
【Stable Video 4D】1つの動画からマルチアングルやビューを生成!
2024年7月25日にStability AIから新たなAIモデルが登場しました!
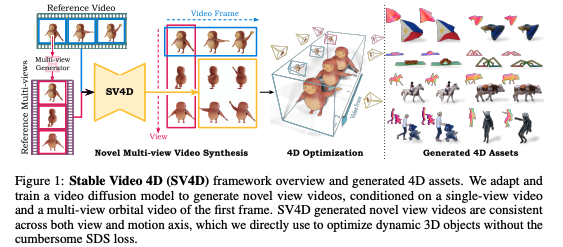
新たに登場したStable Video 4Dはこれまでにない画期的なAIモデル。1本の入力動画から8つの異なる角度/視点から新たな動画を生成、ユーザーが指定したカメラアングルで動画の作成が可能、1回の処理で5フレーム×8視点の動画を約40秒で生成という特徴があります!
これまでにないAIモデルであるため、Stable Video 4Dの発表からたった半日で、7万人以上の人々が興味を示しています。
本記事では、Stable Video 4Dを使って、実際にどのような動画を作成できるのかサンプルコードを踏まえながら解説をします。
最後まで読むことで、Stable Video 4Dをgoogle colaboratoryで使用できるようになるので、ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Stable Video 4Dの概要
Stable Video 4Dは2024年7月25日にStable AIが発表した最新のAIモデルです。これまでも動画を生成するAIモデルはありましたが、Stable Video 4Dはこれまでの動画生成AIとは異なります。
Stable Video 4Dは、ユーザーが希望する3Dカメラのポーズを指定するだけで、その視点に基づいた8つの新しい視点動画を生成します。これにより、被写体の多角的な視点を提供します。Stability AIは、このモデルが「動画内の被写体のダイナミックな3D表現を効率的に最適化する」ために使用できると説明しています。
Stable Video 4Dの特徴をまとめると次の3つです。
- 入力動画1本から8つの異なる角度/視点で動画を生成可能
- ユーザーが指定したカメラアングルで動画の作成
- 1回の処理で5フレーム×8視点の動画を約40秒で生成
また、Stable Video 4Dはこれまでの動画生成AIと比較して、より詳しく、入力動画を忠実に再現し、さまざまな角度や視点から一貫性のある動画を生成できます。
なお、Stability AIの音声生成AIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Stable Video 4Dの最先端技術
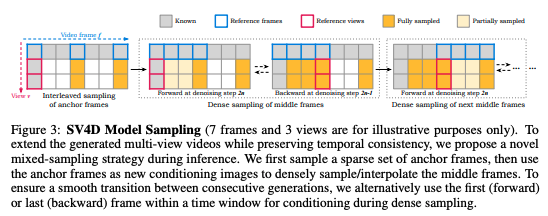
従来の手法では、動画の時間的変化とさまざまな視点/角度からの見え方を別々に処理をしていました。しかし、別々に処理をすることで、実際のオブジェクトの動きと視点/角度の変化の間に違和感が生じてしまいます。
しかし、動画の時間的変化と視点/角度の変化を同時に扱うことができるStable Video 4Dでは、単一の拡散モデルで同時に処理することで、従来の手法に比べてより自然な動きの動画を生成可能です。
さらに、従来の手法はスコア蒸留サンプリング(SDS:Score Distillation Sampling)損失に依存していました。
SDS損失を用いることで、2D拡散モデルで学習した事前確率を最適化によって4Dコンテンツに組み込むことが可能。しかし、SDS損失に基づく手法では、計算コストが高い・4Dコンテンツの生成に時間がかかってしまいます。
一方、Stable Video 4DではSDS損失を用いず、生成された動画から4Dを表現する最適化手法を用いているため、計算コストを抑えつつより高品質な4D動画の生成が可能になりました。
Stable Video 4Dの今後の課題
Stable Video 4Dのテクニカルレポートには今後の課題として以下の記載があります。
ObjaverseDy Dataset. Considering that there exists no large-scale training datasets with dynamic 3D objects, we curate a new 4D dataset from the existing Objeverse dataset [9, 8], a massive dataset with annotated 3D objects. Objaverse includes animated 3D objects, however, several of these animated 3D objects are not suitable for training due to having too few animated frames or insufficient motion. In addition, in the rendering stage, the common rendering and sampling setting may cause some issues. For example, dynamic objects may be out of the image if the camera distance is fixed because they have global motion; the motion of objects may be too fast or too slow if the temporal sampling step is fixed.
SV4D: Dynamic 3D Content Generation with
和訳:
動的な3Dオブジェクトを含む大規模な学習データセットが存在しないことを考慮し、既存のObjeverseデータセット[9, 8]から新しい4Dデータセットを作成する。 Objeverseにはアニメーションする3Dオブジェクトが含まれているが、これらのアニメーションする3Dオブジェクトのいくつかは、アニメーションフレームが少なすぎたり、動きが不十分であったりするため、学習には適していない。 また、レンダリングの段階で、一般的なレンダリングとサンプリングの設定では、いくつかの問題が発生する可能性があります。 例えば、動的オブジェクトはグローバルな動きをするため、カメラ距離を固定すると画像から外れてしまう可能性があります。また、時間サンプリングステップを固定すると、オブジェクトの動きが速すぎたり遅すぎたりする可能性があります。
Multi-Frame and Multi-View Consistency
つまり、Stable Video 4Dでは、大規模な4Dデータセットがないことが、堅牢な生成モデルのトレーニングにおける課題としています。Stable Video 4Dの将来の課題としては、モデルのトレーニングに使用でるより大規模で多様な4Dデータセットのキュレーションと作成に焦点を当てることができるでしょう。
Stable Video 4Dのライセンス
Stable Video 4DのライセンスはCommunity Licenseです。
Community Licenseは年間収入が100万ドル未満の個人や組織は研究用、非商用利用、商用利用が可能です。
もし年間収入が100万ドルを超える場合、商用利用にはStabolity AIからエンタープライズライセンスの取得が必要。
また、Stability AIのライセンスは3つあります。
- 非商用ライセンス:個人開発者や研究者向けライセンスで無料
- コミュニティライセンス:年間収入が100万ドル未満の個人や組織向けで無料
- エンタープライズライセンス:年間収入が100万ドルを超える企業向けでカスタム価格
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | 不明(明記なし) |
| 配布 | 不明(明記なし) |
| 特許使用 | 不明(明記なし) |
| 私的使用 | 不明(明記なし) |
改変や配布、特許使用などについては記載がありませんでしたので、今後の更新が待たれます。
なお、Stability AIの動画生成AIについて詳しく知りたい方は、下記の記事を合わせてご覧ください。

Stable Video 4Dの使い方
実際にgoogle colaboratoryでStable Video 4Dを使っていきます。
Stable Video 4Dを使用するためには、Hugging Faceで個人情報の登録をします。
Hugging Faceにアクセスするとログインを求められるので、利用したことがある方はログインを、初めて使う方はサインアップをしましょう。
また、実装の際には、Stable Video 3Dのダウンロードも行うため、Stable Video 3Dでも個人情報を登録しておく必要があります。
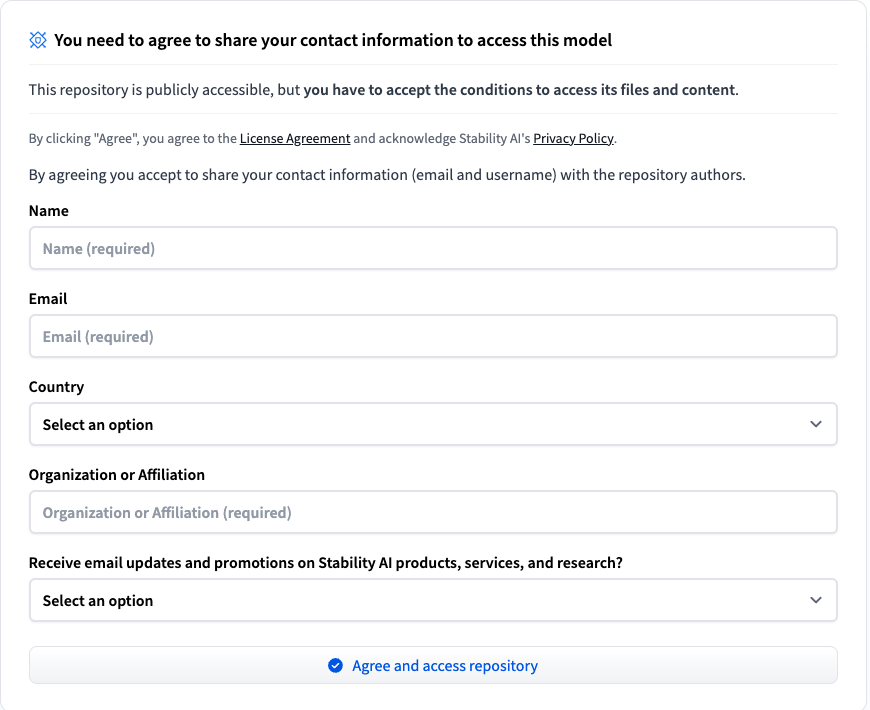
Hugging Faceでアクセストークンを取得
Stable Video 4DおよびStable Video 3Dを使うためには、アクセストークンを取得してコードの中で認証を受ける必要があります。Stable Video 4Dのページから向かって右上のアカウントマークをクリック。続いて「Settings」をクリックします。
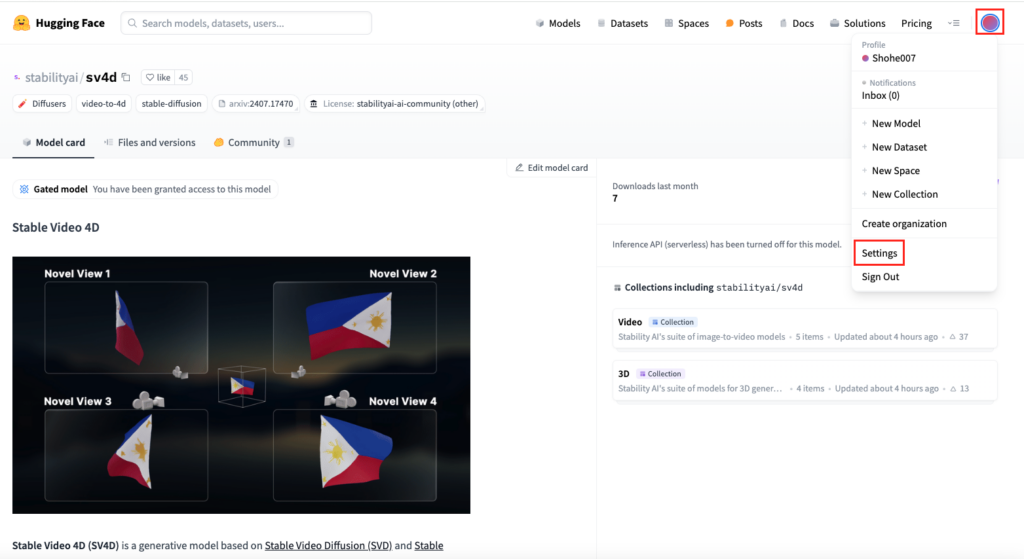
Settingsのページに移ったら「Access Tokens」をクリック。
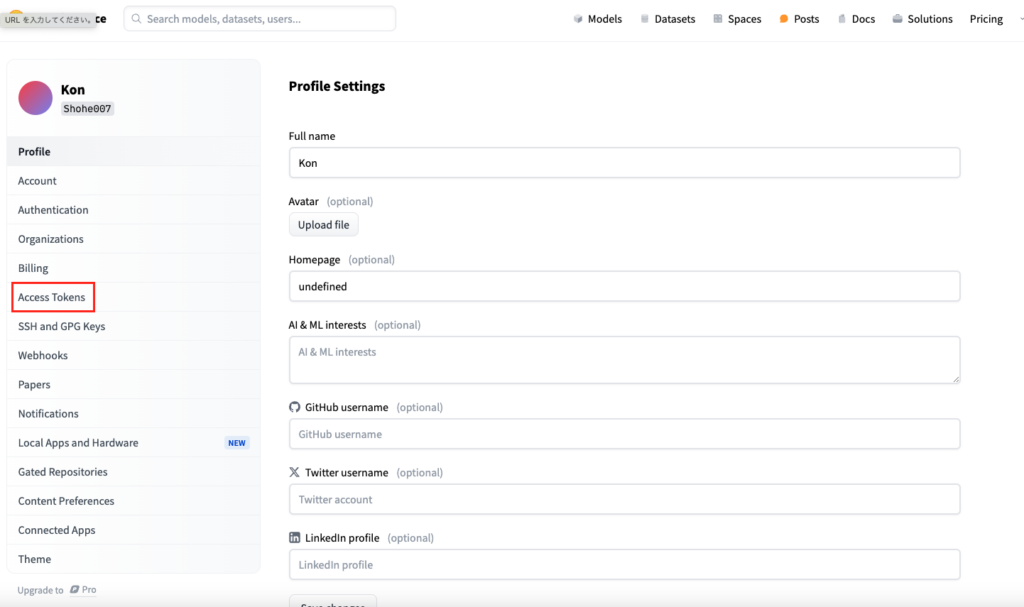
「Create new token」をクリックして、token名を入力しますがtoken名は好きなものに設定してください。
またToken typeは「Read」でOKです。
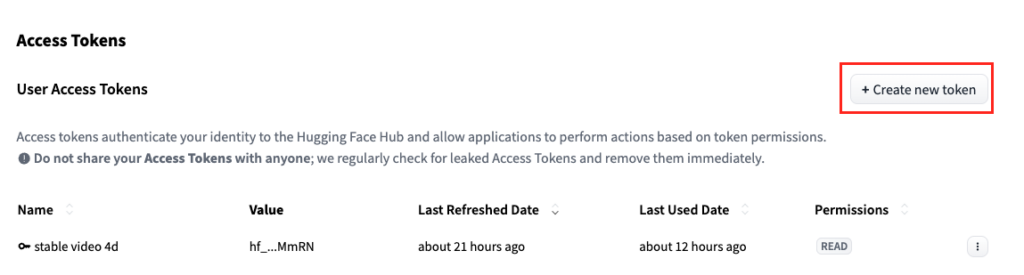
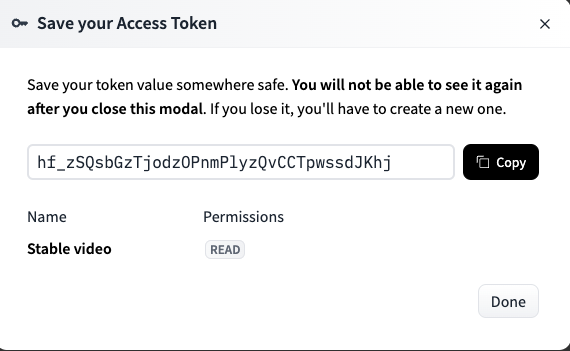
「Create token」をクリックするとtokenが表示されますが、コピペができるのはこの時だけなので、必ずコピペをしておきましょう。
Stable Video 4Dを動かすのに必要な動作環境
google colaboratoryで実行する際には、GPUを使う必要があります。
google colaboratoryの画面から「ランタイム」→「ランタイムのタイプを変更」→「T4 GPU」を選択しておきましょう。
- Pythonのバージョン:Python 3.8以上
- 使用ディスク量:70.3GB
- システムRAMの使用量:7.3GB
- GPU RAMの使用量:15GB以上
Stable Video 4Dのサンプルコードはこちら
!pip install torch==2.3.1 torchvision torchaudio torchtext --force-reinstall
#ランタイムの再起動が入ります
!pip install torchtext==0.15.2
from huggingface_hub import hf_hub_download
# Hugging Face APIトークンを設定
from huggingface_hub import login
login(token="your_access_token")
!mkdir -p checkpoints
hf_hub_download(repo_id="stabilityai/sv4d", filename="sv4d.safetensors", local_dir="checkpoints")
hf_hub_download(repo_id="stabilityai/sv3d", filename="sv3d_u.safetensors", local_dir="checkpoints")
hf_hub_download(repo_id="stabilityai/sv3d", filename="sv3d_p.safetensors", local_dir="checkpoints")
!git clone https://github.com/Stability-AI/generative-models.git
%cd generative-models
!pip install -r requirements/pt2.txt
%cd /content/generative-models
!ls scripts/sampling/simple_video_sample_4d.py
!ls -l /content/checkpoints/sv3d_u.safetensors
!sed -i 's|"checkpoints/sv3d_u.safetensors"|"/content/checkpoints/sv3d_u.safetensors"|g' /content/generative-models/scripts/demo/sv4d_helpers.py
!grep "sv3d_u.safetensors" /content/generative-models/scripts/demo/sv4d_helpers.py
!sed -i 's|"checkpoints/sv3d_u.safetensors"|"/content/checkpoints/sv3d_u.safetensors"|g' sgm/models/diffusion.py
!grep "sv3d_u.safetensors" sgm/models/diffusion.py
!mkdir -p checkpoints
!ln -sf /content/checkpoints/sv3d_u.safetensors checkpoints/sv3d_u.safetensors
!ls -l checkpoints/sv3d_u.safetensors
!python scripts/sampling/simple_video_sample_4d.py \
--input_path "assets/test_video2.mp4" \
--output_folder /content/outputs/sv4d \
--sv3d_version sv3d_u \
--device cuda \
--num_steps 2 \
--elevations_deg 10.0 \
--verbose True \
--decoding_t 1少し長いですが、GitHubのコードでは動かなかったので、実際に私が動かしたコードです。
上記のコードで動画生成までは動くのですが、最終的には「CUDA out of memory. Tried to allocate 266.00 MiB (GPU 0; 14.75 GiB total capacity; 14.31 GiB already allocated; 63.06 MiB free; 14.53 GiB reserved in total by PyTorch)」というエラーが出てしまい、google colaboratory環境でStable Video 4Dを動かすことができません。
google colaboratory Proであれば実装可能かと思い調べたところ、GitHubのIssuesにA100 GPU (40GB)でも動かない投稿がありました。
参考記事:「A100 GPU (40GB)でも動かないよ」というIssue
Stable Video 4Dのパラメータ
Stable Video 4Dではいくつかのパラメータがあります。
- –input_path:入力ビデオのパス(デフォルトはassets/test_video.mp4)
- –output_folder:出力フォルダ(デフォルトはoutputs/sv4d)
- –sv3d_version:使用するSV3Dのモデルバージョン(デフォルトはsv3d_u)
- –device:使用デバイス(デフォルトはcuda)
- –num_steps:サンプリングステップ数
- –fps_id:FPSの設定
- –motion_bucket_id:モーションバケットID
- –elevation_deg:仰角(デフォルトは10.0度)
- –azimuths_deg:方位角
- –remove_bg:背景除去(デフォルトはFalse)
モーションバケットIDはStable Videoにおいて、生成される動画の動きや量を制御するためのパラメータ。値が低くなればより動きの少ない動画を作成し、値が大きくなればより動きの多い動画を生成します。
またremove_bgはTrueにすることで、無地背景の動画の場合rembgを使ってビデオフレームをトリミングします。
Stable Video 4Dの活用方法
Stable Video 4Dは今後、ゲーム開発やビデオ編集、バーチャルリアリティなどの分野での応用を想定して開発を進めています。Stable Video 4Dはより自然により高品質な動画生成が可能であり、作成した動画のリアリティと没入感を高めることが可能。
例えば、従来の映画撮影にStable Video 4Dの技術を活用すれば、特殊効果を作成したり、複雑なカメラの動きをより簡単にレンダリングできるため、よりハイクオリティな映画がこれまでよりも簡単に撮影できる可能性があります。
現在はまだ開発段階であり、実用化には進んでいませんが、Stable Video 4Dが実用化されれば、これまでの動画撮影の常識が覆されるでしょう。今後の発展に目が離せませんね!
なお、OpenAIの動画生成AIについて詳しく知りたい方は、下記の記事を合わせてご覧ください。

まとめ
本記事では、Stable Video 4Dについて解説をしました。従来のモデルとは異なり、より自然に多角的動画を作成できるStable Video 4Dですが、現状ではより高性能なGPUが必要であり、気軽に使うことができません。
今後、より軽量になり、google colaboratoryでも問題なく使える日が待ち遠しいですね!Stable Video 4Dが実用的になれば、観光地などで撮影した動画を360度見渡せるようにあったり、ユーザーが視点を変えながら楽しむことができそうです!
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


