
【Phi-4-multimodal】マイクロソフトのマルチモーダルモデル!概要から料金、実力まで徹底検証

- テキストや画像・音声にも対応しているマルチモーダルモデル
- 異なるモダリティの組み合わせでの推論も可能
- 特に音声関連の性能が高い
2025年2月27日、Microsoftから新たなLLMが登場!
今回リリースされたモデルは2種類で、Phi-4-multimodalとPhi-4-miniです。Phi-4-miniは小型ながらに高速処理が可能なモデルですが、Phi-4-multimodalはテキストのみならず画像や音声などの入力が可能なマルチモーダルモデル。
LoRAの組み合わせ技術を用いることで、異なるモダリティ間の干渉を最小限に抑えながらも性能を発揮することができます。
本記事では、Phi-4-multimodalの概要や従来のPhi-4との違い、Phi-4-multimodalの実装方法についてお伝えします。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Phi-4-multimodalの概要
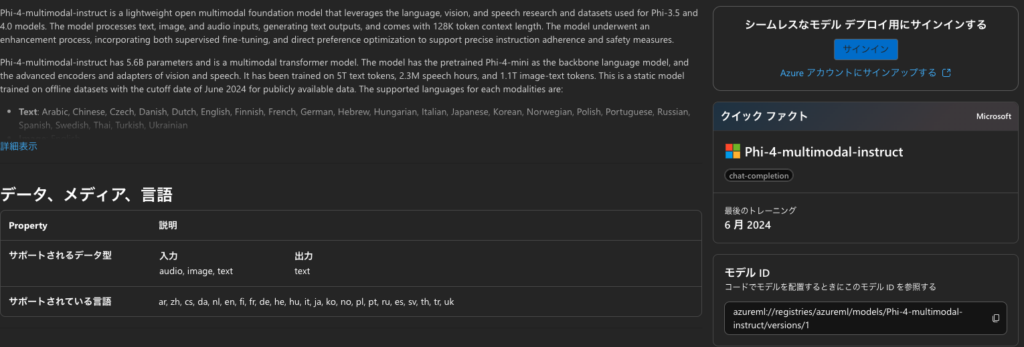
Phi-4-multimodalはMicrosoftがリリースしたマルチモーダルモデル。テキストだけではなく、画像や音声などの組み合わせによる推論が可能になっていて、音声+テキストや画像+音声などといった推論が可能。
音声+テキストや画像+音声などの組み合わせによる推論は、Phi-4-multimodalよりもはるかに大きな言語モデルの性能に匹敵もしくは上回る性能を有しています。
また、OpenASRリーダーボードでトップクラスの性能を記録(2025年1月17日時点)しており、特に多言語対応の音声認識において優れた性能を発揮します。
さらにPhi-4-multimodalはMixture of LoRAsという技術を用いて、異なるモダリティでの推論を可能としており、Mixture of LoRAsによってベースになる言語モデルの性能を保ったまま、マルチモーダルへ応用することが可能になります。
テキストの対応言語は、英語や日本語、フランス語など24言語に対応しており、画像処理は英語のみ。また音声処理に関しては英語や日本語、フランス語など8言語に対応しています。
Phi-4-multimodalの性能
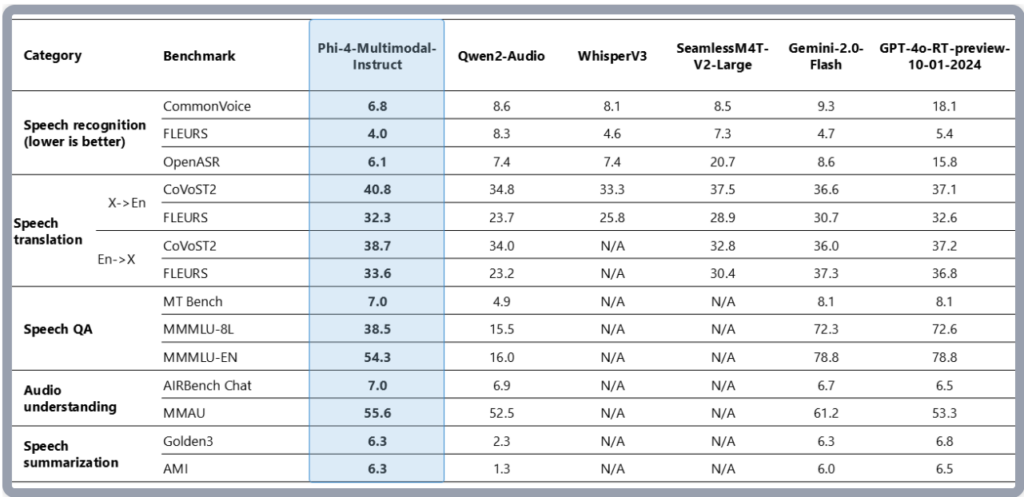
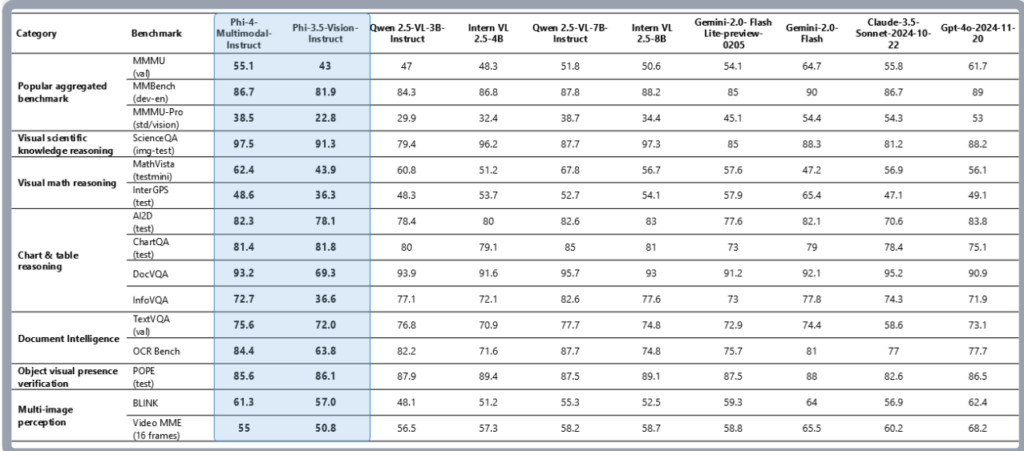
Phi-4-multimodalの性能として、s_AI2D、s_DocVQA、s_InfoVQAの3つのベンチマークでは、比較対象モデルを上回っています。s_ChartQAは僅差でGemini-2.0-Flashに軍配が上がっています。

s_AI2D:画像認識と推論タスク
s_ChartQA:チャートやグラフの理解と質問応答
s_DocVQA:文書内の情報を理解し、質問に回答
s_InfoVQA:視覚情報を基にした質問応答
この結果からPhi-4-multimodalは画像認識やテキスト、音声情報をもとにした推論能力が非常に高く、複雑な質問応答も可能と言えるでしょう。
音声関連のベンチマーク
音声認識や音声要約など、音声関連のベンチマークはこちらです。
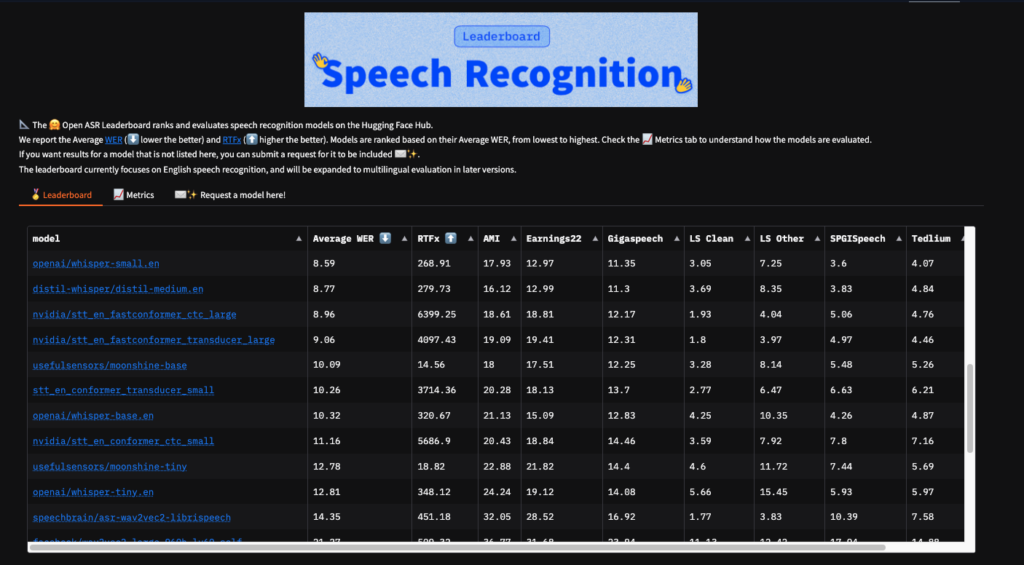
Speech Recognition(音声認識)は、lower is betterと書かれており、スコアが低い方が精度が高いということになります。これは誤り率を表していますが、3つの項目全てでトップスコアを達成しています。
そのほかのスコアも見てみると、いずれのスコアでもトップクラスのスコアを達成しており、GPT-4oとPhi-4-multimodalが2大トップと言えます。Phi-4-multimodalのパラメータ数は5.6Bのため、GPT-4oに比べるとかなり小さいです。
しかし、音声関連の性能は同等もしくはそれを上回る性能を発揮します。
視覚関連のベンチマーク
最後に視覚関連のベンチマークです。
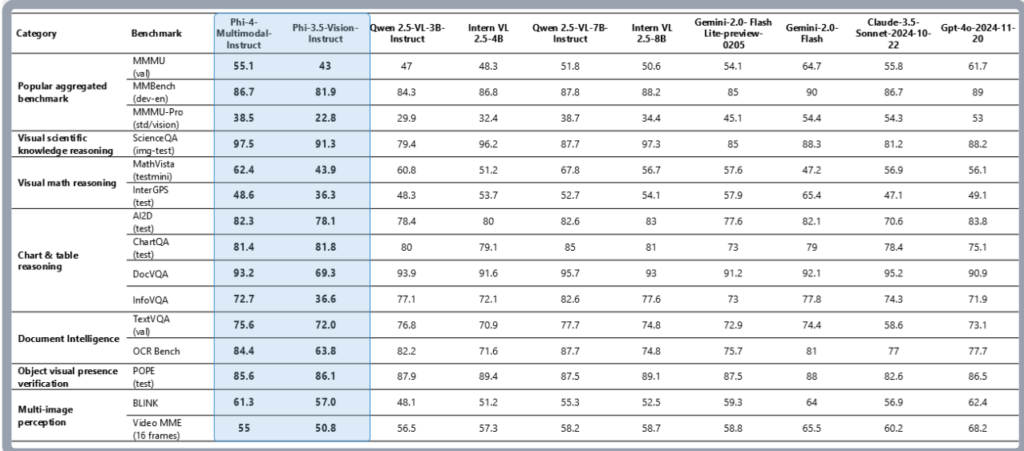
Phi-4-multimodalはモデルサイズが小さいにもかかわらず、文書や図表の理解、光学式文字認識、視覚科学推論などの一般的なマルチモーダル能力において性能を維持しており、Gemini-2-Flash-lite-preview/Claude-3.5-Sonnetに匹敵するか、それを上回っています。
特に数学の推論と科学的推論において、高い性能を発揮。
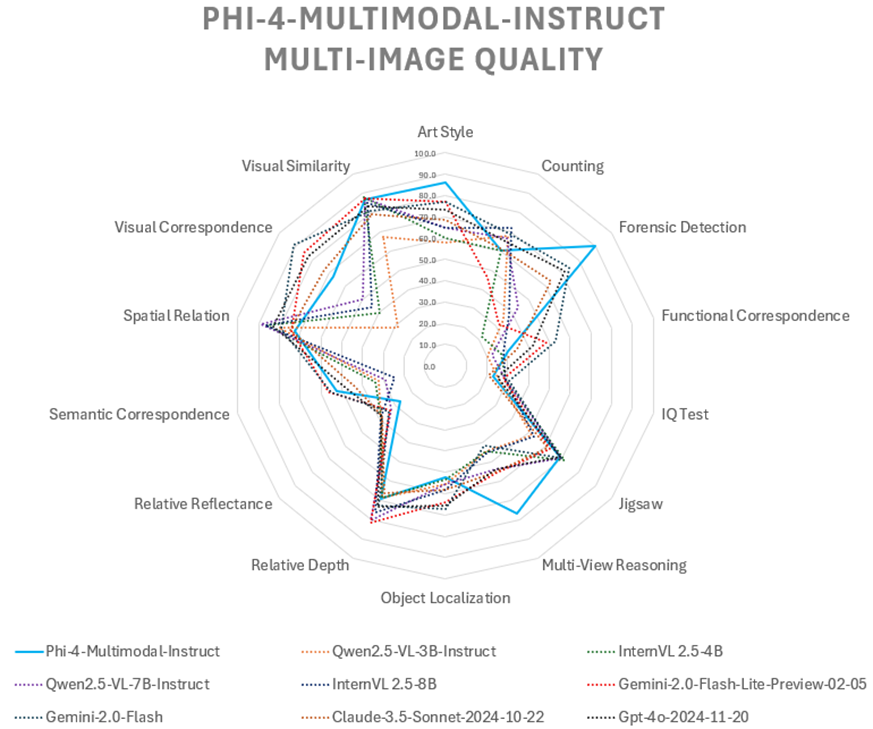
複数画像の理解を評価した結果が上記のレーダーチャートです。青線がPhi-4-multimodalを示しています。
それぞれのベンチマークについて簡単に触れておきます。
Art Style:画像のアートスタイルを識別する能力
Counting:画像内のオブジェクトの数を正確にカウントする能力
Forensic Detection:画像の改ざんや不正加工を検出する能力
Functional Correspondence:オブジェクトの機能的な関連性を理解する能力
IQ Test:画像を使った論理推論能力を評価
Jigsaw:バラバラの画像を統合し、元の情報を推測する能力
Multi-View Reasoning:異なる視点の画像から一貫した情報を抽出する能力
Object Localization:画像内の特定のオブジェクトを認識し、位置を特定する能力
Relative Depth:画像内のオブジェクト間の奥行き・距離感を把握する能力
Relative Reflectance:画像の光の反射や影の具合を理解する能力
Semantic Correspondence:画像間での意味的なつながりを理解する能力
Spatial Relation:画像間でのオブジェクトの位置関係や構造を把握する能力
Visual Correspondence:画像間で共通の情報がどれだけ一致しているかを測定
Visual Similarity:画像間の視覚的な類似性を測る能力
複数画像を使った推論タスクではPhi-4-multimodalは画像の改ざんや不正を検出する性能やアートスタイルを識別する性能が高いことがわかります。
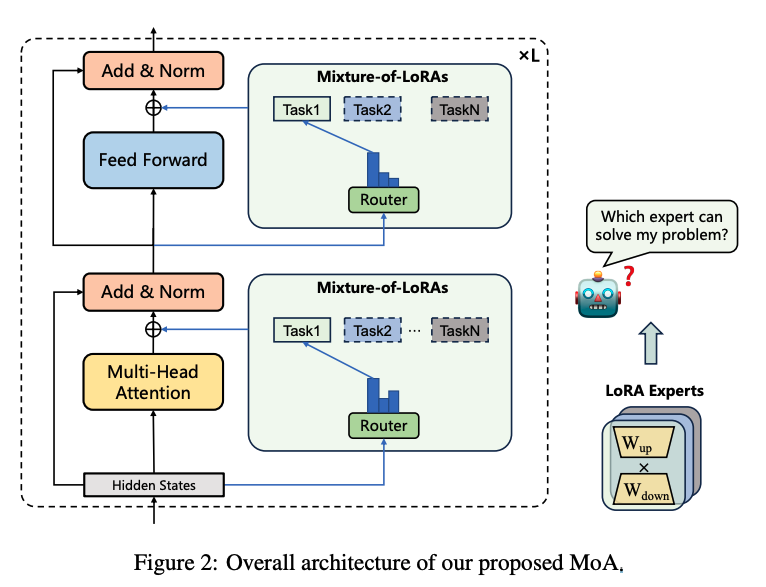
Mixture of LoRAs
Mixture of LoRAsはLLMのマルチタスク学習に特化したチューニング方法です。
ドメイン固有のLoRAモジュールを複数組み合わせることで、タスク間の干渉を防ぎ、各タスクのパフォーマンスを向上させます。また、このLoRAモジュールに繰り返し新しいドメインを適応させることができるため、従来よりも速くドメイン固有の適応が可能になりました。
Phi-4-multimodalとPhi-4の違い
Phi-4-multimodalはPhi-4とは異なり、マルチモーダルモデルです。パラメーター数はPhi-4の方が大きく、Phi-4は14Bに対してPhi-4-multimodalは5.6B。Phi-4は14Bながら、その性能はGPT-4o以上の性能を発揮することもあります。
両者ともコンテキスト長は128Kトークンであり、長文にも対応をしています。
また、得意とするタスクも異なっており、Phi-4は数学タスクやコーディング、推論などを得意とする一方、Phi-4-multimodalは特に音声関連のタスクを得意としており、ベンチマークも優れた性能を発揮しています。


Phi-4-multimodalのライセンス
Phi-4-multimodalのライセンスはMITライセンスです。商用利用や改変なども可能ですが、配布する場合には、元の著作権表示とライセンスの全文を記載する必要があるので注意しましょう。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、複数タスクをハイレベルで実行できるVLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Phi-4-multimodalの使い方
Phi-4-multimodalはHugging FaceかAzure AI Foundryで使うことができます。
今回はHugging Faceの内容をgoogle colaboratoryで実装してみます。
◼︎Pythonのバージョン:3.9以上
◼︎システム RAM
6.8 / 83.5 GB
◼︎GPU RAM
22.9 / 40.0 GB
◼︎ディスク
46.7 / 235.7 GB
◼︎GPUの種類:A100
◼︎プラン:有料
まずは必要なライブラリをインストールします。
!pip install torch transformers accelerate soundfile pillow scipy torchvision backoff
!pip install flash-attn --no-build-isolationライブラリのインストールが終わったら、モデルをダウンロードします。
モデルのダウンロードはこちら
import torch
from transformers import AutoProcessor, AutoModelForCausalLM, GenerationConfig
model_name = "microsoft/Phi-4-multimodal-instruct"
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="cuda" if torch.cuda.is_available() else "cpu", # GPU が使える場合は CUDA
torch_dtype=torch.float16, # メモリ節約
trust_remote_code=True
)
generation_config = GenerationConfig.from_pretrained(model_name)サンプルコードはこちら
prompt = "<|user|>こんにちは、Phi-4-multimodal!このモデルについて教えて。<|end|><|assistant|>"
inputs = processor(text=[prompt], return_tensors="pt").to("cuda" if torch.cuda.is_available() else "cpu")
generate_ids = model.generate(**inputs, max_new_tokens=1000)
response = processor.batch_decode(generate_ids, skip_special_tokens=True)[0]
print(response)結果はこちら
こんにちは、Phi-4-multimodal!このモデルについて教えて。こんにちは!Phi-4-multimodalとは、2023年初頭の私の知識カットオフ時点での架空のAIモデルのようです。実際のモデルや技術については情報がありません。したがって、Phi-4-multimodalについての詳細を提供することはできません。ただし、一般的なAIモデルについて説明することはできます。もし他の質問があれば、遠慮なく聞いてください!パラメータ数が大きくないので、マルチモーダルでもgoogle colaboratoryで実行できますし、モデルのダウンロードもそこまで時間がかからずラフに実装できます。
残念ながらPhi-4-multimodalの学習データは2024年6月までみたいなので、当然ながらPhi-4-multimodalの情報はありませんでした。
異なるモダリティの組み合わせで推論ができるのかを検証
Phi-4-multimodalは異なるモダリティ(例えば、テキストと画像の組み合わせやテキストと音声の組み合わせ)の組み合わせで推論をすることが可能と発表されています。
実際に異なるモダリティの組み合わせで推論ができるのかを検証してみます。
検証内容は次の二つです。
- テキストと画像
- テキストと音声
画像は英語の画像しか読み解けないようなので、Phi-4-multimodalのベンチマーク画像を読み取ってもらおうと思います。
音声に関しては、日本語含め8言語に対応しているので、フリー音声をダウンロードして文字起こしをしてもらいます。
タスク1.テキストと画像
まずはテキストと画像の組み合わせです。画像をgoogle colaboratoryにアップロードして、読み込ませてから解説をしてもらいます。使う画像は以下です。
サンプルコード以前の内容は上述したものと同様なので、割愛します。
サンプルコードはこちら
image_path = "/content/スクリーンショット 2025-02-28 22.35.59.png"
image = Image.open(image_path)
prompt = "<|user|><|image_1|>この画像について説明してください。<|end|><|assistant|>"
inputs = processor(text=prompt, images=[image], return_tensors="pt").to("cuda" if torch.cuda.is_available() else "cpu")
generate_ids = model.generate(**inputs, max_new_tokens=1000, generation_config=generation_config)
response_text = processor.batch_decode(generate_ids, skip_special_tokens=True)[0]
print("生成結果:", response_text)結果はこちら
生成結果: この画像について説明してください。The image is a table that compares the performance of various AI models across different categories and benchmarks. The table is divided into several rows and columns, with each row representing a different category of tasks such as Popular aggregated benchmark, Visual scientific knowledge reasoning, Visual math reasoning, Chart & table reasoning, Document Intelligence, Object visual presence verification, and Multi-image perception. Each category has multiple benchmarks listed under it, such as MMMU, MMBench, ScienceQA, MathVista, InterGPS, A2DL, ChartQA, DocVQA, InfoVQA, TextVQA, OCR Bench, POF, BLINK, and Video MME. The performance scores are given in percentages, and the table also includes different AI models like Phi-4, Phi-3.5, Qwen, Intern VL, Qwen 2.5-VL-7B, Intern VL 2.5-4B, Gemini-2.0, Flash, and GPT-4o-2024-11-20. The table provides a comprehensive comparison of how each AI model performs across various tasks and benchmarks.プロンプトは日本語で入力していますが、画像の読み込みが英語のみだからか、出力も英語になってしまいました。
日本語訳:画像は、さまざまなカテゴリーとベンチマークにわたって、さまざまなAIモデルの性能を比較した表である。表はいくつかの行と列に分かれており、それぞれの行は、一般的な集計ベンチマーク、視覚的科学知識推論、視覚的数学推論、図表推論、文書知能、物体の視覚的存在検証、複数画像の知覚など、異なるカテゴリーのタスクを表しています。各カテゴリーには、MMMU、MMBench、ScienceQA、MathVista、InterGPS、A2DL、ChartQA、DocVQA、InfoVQA、TextVQA、OCR Bench、POF、BLINK、Video MMEなど、複数のベンチマークが列挙されている。性能スコアはパーセンテージで示され、表にはPhi-4、Phi-3.5、Qwen、Intern VL、Qwen 2.5-VL-7B、Intern VL 2.5-4B、Gemini-2.0、Flash、GPT-4-o-2024-11-20といったさまざまなAIモデルも含まれています。この表は、さまざまなタスクやベンチマークにおける各AIモデルのパフォーマンスを包括的に比較したものです。
てっきりベンチマークの性能まで読み取ってくれて、どのモデルが何に最も優れているのか、みたいな解説もしてくれるのかと思いましたが、画像の概要を教えてくれるだけでした。ここはプロンプト次第かもしれませんね。
画像認識AIをOCR業務に活用したい方は、以下の記事もご覧ください。

タスク2.テキストと音声
こちらもサンプルコード以前の内容は上述したものと同様なので、割愛します。ただし、サウンド関連のライブラリは必要になるので、下記はインストールしておきましょう。
import soundfile as sfタスク2で使う音声はこちらのサイトからダウンロードをしています。今回はCM原稿(せっけん)という音声を使っています。l
サンプルコードはこちら
audio_path = "/content/001-sibutomo.mp3"
audio_data, samplerate = sf.read(audio_path)
prompt = "<|user|><|audio_1|>この音声を文字起こししてください。<|end|><|assistant|>"
inputs = processor(text=prompt, audios=[(audio_data, samplerate)], return_tensors="pt").to("cuda" if torch.cuda.is_available() else "cpu")
generate_ids = model.generate(**inputs, max_new_tokens=1000, generation_config=generation_config)
response_text = processor.batch_decode(generate_ids, skip_special_tokens=True)[0]
print("生成結果:", response_text)結果はこちら
生成結果: この音声を文字起こししてください。無添加のシャボン玉石けんならもう安心天然の保湿成分が含まれるため、肌に潤いを与え、健やかに保ちます。お肌のことでお悩みの方はぜひ一度無添加シャボン玉石けんをお試しください。お求めは 0120005595 まで。この結果はすごいですね。非常に明瞭な音声だからなのか、パーフェクトの文字起こしができています。しかも電話番号もきちんと聞き取れています。
文字起こしは日本語の精度が英語に比べてやや低いイメージでしたがPhi-4-multimodalだとかなり高精度で文字起こしをしてくれそうです。さすが音声関連のベンチマークで好成績を残しているだけのことはあります。
なお、テキストや人間の声から音声をクローンするZyphraAI Zonos-v0.1について詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事では、Phi-4-multimodalの概要から性能、Phi-4との違い、google colaboratoryでの実装方法についてお伝えをしました。
Phi-4-multimodalでは異なるモダリティの組み合わせで推論をすることができるので、将来的には実用的なAI診断アシスタントみたいなものも開発されるかもしれません。
例えばレントゲンやCT画像と患者の主訴を記録した音声データから診断補助を行ったりできるかもしれません。
ぜひ本記事を参考にPhi-4-multimodalを実装してみてください!
弊社では、Phi 3.5を活用したローカル環境でのデータ分析システムを開発しました。事例について詳しく知りたい方は以下の記事をご覧ください。

最後に
いかがだったでしょうか
Phi-4-multimodalの高精度な音声・画像・テキスト処理は、業務の効率化や顧客対応の最適化に貢献します。マルチモーダルAIを活用し、データ入力の自動化や意思決定の高度化を実現しませんか?
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

