
LMM(大規模マルチモーダルモデル)とは?LLMとの違いや代表モデルを解説

LMM(大規模マルチモーダルモデル)によって、我々の生活は一変するかもしれません。LMMとは、テキスト・画像・音声などの複数種類の情報を処理できるAIモデルのことです。
LMMを搭載したAIは人間に近い思考・判断ができると考えられており、将来的には自動運転技術や産業用ロボットなども実現可能なのだとか。すごくないですか!?
というわけで今回は、LMMの特徴やLMMでできること、LMMの代表例などを詳しく解説します。最後までご覧いただき、LMMに関する知見を深めてくださいね!
\生成AIを活用して業務プロセスを自動化/
LMM(大規模マルチモーダルモデル)とは?
LMM(大規模マルチモーダルモデル)とは、「テキストや画像、動画など、複数種類の情報を処理できるAIモデル」を指します。
似たような言葉でLLM(大規模言語モデル)というものがありますが、こちらのモデルはテキストの処理・生成しかできません。
例えば、無料版ChatGPTに搭載されているGPT-3.5は、テキスト処理しかできないのでLLMに分類されますね。
一方、GPT-4はテキストtoイメージ、テキストtoビデオなど、さまざまなモードに対応できるのでLMM(大規模マルチモーダルモデル)に分類されます。
LMMの場合、画像からテキストを生成したり、逆にテキストから動画を生成したりなど、種類の異なる情報も一緒に処理・生成が可能です。
処理できる情報の種類が増えたことで、LMMを搭載したAIはより人間に近い思考・判断ができるようになると期待されています。


シングルモーダルとマルチモーダルの違い
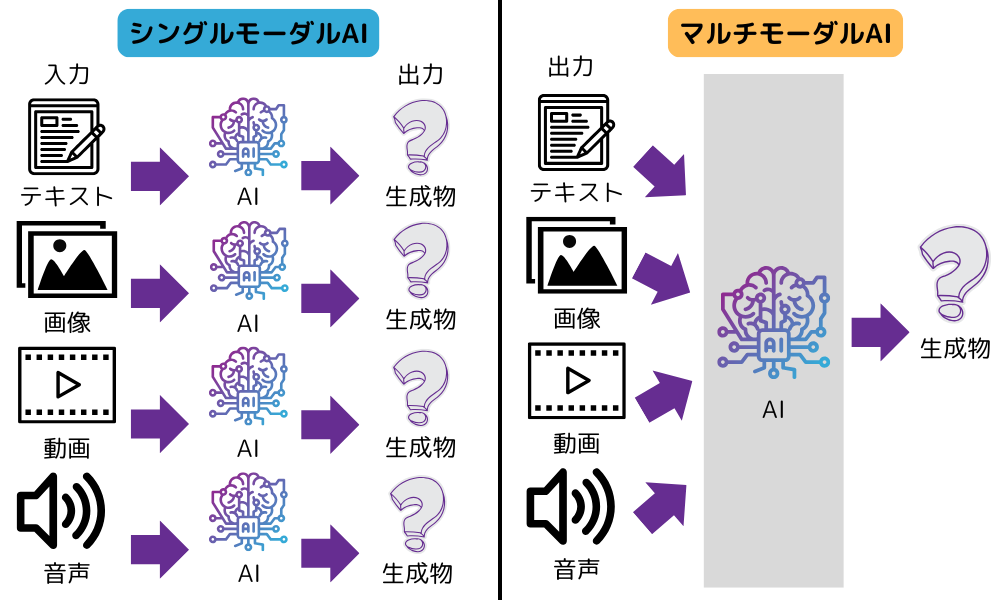
シングルモーダルとマルチモーダルの違いは、おもに入力できるデータの種類の数です。シングルモーダルは1種類、マルチモーダルは2種類以上のデータを入力して処理できます。
たとえば、テキストを入力してテキストを出力したり、テキストから画像を生成するといった、単一の情報を入力して処理する生成AIがシングルモーダルモデルです。
一方、テキストと画像を入力して、「画像内容を説明して」といった指示を処理できるのがマルチモーダルモデルになります。
LMM(大規模マルチモーダルモデル)にできること
LMM(大規模マルチモーダルモデル)にできることは下記のとおりです。
- テキスト・画像・動画・音声の双方向のやり取り
- AIの精度向上
- 高技能をスムーズに習得できる
- 人間に近い判断ができる
テキスト、画像、動画、音声の双方向のやり取り
LMMを用いれば、テキスト・画像・動画・音声の双方向のやり取りができます。
例えば、以下のようなタスクが実行可能です。
- 写真の情報をテキストで出力する
- 音声を自動的に文字起こしする
- 内容をテキストで入力して動画を作成する
- 画像から動画を生成する
上記のとおり、LMMを活用すればイラストの知識がない人でもイラストを描けるし、動画の知識がない人でも動画を制作できます。
つまりLMMによって、これまでは特別なスキルがないとできなかったことを、誰でも簡単にできるようになったのです。
AIの精度向上
LMMを導入することで、AIの精度が向上すると期待されています。LMMはテキストや画像、音声などを処理するため、より多くの情報に触れられます。触れる情報が多ければ、AIにインプットされる情報量も当然増え、結果的にAIの精度向上につながるのです。
以前までのAIは単一種類の情報にしか触れられなかったため、インプットできる情報量も限られており、その結果ハルシネーションを起こすことも多々ありました。
しかし、今後LMMの進化によってAIの精度が向上すれば、我々がAIを活用できるシーンも一気に増えるかもしれませんね。
高技能をスムーズに習得できる
LMMを導入することで、AIは高度な技能をスムーズに習得できます。これまでの単一情報しか処理できないLLMは、対処できるタスクも限られていました。無料版ChatGPTに搭載されているGPT-3.5の場合、テキストの処理・生成しかできません。
しかし、LMMであれば視覚や聴覚などさまざまな情報を取り込めるため、本来人間にしかできないような複雑なタスクにも取り組めるのです。例えば自動運転などの超高度な技術も、今後LMMが進化すれば可能になると考えられています。
人間に近い判断ができる
LMMを導入することで、AIはより人間に近い思考・判断ができるようになります。人間は物事をとらえるとき、五感(視覚・聴覚・嗅覚・触覚・味覚)で感じた情報を基に思考・判断しますよね?
これまでのLLMだと、処理できる情報の種類が限られていたため、どうしても人間と同じような思考・判断は難しいとされてきました。
しかしLMMの場合、視覚や聴覚などの情報も五感のように処理できるため、人間と似た思考・判断ができるようになるのです。実際、国内でも視覚や触覚情報を基に作動するロボットがすでに開発されています。
現時点では、ロボットが人間と完全に同じ動きをするのはまだ難しいですが、技術が進化すれば将来的には可能になるでしょう。
なお、ChatGPTを内蔵したロボットの事例について知りたい方はこちらをご覧ください。

代表的なLMM(大規模マルチモーダルモデル)
ここでは、現在世の中にあるLMM(大規模マルチモーダルモデル)の代表例を紹介します。
今回ご紹介するのは、以下8つのモデルです。
それぞれのモデルの特徴を詳しくみていきましょう。
GPT-4o
GPT-4oはOpenAI社が開発したLMMで、ChatGPTなどのAIツールに搭載されています。旧モデルGPT-4のときは、元々テキスト処理しかできないLLMでした。
しかしOpenAI社が2023年9月、新モデルの「GPT-4V」を発表し、画像解析機能と音声出力機能が追加されたのです。例えば、ChatGPT上に画像をアップロードして、「これはなんですか?」と質問すると…
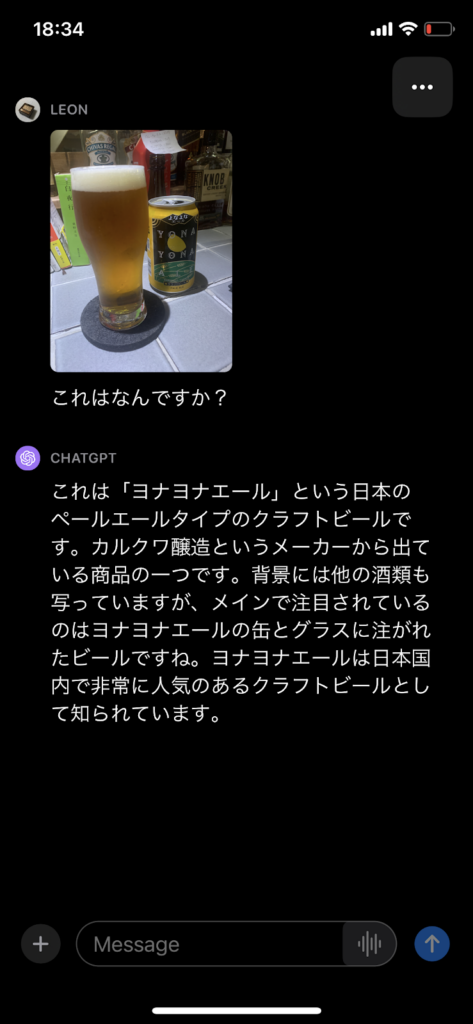
このように画像の内容をテキストで出力してくれます。これは言うなれば、ChatGPTに目と声が実装されたようなものですね!
さらにChatGPTでは、画像生成AIの「DALL-E 3」が使えるようになり、テキストから高品質な画像が簡単に生成できるようになりました。
また、GPTsの機能が実装されたことにより、誰でもノーコードで簡単にオリジナルのチャットボットを生成できるようになっています。
現在、ChatGPTの最新モデルとしてGPT-4oが登場しており、タスクの処理速度や精度が旧モデルよりも向上しています。
今後さらにLMMが進化することで、ChatGPTはますます便利なツールになるかもしれませんね!
Gemini
Geminiは、Google社が開発した対話型のLMMです。元々はBardという名前で提供されていましたが、Googleがあとから開発したGeminiにモデルが置き換わったことでサービス名も変わりました。
なお、GeminiもGPT-4と同じくテキスト処理に特化したLLMでしたが、2023年9月に大幅なアップデートが行われ、Googleレンズによる画像認識が可能になっています。例えば、写真をアップロードして「これはどういう写真ですか?」と入力すると…
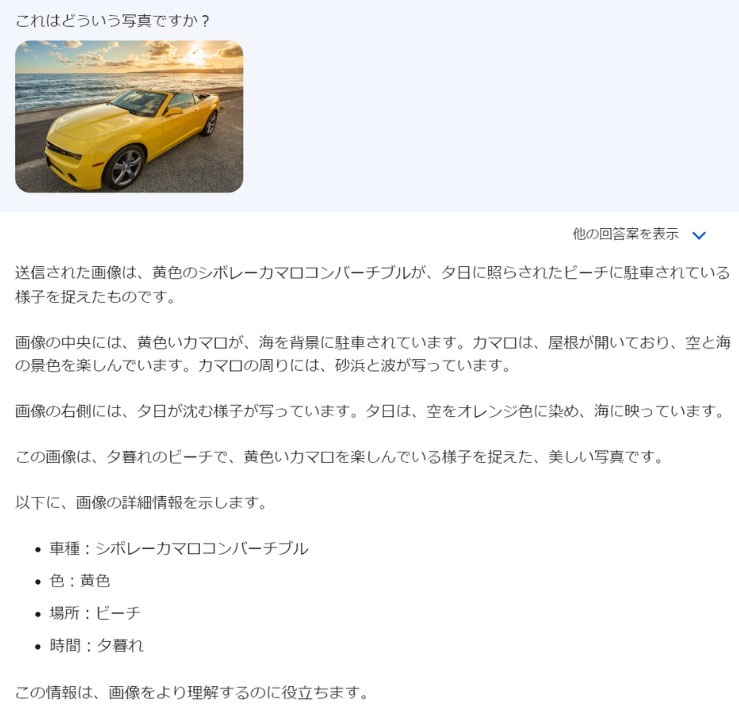
このように、画像の内容をテキストで出力してくれるのです。さらにGeminiでは、拡張機能によるGmailやドライブとの連携、ハルシネーションチェックも可能になりました。
Gemiiは誰でも無料で利用できるサービスなので、興味のある方はぜひお試しください!
なお、Gemini(旧GoogleBard)について知りたい方はこちらをご覧ください。

Copilot(BingAI)
BingAIに搭載されているCopilotの機能を使えば、テキストと画像を入力できるマルチモーダル機能が使えます。ちなみに、Copilotとは、Microsoftが開発したAIアシスタントです。
Copilotを利用する際は、BingAIのトップページ上部にある「Copilot」を選択します。
その後、チャット画面に入れるので、気になるトピックについて質問してみてください。
今回、筆者は猫の画像を入力して、その画像に写っている動物がなんなのか質問してみました。
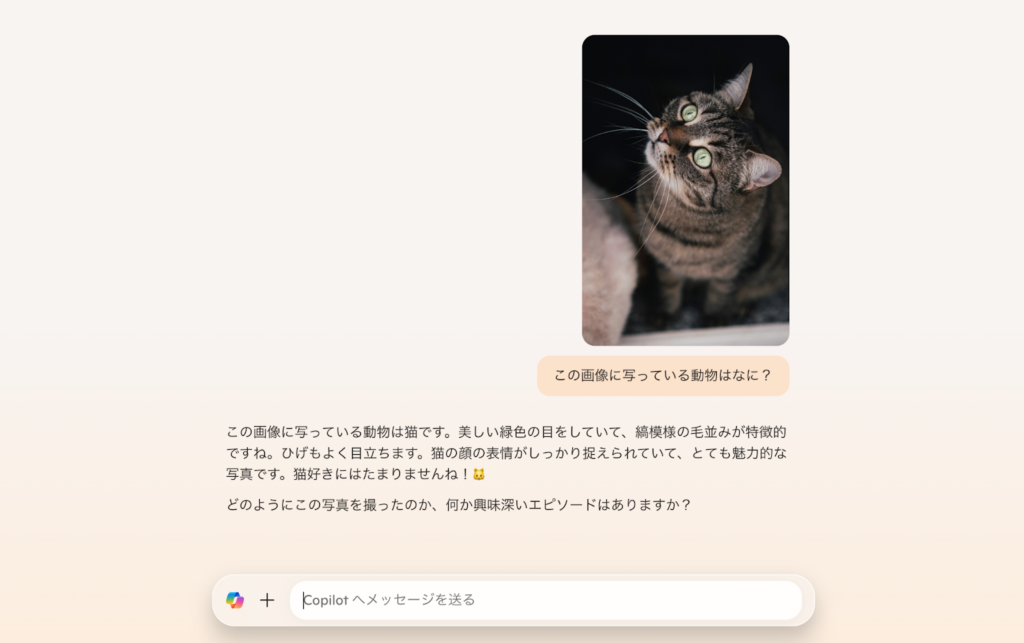
Copilotからは、しっかり猫である旨が回答されているので、画像認織精度の高さが伺えますね!
なお、Copilot(BingAI)について詳しく知りたい方は以下の記事をご覧ください。

Copilotでマルチモーダル機能を無料で使いたい方は、以下の記事もご覧ください。

SeamlessM4T
SeamlessM4Tは、FacebookでおなじみのMeta社が開発した翻訳LMMです。SeamlessM4Tを使うことで、下記のようなタスクを実行できます。
- 音声から音声への翻訳(Speech-to-speech translation )
- テキストから音声への翻訳(Speech-to-text translation)
- テキストからテキストへの翻訳(Text-to-text translation)
- 自動音声認識 (Automatic Speech recognition)
例えば、「おはよう」と音声入力して英語に翻訳すると、「Good Morning」というテキストと音声が一緒に出力されます。
ちなみに、SeamlessM4Tに対応している言語数は下記のとおりです。
| タスク | 対応言語数 |
|---|---|
| 音声入力 | 101 |
| 音声出力 | 35 |
| テキスト入力/出力 | 96 |
これだけの言語に対応していれば、今後は日本語だけで世界中どこでも生活していけるかもしれませんね!
NExT-GPT
NExT-GPTは、テキスト・画像・動画・音声すべてに対応しているLMMです。
具体的な使い方として、例えばNExT-GPT上で「犬が笑っている動画を生成できますか?」と入力すると…
このように若干精度に問題はあるものの、あっという間に動画を作成してくれます。他にもテキストから画像を生成したり、動画からテキストを生成したりなど、多種多様なタスクに対応可能です。
現時点でNExT-GPTはデモ版しか公開されていませんが、誰でも利用できるのでぜひ試してみてください!
CoDi
CoDiはMicrosoft社が開発したLMMです。CoDiの大きな特徴は、「1つのプロンプトからテキスト・画像・動画・音声を同時に生成できる」という点。
例えば、CoDi上で「美しい森の中を歩いていると、自然と鳥の音が広がっています。」とプロンプトを入力すると…

このように、音声と動画を同時に生成してくれます。
まだ若干精度に課題があるものの、たった1つのプロンプトで複数のタスクを実行してくれるのは非常に便利ですよね!
CogVLM
CogVLMは、画像の認識・言語化が可能なLMMです。
その精度は非常に高く、一説によるとGPT-4Vを超えているのだとか。例えば、CogVLM上に画像をアップロードし、「この画像を説明してください」とプロンプトを入力すると…
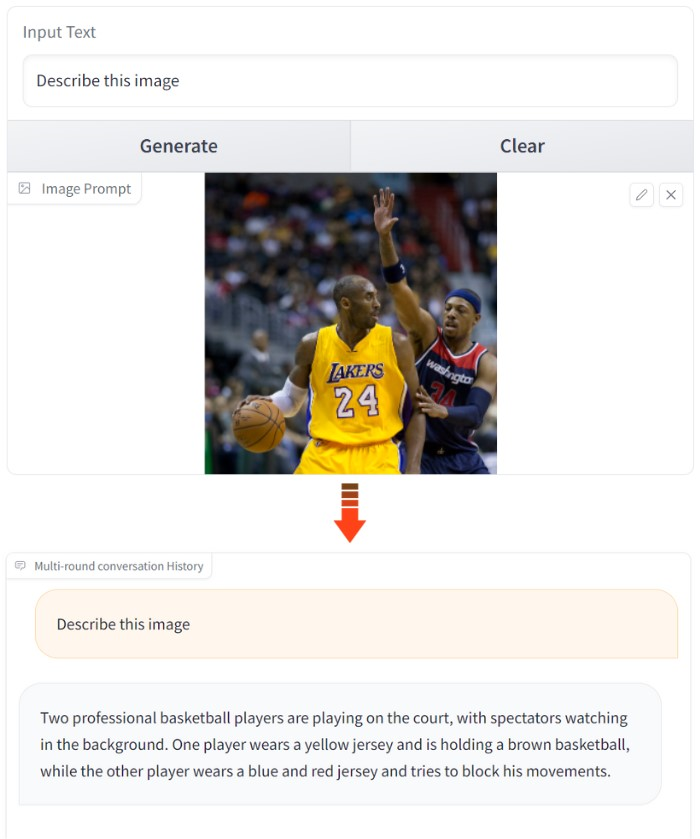
このように、画像の内容をテキストで出力してくれるのです。
今後CogVLMの精度がさらに上がれば、難易度が超高いことで有名なサイゼリヤの間違い探しなんかも、一瞬でできるようになるかもしれませんね。
LLaMA3
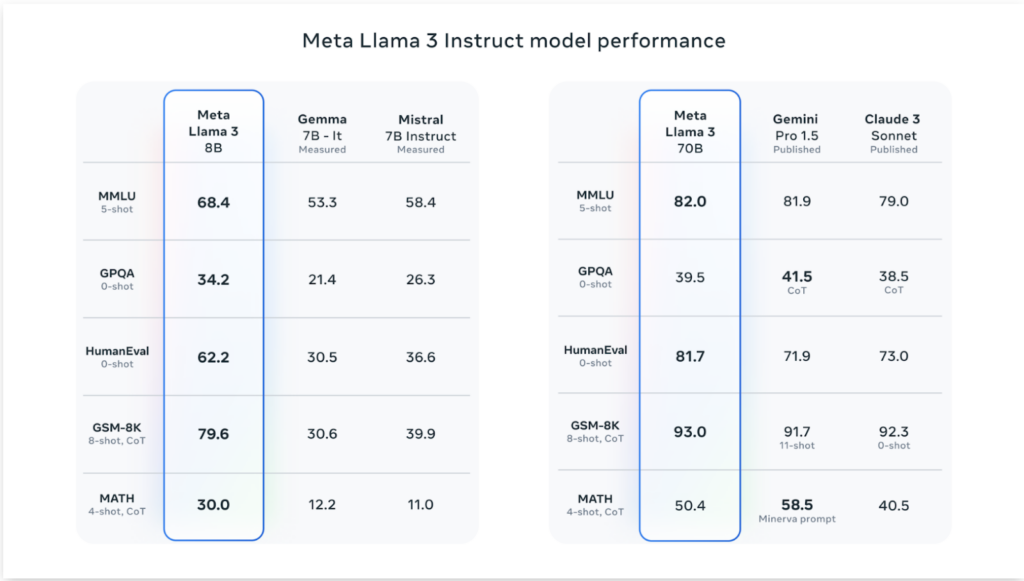
LLaMA3は、Meta社が開発したLLaMAシリーズの最新モデルです。前のモデルであるLLaMA2も高性能なLMMとして有名でしたが、LLaMA3はさらにその上をいきます。
その実力はなんと、オープンソースモデルでありながらGemini Pro 1.5やClaude 3 Sonnetを凌駕する性能を備えているほど。
たとえば、「回帰分析のコードを書いて」とプロンプトを入力すると、以下のように返ってきます。
ここでは、人気のあるscikit-learnライブラリを使用して、Pythonで単純な線形回帰分析を実行する方法の例を示します
# Import necessary libraries
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load your dataset into a Pandas DataFrame
df = pd.read_csv('your_data.csv')
# Define the feature(s) and target variable
X = df[['feature1', 'feature2', ...]] # features
y = df['target'] # target variable
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train a linear regression model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions on the testing set
y_pred = model.predict(X_test)
# Evaluate the model using metrics such as Mean Squared Error (MSE) and R-squared (R2)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'MSE: {mse:.2f}')
print(f'R2: {r2:.2f}')
# You can also use the `score` method to get the R2 value directly from the model
r2_alt = model.score(X_test, y_test)
print(f'R2 (alternative): {r2_alt:.2f}')
このコードでは、各行がサンプルを表し、各列が特徴またはターゲット変数を表すデータを含むCSVファイルを持っていることを想定しています。’your_data.csv’`をデータセットファイルへの実際のパスに置き換える必要があります。
このコードをカスタマイズすることができます:
X` データフレームにフィーチャーを追加または削除する。
train_test_splitのtest_size` パラメータを変更して、テストに使用するデータの割合を制御します。
モデルのパフォーマンスを評価するために、異なる評価指標を使用したり、評価指標を追加したりします。
scikit-learn から異なるクラスをインポートして使用することによって、異なるタイプの回帰モデル(例えば、多項式回帰、リッジ回帰など)を試します。
何か質問があったり、さらにサポートが必要な場合は、私に知らせてください!コードについて丁寧に説明してくれるので、かなり親切ですよね。最新のLLMを使ってみたい方は、ぜひチェックしてみてください。


マルチモーダルAIの将来性
LMM(大規模マルチモーダルモデル)が今後進化し続ければ、AIは人間の五感と遜色ない働きができるようになるでしょう。そうなると、我々の生活は間違いなく大きく変化します。
例えば自動車にLMMを搭載すれば、周囲の交通状況を視覚・聴覚で適切に判別できるので、自動運転技術も可能になるかもしれません。
また、視覚・触覚情報を基に作業を行うロボットが開発され、人手不足が叫ばれる産業分野の救世主になるかもしれません。
なお、マルチモーダルAIについて知りたい方はこちらをご覧ください。

LMM(大規模マルチモーダルモデル)の進化から目が離せない!
LMM(大規模マルチモーダルモデル)とは、「テキストや画像、動画など、複数種類の情報を処理できるAIモデル」を指しています。
LMM(大規模マルチモーダルモデル)にできることを再度まとめました。
- テキスト・画像・動画・音声の双方向のやり取り
- AIの精度向上
- 高技能のスムーズな習得
- 人間に近い判断
LMMが今後進化し続けると、AIは人間の五感と遜色ない働きができるようになると考えられます。そうなると、将来的には自動運転技術や産業用ロボットの普及も実現するかもしれませんね!
なお、LMM(大規模マルチモーダルモデル)の代表モデルを以下にまとめました。
- GPT-4o
- Gemini
- Copilot(BingAI)
- SeamlessM4T
- NextT-GPT
- CoDi
- CogVLM
- LLaMA3
LMM(大規模マルチモーダルモデル)が進化すれば、我々人類の生活は間違いなく一変します。
今後のLMM研究・開発の動向から、ますます目が離せませんね!

最後に
いかがだったでしょうか?
LMMの進化に触れ、次世代のAI技術がもたらすビジネスチャンスを活用する準備を始めましょう。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

