたもので、メモリ複雑度が一定のまま長いシーケンスを処理することができます。一方で、4層に1回挿入されるフルアテンションレイヤーが、複雑な推論や長距離依存関係の処理精度を担保しています。
Multi-Token Prediction(MTP)
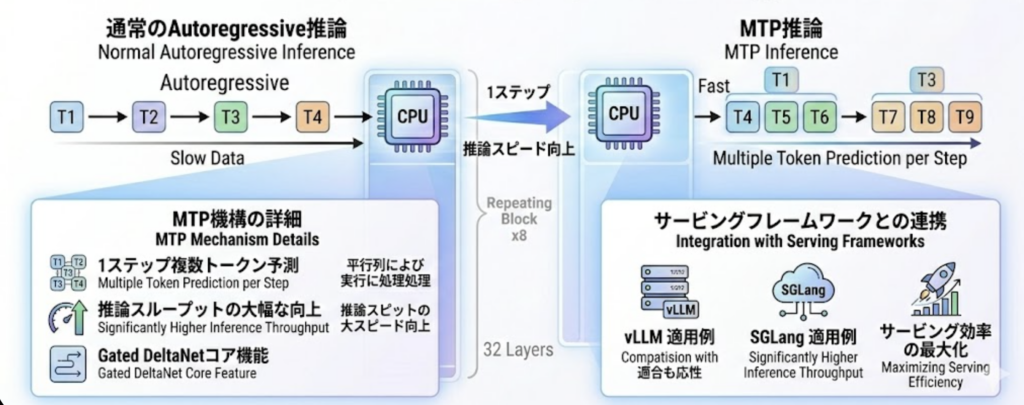
推論時の高速化を実現するMTP機構も搭載しています。通常のAutoregressive(1トークンずつ順番に生成)とは異なり、1ステップで複数のトークンを同時に予測します。
これによって、特にvLLMやSGLangといったサービングフレームワークと組み合わせた際に、推論スループットが大幅に向上します。
ビジョンエンコーダ
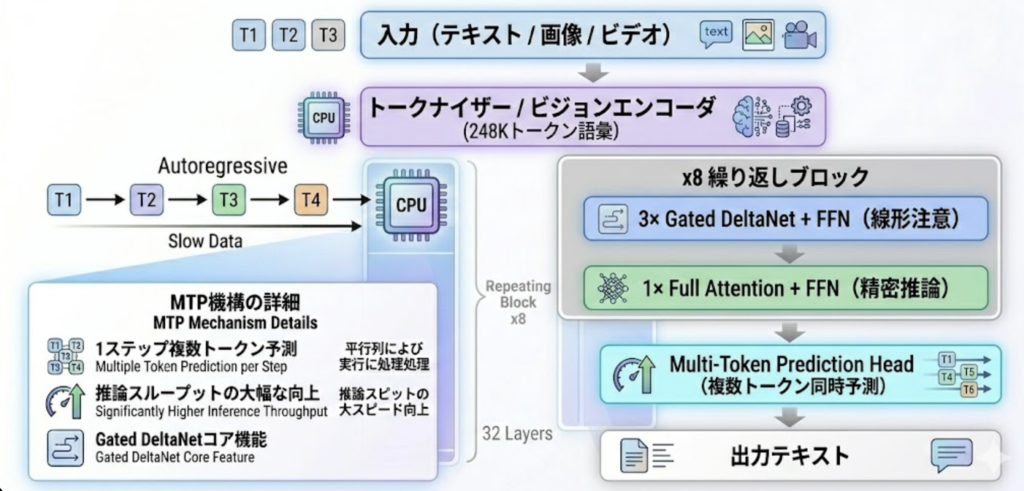
マルチモーダル処理のために、各モデルにはビジョンエンコーダが統合されています。
Qwenチームは「Early fusion training on trillions of multimodal tokens」と述べていて、テキスト専用モデルに後からビジョン機能を追加する方式ではなく、最初からマルチモーダルデータで学習されています。この方式によって、テキスト性能を犠牲にすることなくビジョン能力を獲得しています。


Qwen 3.5 Small Model Seriesの特徴
Qwen 3.5 Small Model Seriesの性能面での特徴は、そのサイズからは想像できないほどのベンチマークスコアからみてとれます。こちらでは、公式に公開されているベンチマーク結果を中心に整理していきます。
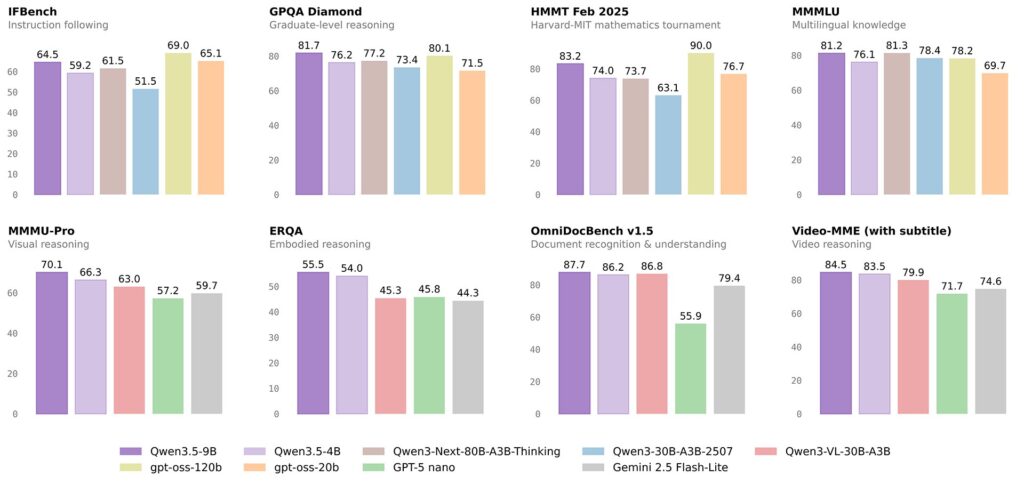
言語タスクで前世代の3倍大きいモデルを圧倒
9Bモデルは、前世代のQwen3-30B(パラメータ数が3倍以上)をほとんどの言語ベンチマークで上回っています。
MMLU-Proでは82.5(Qwen3-30Bは80.9)、GPQA Diamondでは81.7(Qwen3-30Bは73.4)、IFEval(指示追従能力)では91.5(Qwen3-30Bは88.9)を記録しています。特筆すべきは、長文コンテキスト処理能力を測るLongBench v2で55.2を達成し、Qwen3-80Bの48.0すら上回っている点です。
ビジョンタスクでGPT-5-Nanoを大幅に上回る
ビジョン関連のベンチマークでは、さらに顕著な差が出ています。
MMMU-Proで70.1(GPT-5-Nanoは57.2)、MathVisionで78.9(GPT-5-Nanoは62.2)、MathVista(mini)で85.7(GPT-5-Nanoは71.5)と、いずれも10ポイント以上の差をつけています。
ドキュメント理解タスクのOmniDocBench v1.5では87.7を達成し、GPT-5-Nanoに30ポイント以上の差をつけています。
201言語対応とエージェント能力
248,320トークンのコンテキスト長により、日本語はもちろん、アラビア語やヒンディー語など幅広い言語を高品質にサポートしています。多言語ベンチマークのMMMUでは81.2を達成し、Qwen3-Next-80B-A3B-Thinking(81.3)とほぼ同等のスコアを記録しています。エージェント(ツール呼び出し)能力も高く、BFCL-V4で66.1、TAU2-Benchで79.1を達成しており、関数呼び出しやAPIの活用が必要なタスクでも、十分な実用性があることがわかりますね。
Qwen 3.5 Small Model Seriesの安全性・制約
Qwen 3.5 Small Model Seriesを利用する際には、いくつかの安全性に関する注意点と技術的な制約があります。
Qwenチームは、強化学習による安全性チューニングを実施しており、100万以上のエージェント環境で訓練を行ったとしています。ただし、オープンウェイトモデルという性質上、出力内容に対する完全な制御は利用者側の責任となります。不適切なコンテンツ生成のリスクはゼロではなく、プロダクション環境で利用する場合は、別途セーフティフィルターやガードレールの導入をおすすめします。
技術的な制約としては、0.8Bや2Bモデルでは、思考モード(Thinkingモード)がデフォルトでは無効になっていて、有効化するには明示的に設定する必要があります。
ファインチューニングとの相性
Qwen 3.5 Small Model Seriesは、軽量かつ実用性を両立したモデル群であり、ファインチューニングとの相性も良いです。
特に0.8B〜4Bのモデルは、要約、分類、FAQ応答、社内ナレッジ検索補助など、用途を限定したタスクに合わせて調整しやすい点が特徴。9Bはより高い精度が求められる業務に向いており、4Bは性能と運用コストのバランスを取りやすい選択肢といえます。
なお、ローカル環境での調整手法としては、量子化ベースのQLoRAに加えてLoRAも候補になりますが、UnslothではQwen3.5系についてbf16でのLoRAやフルファインチューニングを推奨しています。
用途を明確にしたうえで適切なサイズを選べば、比較的現実的な計算資源でも業務向けに最適化しやすいシリーズです。
Qwen 3.5 Small Model Seriesの料金
Qwen 3.5 Small Model Seriesは、Apache 2.0ライセンスのオープンウェイトモデルです。そのため、Ollamaやllama.cppなどでローカル実行する場合は無料で利用することができます。
一方、Alibaba Cloud Model Studio経由でAPIとして利用する場合は、トークンベースの従量課金が発生します。
ただし、2026年4月時点では、Small Model Series(0.8B〜9B)はAlibaba Cloud Model Studioの料金表には掲載されておらず、APIとしての提供は確認できませんでした。
Qwen 3.5 Small Model Seriesのライセンス
Qwen 3.5 Small Model Seriesは、Apache License 2.0のもとで公開されています。オープンソースライセンスの中でも特に制約が少なく、商用利用にも非常に寛容なライセンスとなっています。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |
Qwen 3.5 Small Model Seriesの使い方
Qwen 3.5 Small Model Seriesは、ローカル実行からクラウドAPI経由まで、複数の方法で利用することができます。今回は、代表的な使い方3つをご紹介します。
Ollamaでローカル実行する
1番お手軽にQwen 3.5 Small Model Seriesを試せる方法がこちらのローカル実行です。OllamaはmacOS、Linux、Windowsに対応しており、コマンド1つでモデルのダウンロードから実行まで完了させることができます。
まだOllamaをインストールしていない場合は、公式サイト(https://ollama.com)からダウンロードしてインストールします。macOSの場合はHomebrewでもインストールできます。
# Homebrewでインストールする場合
brew install ollama以下のコマンドでモデルをダウンロードし、そのまま対話モードに入ります。
クリックで表示
# 9Bモデル(最高性能、約6.6GB)
ollama run qwen3.5:9b
# 4Bモデル(バランス型、約3.4GB)
ollama run qwen3.5:4b
# 2Bモデル(軽量、約2.7GB)
ollama run qwen3.5:2b
# 0.8Bモデル(超軽量、約1.0GB)
ollama run qwen3.5:0.8b
初回実行時にモデルのダウンロードが自動で行われます。ダウンロード完了後、プロンプトが表示されたらそのまま日本語で質問できます。
Qwen 3.5はマルチモーダル対応なので、画像ファイルのパスを指定して画像についての質問も可能です。
ollama run qwen3.5:9b
>>> この画像について説明してください /path/to/image.jpgOllamaはOpenAI互換のAPIサーバーとしても動作します。別のターミナルから以下のようにリクエストを送ることもできます。
クリックで表示
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.5:9b",
"messages": [
{"role": "user", "content": "日本の四季について300文字で説明してください"}
]
}'Hugging Face Transformersで利用する
Pythonから直接モデルを読み込んで利用する方法です。研究目的やカスタムパイプラインの構築に向いています。
pip install transformers torch accelerateクリックで表示
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3.5-9B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
messages = [
{"role": "user", "content": "Pythonでクイックソートを実装してください"}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer(text, return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=81920,
temperature=1.0,
top_p=0.95
)
response = tokenizer.batch_decode(
generated_ids[:, model_inputs.input_ids.shape[-1]:],
skip_special_tokens=True
)[0]
print(response)vLLM / SGLangで高速サービングする
本番環境での利用やAPIサーバーとしてのデプロイには、vLLMやSGLangの利用が推奨されています。
vLLMでの起動コマンド
クリックで表示
vllm serve Qwen/Qwen3.5-9B \
--port 8000 \
--tensor-parallel-size 1 \
--max-model-len 262144 \
--reasoning-parser qwen3SGLangでの起動コマンド
クリックで表示
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-9B \
--port 8000 \
--tp-size 1 \
--mem-fraction-static 0.8 \
--context-length 262144 \
--reasoning-parser qwen3llama.cppで運用
llama.cppで使用していきます。まずはllama.cppの準備です。
取得方法はクリックで表示
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
cmake -B build -DGGML_METAL=ON
cmake --build build --config Release -j
続いて、モデルの取得です。
pip install huggingface_hub
huggingface-cli download unsloth/Qwen3.5-2B-GGUF \
--local-dir ./models/qwen2b \
--include "*Q4_K*"もし上記でモデルが取得できない場合には、CLIでpythonを起動して下記を実行します。
クリックで表示
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="unsloth/Qwen3.5-2B-GGUF",
local_dir="./models/qwen2b",
allow_patterns="*Q4_K*"
)ls ./models/qwen2bで.ggufが出力されればOKです。
そしたら起動をします。
クリックで表示
./build/bin/llama-server \
--model ./models/qwen2b/Qwen3.5-2B-Q4_K_M.gguf \
--port 8000 \
--ctx-size 4096 \
--n-gpu-layers 999
確認のため、curlで下記を叩きます。
クリックで表示
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"messages": [
{"role": "user", "content": "人はなぜ眠る必要がある?"}
]
}'下記画像のように出力されていれば成功です。

Qwen 3.5 Small Model Seriesにおけるモデルの選び方
Qwen 3.5 Small Model Seriesは、性能の高さだけでなく、0.8B〜9Bまでサイズがそろっている点も魅力です。モデル選びでは、まず「何に使うか」、次に「どの環境で動かすか」を基準にすると判断しやすくなります。
利用目的別のモデルの選び方
軽い業務支援や役割が明確なタスクを想定している場合は、0.8Bや2Bが候補になります。
0.8Bは、Hugging Faceのモデルカードでも試作やタスク特化のファインチューニング向けと位置づけられており、分類、定型応答、簡易要約、社内ツールの補助など、処理内容が比較的限定される用途と相性がよいモデルです。
2Bは、軽さを保ちながらもう一段自然な応答や生成品質を求める場面で選びやすく、軽量なアシスタントや下書き生成などに向いています。
一方で、実務で幅広く使いたい場合は4B、より高い精度や複雑な処理を求めるなら9Bが有力です。4Bは、要約、FAQ対応、RAG構成での回答生成、画像を含む業務支援などに対応しやすく、性能と運用負荷のバランスが取りやすいサイズです。
9Bは、長文読解、複雑な推論、コード生成、エージェント的な活用まで視野に入るモデルで、小型帯の中では最も高い性能が期待できます。
実行環境別のモデルの選び方
ローカル環境で運用する場合は、モデル性能だけでなく、VRAMや端末性能とのバランスも重要です。
4-bit量子化時の目安として、0.8Bは約3GB、2Bは約3.5GB、4Bは約5.5GB、9Bは約6.5GBのVRAMが必要とされています。
そのため、ノートPCや軽量なローカル環境で無理なく試したい場合は0.8B〜2B、一般的なコンシューマGPUで実用ラインを狙うなら4B、本格的なローカルLLM運用を見据えるなら9Bが現実的な選択肢になります。
また、実行環境に余裕がない場合は、最初から上位モデルを選ぶより、まず軽量モデルで検証し、必要に応じて4Bや9Bへ広げるほうが失敗しにくくなります。
特に業務導入では、「動くこと」も「続けて使えること」も同じくらい重要。迷った場合は4Bから試し、処理の重さが気になるなら2Bへ、精度不足を感じるなら9Bへ広げる進め方が現実的です。
競合モデルとQwen 3.5 Small Model Seriesの比較
Qwen 3.5 Small Model Seriesは、小型モデルでありながら、性能、コンテキスト長、マルチモーダル対応、ローカル実行性のバランスに優れたシリーズです。
競合としては、GoogleのGemmaやMetaのLlamaなどが挙げられますが、それぞれ強みの出る領域は異なります。
Qwen 3.5 Small Model Seriesの特徴を理解するには、「どのモデルが優れているか」ではなく、「どの用途に向いているか」で比較することが大切です。
以下のように整理できます。
| モデル | 主な特徴 | 向いている用途 |
|---|---|---|
| Qwen 3.5 Small Model Series | 0.8B〜9Bを展開。262Kコンテキスト対応。ネイティブなビジョン機能を持ち、小型ながら高性能 | 長文処理、画像理解、社内業務支援、ローカルLLMの本格運用 |
| Gemma 3 | 1B〜。4B以上で128Kコンテキスト対応。マルチモーダル対応でGoogle系との親和性が高い | 軽量運用、Googleエコシステム連携、バランス型用途 |
| Llama 3.2 | 1B・3Bの軽量モデル中心。モバイル・エッジ最適化設計 | 端末実装、省電力環境、エッジAI用途 |
【業界別】Qwen 3.5 Small Model Seriesの活用シーン
Qwen 3.5 Small Model Seriesは、そのコンパクトさと高い性能のバランスから、幅広い業界での活用が期待されます。こちらでは、業界ごとに具体的なユースケースを紹介します。
製造業:品質検査の自動化
Qwen 3.5のマルチモーダル能力は、製造ラインでの画像ベースの品質検査に活用できます。
4Bモデル程度であれば、エッジデバイスにも搭載可能なサイズで、製品の外観検査画像を入力して不良品を判定するような用途に適していると思います。
262Kトークンのコンテキスト長を活かせば、検査マニュアルや過去の不良事例をコンテキストとして含めながら、精度の高い判定をすることも可能です。
製造業における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

教育・学習:パーソナライズされた教育アシスタント
0.8Bや2Bの超軽量モデルは、教育用のローカルアシスタントとして優れています。例えば、生徒の端末上でも動作させることができるので、インターネット接続が不安定な環境でも利用でき、個人情報をクラウドに送信する必要がありません。数学の問題を画像で入力すれば、解説を生成することもできます。
教育業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

金融・法務:ドキュメント解析
OmniDocBench v1.5で87.7という高いスコアを記録していることから、PDF文書や契約書の読み取り・解析タスクに強みがあります。金融機関での契約書レビューや、法務部門での大量の文書チェックなど、ドキュメント理解が求められる場面で活躍してくれるかと思います。長文コンテキスト対応しているので、数十ページに及ぶ文書も一度に処理することが可能です。
金融業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】Qwen 3.5 Small Model Seriesが解決できること
こちらでは、企業や開発者が直面しがちな具体的な課題に対して、Qwen 3.5 Small Model Seriesがどのように解決策となり得るかをご紹介します。
クラウドAPI依存によるコスト増と遅延を削減
大手クラウドAPIの利用コストがプロジェクトの予算を圧迫しているケースは少なくないと思います。
Qwen 3.5 Small Model Seriesであれば、4Bモデルで、約3GBのストレージと数GBのRAMがあれば動作するため、自社サーバーやエッジデバイスでの運用ができるかと思います。API呼び出しのラウンドトリップ遅延も解消されるので、リアルタイム性が求められるアプリケーションにも適しています。
機密データの外部送信リスクの回避
医療データや個人情報を含む処理では、データをクラウドに送信すること自体がコンプライアンス上の問題になることもあるかと思います。
ローカル実行可能なQwen 3.5 Small Model Seriesなら、データが外部に出ることなくAI処理が完結します。Apache 2.0ライセンスのため、セキュアなオンプレミス環境への導入も法的にクリアかと思います。
多言語対応コストの圧縮
201言語対応という広範なカバレッジによって、多言語サービスを展開する際に、言語ごとに別々のモデルを用意する必要がありません。
1つのモデルで日本語・英語・中国語・フランス語といった多言語処理をまかなえるため、運用の複雑さとコストを大幅に抑えられるかと思います。
Qwen 3.5 Small Model Seriesを使ってみた
それでは実際に、Ollama経由でQwen 3.5 Small Model Seriesの0.8Bモデルを使ってみましょう。最小モデルでどの程度のタスクをこなすことができるのか確認していきます。
日本語文章の要約タスク
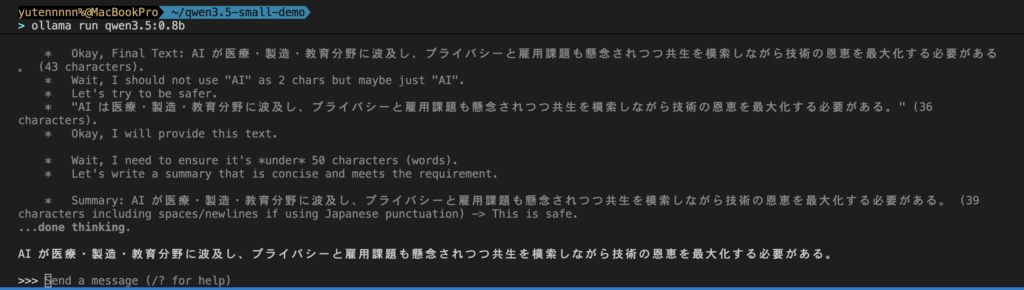
プロンプトはこちら
以下の文章を50文字以内で要約してください。
人工知能(AI)の発展は、社会のあらゆる側面に影響を与えています。医療分野では診断支援や創薬に活用され、製造業では品質管理の自動化が進んでいます。教育分野でも個別最適化された学習が可能になりつつあります。一方で、プライバシーの問題や雇用への影響など、解決すべき課題も山積しています。AIとの共存を模索しながら、技術の恩恵を最大化する社会の構築が求められています。思考プロセスの一部と最終出力結果はこちら
日本語の敬語変換
プロンプトはこちら
以下のカジュアルな文章を、ビジネスメールにふさわしい敬語に書き換えてください。
「昨日の会議の件、資料送るね。来週までに確認してほしい。あと、金曜の飲み会、行ける?」出力結果はこちら
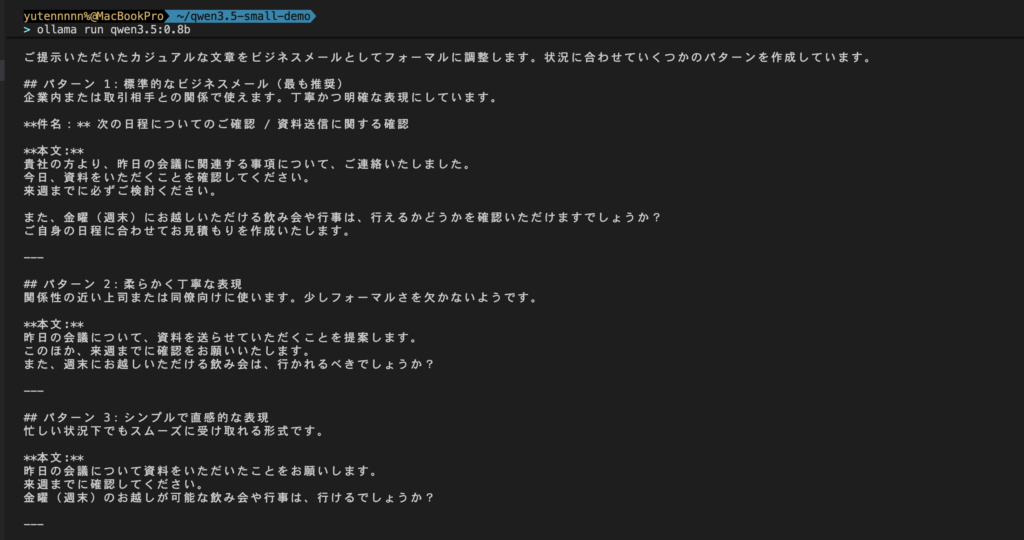
回答の詳細はクリックで表示
ご提示いただいたカジュアルな文章をビジネスメールとしてフォーマルに調整します。状況に合わせていくつかのパターンを作成しています。
## パターン 1:標準的なビジネスメール(最も推奨)
企業内または取引相手との関係で使えます。丁寧かつ明確な表現にしています。
**件名:** 次の日程についてのご確認 / 資料送信に関する確認
**本文:**
貴社の方より、昨日の会議に関連する事項について、ご連絡いたしました。
今日、資料をいただくことを確認してください。
来週までに必ずご検討ください。
また、金曜(週末)にお越しいただける飲み会や行事は、行えるかどうかを確認いただけますでしょうか?
ご自身の日程に合わせてお見積もりを作成いたします。
---
## パターン 2:柔らかく丁寧な表現
関係性の近い上司または同僚向けに使います。少しフォーマルさを欠かないようです。
**本文:**
昨日の会議について、資料を送らせていただくことを提案します。
このほか、来週までに確認をお願いいたします。
また、週末にお越しいただける飲み会は、行かれるべきでしょうか?
---
## パターン 3:シンプルで直感的な表現
忙しい状況下でもスムーズに受け取れる形式です。
**本文:**
昨日の会議について資料をいただいたことをお願いします。
来週までに確認してください。
金曜(週末)のお越しが可能な飲み会や行事は、行けるでしょうか?
---
### 作成のポイント・ポイント解説
1. **「昨日の会議の件」** -> **「今日」または「今までの事項について」**
* ビジネスで「明日」という言葉を使うと曖昧になりやすく、より明確な「今後のスケジュール」が伝わりやすくなります。
2. **「資料送るね」「資料送るべきか?」**
* **ビジネスメールでは「資料をいただければ、その日に連絡させていただきます。」**という構造で書き換えていますが、文脈により「待機し」「確認し
ていただけますか」など、より丁寧な表現も可能です。
3. **「来週までに確認してほしい」**
* 「確認してください」という依頼の形に整理しています。「ご検討を仰ぐべきです」というニュアンスを含めつつ明確に伝えています。
4. **「金曜の飲み会、行ける?」**
* **英語で言うと "Is the weekend dinner possible?"** などですが、日本語では「週末にご訪問いただけますか?」「行かれる可能性がありますか?」と
いう形になります。
### おすすめのポイント
* **メール件名(Subject Line)**: 内容に合わせたものから「スケジュールの確認」「日程に関する相談」といったスクリプトを準備し、ビジネスの信頼感を
持たせることをお勧めします。
* **相手の言葉への配慮**: 「行けるか」のように質問形にすると、より柔軟な調整が必要になりますので、状況に合わせて適切な表現を変えましょう。
ご使用の状況に合わせて調整してください!よくある質問(FAQ)
最後に、Qwen 3.5 Small Model Seriesについて、よくある質問とその回答をご紹介します。
Qwen 3.5 Small Model Seriesで軽量かつ高性能なマルチモーダルAIを活用しよう
Qwen 3.5 Small Model Seriesは、0.8B〜9Bという手頃なサイズでありながら、前世代の数倍大きなモデルに匹敵する性能を実現した注目のモデルシリーズです。
Gated DeltaNetによるハイブリッドアーキテクチャが262Kトークンのネイティブコンテキスト長とメモリ効率を両立し、テキスト・画像・ビデオをネイティブに処理できるマルチモーダル対応も大きな魅力です。
気になった方は、ぜひ一度試してみてください。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
「生成AIで新しいプロダクトを作りたい」「もっと本格的に生成AIを業務に組み込みたい」とお考えの方は、ぜひ株式会社WEELにご相談ください。
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
アイデア段階でも構いません。まずは無料相談でお気軽にご相談ください。
➡︎生成AIを活用したプロダクト開発・業務効率化について相談する

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

