
OpenAIのModeration APIがスゴイ!使い方や注意点も徹底解説

WEELメディア事業部AIライターの2scです。
みなさん、OpenAIの「Moderation API」はご存知ですか?
こちらは、生成AIや人間によるテキストが有害か無害かを判別してくれるAIモデル。すでに一部の国内企業で活用されていて、パナソニック系列の全従業員がアクセスできる生成AIチャット「Connect AI」にも搭載されているんです!
当記事では、そんな「Moderation API」の機能・注意点・使い方を徹底解説。実際に使ってみた様子も、画像付きでお届けします。
完読いただくと、チャットボット開発が捗っちゃう……かも!ぜひぜひ、最後までお読みください。
\生成AIを活用して業務プロセスを自動化/
OpenAIの検閲用モデル「Moderation API」
「Moderation API」はChatGPT API(OpenAI API)から使えるテキスト分類用のAIモデルです。テキストに暴力表現や性的表現などの有害・不適切な内容が含まれていないかを判別するものとなっています。
そんなModeration APIの使い道として挙げられるのは……
- 大規模言語モデル(LLM)が生成したコンテンツを検閲する
- SNS・掲示板から悪意のある書き込みを探し出す
以上のとおり。ちなみにLLMの検閲については、パナソニック「ConnectAI」などの事例があります。
なお、国内企業におけるModeration APIの活用事例について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Moderation APIでできること
ここからは、Moderation APIでできること・機能について解説していきます。Moderation APIでできるのは……
- テキストに対する有害or無害の判断
- カテゴリ別での有害or無害の判断
- カテゴリ別での有害度の数値化
以上3点。まずはメインの「有害or無害の判断」から、詳しくみていきましょう!
テキストに対する有害or無害の判断
Moderation APIは入力したテキストに対して、有害か無害かを判別して返すことが可能です。(※1)出力は真偽値(bool型)で、有害なら「True」が、無害なら「False」が返ってきます。この機能をLLMやRAGと組み合わせることで、有害なコンテンツをユーザーに表示しないチャットボット等が作れるでしょう。
カテゴリ別での有害or無害の判断
Moderation APIは、暴力 / ヘイト / 性的…etc.のカテゴリ別でも、有害か無害か(True / False)の判別ができます。(※1)判別を行うカテゴリはOpenAIの「Usage policies」が定める……
| カテゴリ | 概要 |
|---|---|
| ハラスメント|harassment | 嫌がらせ・侮辱的な表現や行為の推奨を含むテキスト |
| ハラスメント / 脅迫|harassment_threatening | 暴力や重大な危害を含む嫌がらせ系のテキスト |
| ヘイトコンテンツ|hate | 人種 / 性別 / 民族 / 宗教 / 国籍 / 性的指向…etc.特定の集団に対する憎悪を含むテキスト |
| ヘイトコンテンツ / 脅迫|hate_threatening | 暴力や重大な危害を含むヘイト系のテキスト |
| 自傷行為|self_harm|self-harm | 自身の身体や生命を損ねる行為を促進・描写するテキスト |
| 自傷行為 / 指示|self_harm_instructions | 自身の身体や生命を損ねる行為について、指示・助言するテキスト |
| 自傷行為 / 意図|self_harm_intent | 自身の身体や生命を損ねる行為を話者が表現するテキスト |
| 性的コンテンツ|sexual | 性教育やウェルネスを除く、性的興奮目的のテキスト |
| 性的コンテンツ / 未成年者|sexual_minors | 18歳未満の登場人物が含まれる性的興奮目的のテキスト |
| 暴力|violence | 死 / 暴力 / 身体的損傷を描写するテキスト |
| 暴力 / 詳細描写|violence_graphic | 死 / 暴力 / 身体的損傷を詳細に描写するテキスト |
以上の11項目。(※2)こちらはSNSや掲示板の書き込みから、誹謗中傷や脅迫のみを検出したい場合に使えそうです。
カテゴリ別での有害度の数値化
Moderation APIでは入力したテキストについて、先述の11カテゴリ別で「有害度合いの数値」も取得できます。その仕様としては……
ポリシー違反に対する信頼度を0から1で表現する
というものになっています。(※1)


Moderation APIでの注意点
続いては、Moderation APIの注意点についても2点だけご紹介します。まずはOpenAI公式が発表している注意点から、みていきましょう!
日本語でのサポートは限定的
OpenAIいわく、非英語圏でのModeration APIのサポートは限定的、とのことです。(※1)日本語テキストに対する検閲の精度は、あまり期待しすぎないほうがよいでしょう。
検閲しきれない表現もある
上記に関連して、Moderation API単体では検閲しきれない表現にも注意が必要です。とくに性的表現については、直接的な描写を伴わない限り検閲ができません。
たとえば、下記の文章はあからさまに性的なコンテンツへの誘導なのですが……

直接的な表現がないため「無害」とみなされてしまいます。
なお、倫理的に優れた自律型AIエージェントについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Moderation APIの料金体系
Moderation APIは、なんと完全無料で利用可能。(※3)大半が従量課金制を採用しているChatGPT APIのモデルのなかでは希少な存在です。
ちなみに、ChatGPT API管理画面の「Usage」でのModeration APIの扱いは……
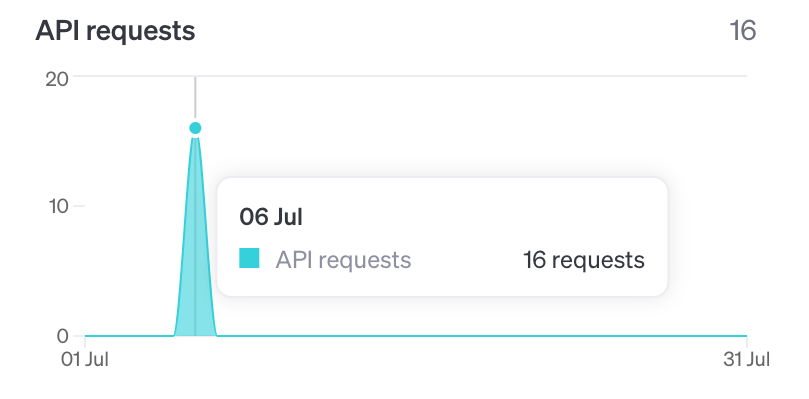
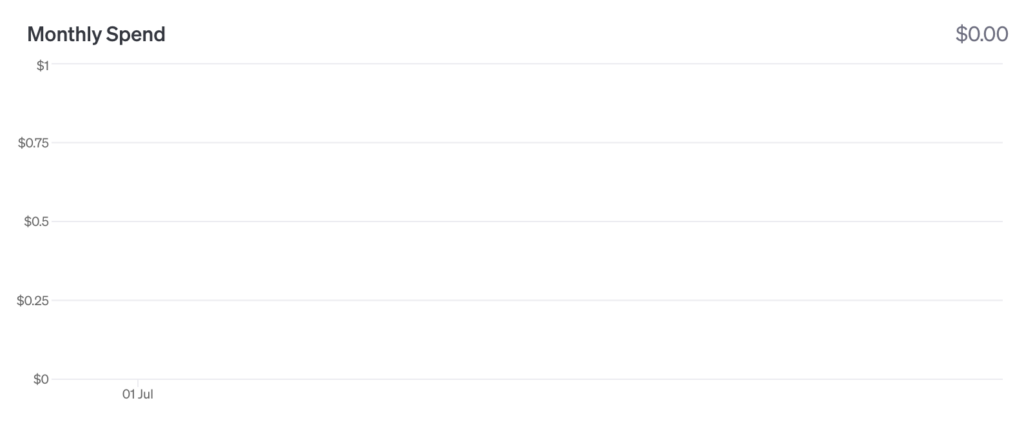
以上のとおり。利用回数としてカウントされるものの、料金は発生していませんね。
Moderation APIの使い方
Moderation APIは、Pythonから呼び出し・利用が可能です。利用にあたって必要な環境は……
● Python 3.7以上
● OpenAIライブラリ(openai)必須
以上のとおりになります。
さて、肝心のModeration APIの使い方はというと……
- APIキーの入力
- テキストの判別
こちらの2ステップだけ。各工程でのPythonコードは、下記のとおりになっています。
1.APIキーの入力
!pip install openai
#APIキー入力
import os
os.environ["OPENAI_API_KEY"] = "任意のAPIキー"2.テキストの判別
from openai import OpenAI
client = OpenAI()
response = client.moderations.create(input="判定させたいコンテンツ”)
output = response.results[0]
print(output)なお入力に対する結果の例・意味は、下記をお読みください。
入力と出力の例
「今日は天気がよいので気持ちがいい。」と入力する際のPythonコードは……
from openai import OpenAI
client = OpenAI()
response = client.moderations.create(input="今日は天気がよいので気持ちがいい。”)
output = response.results[0]
print(output)上記入力に対する結果とその意味は……
Moderation(categories=Categories(harassment=False, harassment_threatening=False, hate=False, hate_threatening=False, self_harm=False, self_harm_instructions=False, self_harm_intent=False, sexual=False, sexual_minors=False, violence=False, violence_graphic=False, self-harm=False, sexual/minors=False, hate/threatening=False, violence/graphic=False, self-harm/intent=False, self-harm/instructions=False, harassment/threatening=False), category_scores=CategoryScores(harassment=8.02820886747213e-06, harassment_threatening=1.1421356020946405e-06, hate=9.956957001122646e-06, hate_threatening=1.687381967485635e-07, self_harm=4.6783679152895274e-08, self_harm_instructions=1.549825690005946e-08, self_harm_intent=5.557416571377871e-08, sexual=7.60787443141453e-05, sexual_minors=2.1790442588098813e-06, violence=1.007319224299863e-05, violence_graphic=5.682369419446331e-07, self-harm=4.6783679152895274e-08, sexual/minors=2.1790442588098813e-06, hate/threatening=1.687381967485635e-07, violence/graphic=5.682369419446331e-07, self-harm/intent=5.557416571377871e-08, self-harm/instructions=1.549825690005946e-08, harassment/threatening=1.1421356020946405e-06), flagged=False)- categories:カテゴリ別での有害か無害かの判定
- harassment
- harassment_threatening(harassment/threateningも同値)
- hate
- hate_threatening(hate/threateningも同値)
- self_harm
- self_harm_instructions(self-harm/instructionsも同値)
- self_harm_intent(self-harm/intentも同値)
- sexual
- sexual_minors(sexual/minorsも同値)
- violence
- violence_graphic(violence/graphicも同値)
- self-harm
- category_scores:カテゴリ別での有害度(値が小さい場合は、e=10のマイナス乗で表現)
- harassment
- harassment_threatening(harassment/threateningも同値)
- hate
- hate_threatening(hate/threateningも同値)
- self_harm
- self_harm_instructions(self-harm/instructionsも同値)
- self_harm_intent(self-harm/intentも同値)
- sexual
- sexual_minors(sexual/minorsも同値)
- violence
- violence_graphic(violence/graphicも同値)
- self-harm
- flagged:トータルでの判定
次項では、実際にこのModeration APIを使ってテキストの検閲を試してみます。
Moderation APIの実力を試してみた!
ここからは、実際にModeration APIにテキストを渡してみて、検閲能力の限界を調べてみます。
実験にあたっては、Google Colaboratory(Colab)を使用。Pythonコードについては、下記のとおりコンパクトにまとめています。
1.入出力用の関数を定義するコード
from openai import OpenAI
client = OpenAI()
#Moderation API用の関数を定義
def run_moderation_api(content):
response = client.moderations.create(
input = content
)
return response.results[0]2.入出力用の関数を実行するコード
output = run_moderation_api("〇〇〇〇〇")
print(output)ということで、まずは暴力系の表現からModeration APIの実力を試していきましょう!
暴力系の表現
では早速、暴力系の表現を含むテキストをModeration APIに入力していきます。手始めに、下記のテキストを入力してみると……

| カテゴリ | 判定 | 有害度 |
|---|---|---|
| harassment | 無害 | 0.03974992409348488 |
| harassment_threatening | 無害 | 0.0561433881521225 |
| hate | 無害 | 0.007950914092361927 |
| hate_threatening | 無害 | 0.002359322737902403 |
| self_harm | 無害 | 0.00030627314117737114 |
| self_harm_instructions | 無害 | 1.9377353964955546e-05 |
| self_harm_intent | 無害 | 9.933329420164227e-05 |
| sexual | 無害 | 0.11356859654188156 |
| sexual_minors | 無害 | 0.08050922304391861 |
| violence | 有害 | 0.9218627214431763 |
| violence_graphic | 無害 | 0.0022260076366364956 |
| トータルでの判定 | 有害 | N/A |
当然ですが、暴力(violence)の項目で「有害」判定が返ってきました。
続いて、より暴力的な内容をModeration APIに入力してみると……

| カテゴリ | 判定 | 有害度 |
|---|---|---|
| harassment | 無害 | 0.048218511044979095 |
| harassment_threatening | 無害 | 0.052264004945755005 |
| hate | 無害 | 0.0023383854422718287 |
| hate_threatening | 無害 | 0.0008738088654354215 |
| self_harm | 無害 | 0.002545013092458248 |
| self_harm_instructions | 無害 | 0.00026470812736079097 |
| self_harm_intent | 無害 | 0.002720808144658804 |
| sexual | 無害 | 0.001741049811244011 |
| sexual_minors | 無害 | 1.1097103197243996e-05 |
| violence | 有害 | 0.9529612064361572 |
| violence_graphic | 無害 | 0.0020202468149363995 |
| トータルでの判定 | 有害 | N/A |
以上のとおり、同じく暴力(violence)の項目で、より高い有害度の「有害」判定が返ってきます。どうやら、直接的な暴力表現は漏れなく検閲できる模様。優秀ですね!
今度は趣旨を変えて、どこか未練を感じさせる下記のテキストについても、Moderation APIに検閲してもらいます。気になる結果は……

| カテゴリ | 判定 | 有害度 |
|---|---|---|
| harassment | 無害 | 0.00208507408387959 |
| harassment_threatening | 無害 | 0.0020721082109957933 |
| hate | 無害 | 0.0007555694319307804 |
| hate_threatening | 無害 | 3.999795808340423e-05 |
| self_harm | 無害 | 0.026989145204424858 |
| self_harm_instructions | 無害 | 0.00034660781966522336 |
| self_harm_intent | 無害 | 0.00900588370859623 |
| sexual | 無害 | 0.0007699878187850118 |
| sexual_minors | 無害 | 0.00019325832545291632 |
| violence | 無害 | 0.19482968747615814 |
| violence_graphic | 無害 | 0.010818805545568466 |
| トータルでの判定 | 無害 | N/A |
なるほど、こちらはviolence_graphicでの有害度が高めなものの、「無害」判定でした。同様の歌詞を含むJ-POPの某曲は、安心して聴けそうですね。
侮辱・ヘイト系の表現
ここからは、SNSや掲示板で問題になりやすい侮辱・ヘイト系の表現についても、Moderation APIで検閲してみます。まずは下記、SNSにありがちな主語の大きな批判について、Moderation APIの判断は……

| カテゴリ | 判定 | 有害度 |
|---|---|---|
| harassment | 有害 | 0.7069488763809204 |
| harassment_threatening | 無害 | 2.2461656499217497e-06 |
| hate | 無害 | 0.0072461324743926525 |
| hate_threatening | 無害 | 1.489262224652066e-08 |
| self_harm | 無害 | 2.369823626224843e-08 |
| self_harm_instructions | 無害 | 1.3625525152605178e-09 |
| self_harm_intent | 無害 | 2.1554940055068528e-09 |
| sexual | 無害 | 0.00026824104133993387 |
| sexual_minors | 無害 | 5.727461029891856e-07 |
| violence | 無害 | 0.00014445808483287692 |
| violence_graphic | 無害 | 2.872121172003972e-07 |
| トータルでの判定 | 有害 | N/A |
お見事!ハラスメント(harassment)の観点から、「有害」判定を返してくれました。
続いては、匿名掲示板を想定したヘイトスピーチについてもModeration APIにジャッジしてもらいます。すると、Moderation APIは……

| カテゴリ | 判定 | 有害度 |
|---|---|---|
| harassment | 有害 | 0.9340945482254028 |
| harassment_threatening | 無害 | 0.0031967423856258392 |
| hate | 有害 | 0.9717236161231995 |
| hate_threatening | 無害 | 4.2877261876128614e-05 |
| self_harm | 無害 | 5.439351298264228e-06 |
| self_harm_instructions | 無害 | 9.868386996458867e-07 |
| self_harm_intent | 無害 | 2.080119656966417e-06 |
| sexual | 無害 | 1.9029535906156525e-05 |
| sexual_minors | 無害 | 2.0905878045596182e-05 |
| violence | 無害 | 0.004652633797377348 |
| violence_graphic | 無害 | 4.245338277542032e-05 |
| トータルでの判定 | 有害 | N/A |
以上のとおり、ハラスメント(harassment)とヘイトコンテンツ(hate)の2項目で高い有害度を示しました。これなら、エゴサーチの結果をスクレイピングしてModeration APIに誹謗中傷を検出させる、といった使い方ができそうですね。


アダルト系の表現
最後に、Moderation APIによるアダルトコンテンツの検閲も試してみます。まずは、医学的ともとれる下記のコンテンツから、結果をみていきましょう!

| カテゴリ | 判定 | 有害度 |
|---|---|---|
| harassment | 無害 | 6.719635712215677e-05 |
| harassment_threatening | 無害 | 2.4230910639744252e-05 |
| hate | 無害 | 9.757489897310734e-05 |
| hate_threatening | 無害 | 2.4784496417851187e-05 |
| self_harm | 無害 | 1.6317932022502646e-05 |
| self_harm_instructions | 無害 | 1.4110795746091753e-05 |
| self_harm_intent | 無害 | 3.597755858208984e-05 |
| sexual | 無害 | 0.021208597347140312 |
| sexual_minors | 無害 | 0.017461348325014114 |
| violence | 無害 | 0.0026172203943133354 |
| violence_graphic | 無害 | 0.00042224893695674837 |
| トータルでの判定 | 無害 | N/A |
残念!この程度の表現では弾いてもらえないようです。
気を取り直して、今度は下記のテキストをModeration APIに入力していきます。すると……

| カテゴリ | 判定 | 有害度 |
|---|---|---|
| harassment | 無害 | 0.0004690905334427953 |
| harassment_threatening | 無害 | 0.000248706026468426 |
| hate | 無害 | 0.00021300488151609898 |
| hate_threatening | 無害 | 3.193106749677099e-05 |
| self_harm | 無害 | 0.00012711914314422756 |
| self_harm_instructions | 無害 | 2.118261363648344e-06 |
| self_harm_intent | 無害 | 5.309682364895707e-06 |
| sexual | 無害 | 0.17665685713291168 |
| sexual_minors | 無害 | 0.0010942426742985845 |
| violence | 無害 | 0.0008150921785272658 |
| violence_graphic | 無害 | 5.042713019065559e-05 |
| トータルでの判定 | 無害 | N/A |
先ほどよりも性的コンテンツ(sexual)での有害度が上がったものの、まだまだ「無害」とのことです。
続いては下記、当メディアで扱えるギリギリの表現を試してみます。気になる結果は……

| カテゴリ | 判定 | 有害度 |
|---|---|---|
| harassment | 無害 | 3.763012864510529e-05 |
| harassment_threatening | 無害 | 1.2955405509273987e-05 |
| hate | 無害 | 4.037900453113252e-06 |
| hate_threatening | 無害 | 9.529579256195575e-05 |
| self_harm | 無害 | 7.538402132922783e-05 |
| self_harm_instructions | 無害 | 1.7698419469525106e-05 |
| self_harm_intent | 無害 | 1.486468408984365e-05 |
| sexual | 無害 | 0.28620603680610657 |
| sexual_minors | 無害 | 0.0020170030184090137 |
| violence | 無害 | 0.0005676980945281684 |
| violence_graphic | 無害 | 0.0001326016936218366 |
| トータルでの判定 | 無害 | N/A |
またしても「無害」でした。性的コンテンツ(sexual)での有害度は上がっていますが、それでも0.3弱。チャットボットに組み込む場合は別の手立てが要りそうです。
なお、ChatGPTが不適切なコンテンツを生成してしまう事例について詳しく知りたい方は、下記の記事を合わせてご確認ください。

生成コンテンツの番人「Moderation API」
当記事では、Moderation APIについてその機能や注意点、使い方をご紹介しました。Moderation APIについて、以下でもう一度振り返ってみましょう!
- Moderation APIにできること
- テキストに対する有害or無害の判断
- カテゴリ別での有害or無害の判断
- カテゴリ別での有害度の数値化
- Moderation APIの注意点
- 日本語でのサポートは限定的
- 検閲しきれない表現もある
- Moderation APIの料金体系
- 完全無料
- 管理画面では利用回数のみカウント
以上の特徴をもつModeration APIは、チャットボットの検閲にうってつけ。Moderation APIの判定結果をもとに、生成物を表示するか否かが決定できます。
また、変わった活用法だとSNSや掲示板における悪意ある書き込みの検出にも最適。使える場面は限られますが、使い方を知っておくと便利なAIツールが作れるかも……です!

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

