
【やってみた】GPT3.5 Turboのファインチューニングで岸田総理ボット開発するまで

2023年8月23に、OpenAIがAPIのアップデートを発表しました。まさかのGPT-3.5 Turbo モデルがファインチューニングに対応!弊社エンジニアは大喜びです!
ですが、大半の方は「ファインチューニング、なにそれ、美味しいの?」と思っていると思います。そこで今回はアップデートの概要・ファインチューニングする方法・実際にモデルを使ってみた感想をわかりやすくご紹介します。
今回は、実際に首相ボットを作ってみましたので、ぜひ楽しんでご覧ください!首相ボットのみ見たい方は、目次から「GPT-3.5 Turboのファインチューニングを使って首相ボットを作ってみた」に飛んでください!
\生成AIを活用して業務プロセスを自動化/
GPT3.5 Turboのファインチューニング機能の概要
今回、OpenAI はモデルのファインチューニング機能を発表しました。ファインチューニングとは、モデルを特定のタスクに特化させるための追加学習(事後学習)です。
イメージとしては、幅広い知識を持っているGPTモデルに、特定の業界や分野の専門知識を学ばせていきます。次のようなユースケースでファインチューニングは活用可能です。
- 医療: 医療用語や症状、治療法に関する専門的な知識を持つボット
- 法律: 法律や規定、条例に関する質問に答えるボット
- 技術サポート: 特定の製品やソフトウェアのサポートをするボット
ではなぜ、ファインチューニングが必要なのか。それは、今までやっていたプロンプトエンジニアリングより効果的にGPTモデルの精度を上げられるからです!
AIモデルにおいて、特定タスクの精度を良くするためには、以下の3つの手法があります。
- データの学習をもとにいいモデルを作る(事前学習)
- できたモデルを調整する(ファインチューニング)
- よりよいプロンプトを入力する(プロンプトエンジニアリング)
今までは、3番のプロンプトエンジニアリングしかできませんでした。プロンプトエンジニアリングでは、few shot leraningという手法で少量のデータを学習させています。
しかし、精度を上げる(ほしい出力を得る)のは比較的難しいです。大量に学ばせることもできますが、文字数(トークン数)が増えるとともにAPIの利用料も増える事態になってしまいます。
ここで、ファインチューニングが活躍するのです!ファインチューニングには次のようなメリットがあります。
- 大量のデータをモデルに追加学習できるので、高精度な結果が出やすい
- プロンプトの量が減るため、トークンの節約になる
- 特定タスクに特化しているので、レスポンスが速くなる
ありがたいですね!


ChatGPTのモデルの種類
ChatGPTには、多くの機能や幅広い価格帯を備えたモデルが公開されており、大きく分けて6つあります。無料でも使用できるモデルと、課金しないと利用できないモデルに分けて表を作成しています。
それぞれの特徴をまとめたので参考にしてください。
無料でも使用できるモデル
| モデル名 | 特徴 |
|---|---|
| GPT-3 | 自然言語やコードを処理できる大規模言語モデル |
| GPT-3.5 | GPT-3を改良したモデルで自然言語やコードを処理できる大規模言語モデル |
課金をしないと使用できないモデル
| モデル名 | 特徴 | 料金 |
|---|---|---|
| GPT-4 | GPT-3.5を改良した最新モデル 自然言語や画像、コードを処理でき、テキストだけでなく画像プロンプトを受け入れるマルチモーダルな大規模言語モデル | 月額20ドルのChatGPT Plusから使用可能 API利用時、1000トークン当たり0.06ドル |
| GPT-3.5 turbo | GPT-3.5のなかで一番高性能なモデルファインチューニング可能 | API利用時、1000トークン当たり0.002ドル |
| text-davinci-003 | GPT-3.5 turboの次に優秀なモデル | API利用時、1000トークン当たり0.002ドル |
| text-davinci-002 | text-davinci-003の旧モデル教師ありファインチューニングを採用 | API利用時、1000トークン当たり0.012ドル |
※詳しい料金を知りたい方は、こちらをご覧ください。
みなさんは、GPT-3.5やGPT-4の名前を多く聞いたことがあるのではないでしょうか?
GPT-3.5とGPT-4の違いは、月額料金の有無や画像プロンプト対応の有無などです。また、パラメータ数やトークン数などが異なり、GPT-4の方が多くの情報を取り扱っています。さらに、いつまでのデータを取得しているかもGPT-3.5とGPT-4は異なるのです。
そして、GPT-3.5とGPT-4以外にも上記のように多くのChatGPT言語モデルが存在しています。紹介したモデルの中でファインチューニングが可能なのは、以上の2つのモデルのみです。
- GPT-3.5 turdo
- text-davinci-002
そこで今回は、GPT-3.5 turboを使用したファインチューニングについて解説します。
なお、ChatGPT APIの詳細について知りたい方はこちらをご覧ください。

GPT3.5 Turboのファインチューニングの活用できる例
GPT-3.5Turboのファインチューニングの活用例は下記の4つです。
- ビジネス用途のチャットボット
ビジネスに特化したチャットボットを作成できます。例えば、顧客サービスにおいてよくある質問に対する自動応答を高度にカスタマイズできます。 - 個性を持つチャットボット
ユーザーが楽しめるような個性豊かなチャットボットを作ることが可能です。具体的には、特定のキャラクターのような口調やスタイルで対話するボットを設計することが可能になります。 - 特定のタスクに焦点を当てたAIアシスタント
医療用語に精通したAIアシスタントや、特定のプログラミング言語でのコーディングを補助するAIを設計できます。 - 出力の精度が重要なユースケース
高度な分析やレポート作成など、出力の精度が非常に重要な場合には、ファインチューニングでモデルの精度を向上させることが可能です。例をあげると、金融分析において、特定の指標に基づいて詳細なレポートを生成するようにモデルを調整できるなどです。
上記のようなファインチューニングの活用例が考えられます。GPT-3.5Turboのファインチューニングは、多様な用途で活用可能です。
ビジネス向けのチャットボットから個性的な対話ボット、特定タスクに特化したAIアシスタントまで、高度にカスタマイズできます。さらに、出力の精度が重要な場合も、企業はこれを利用してより指示に忠実なAIモデルの設計が可能です。
ファインチューニングの使用料金
ファインチューニングの使用料金は、初期学習コストと使用コスト(入力テキストと出力テキスト)の2つに分けられます。ファインチューニングの使用料金は以下の通りです。
- 学習:$0.008/1K Tokens
- 入力テキスト:$0.003/1K Tokens
- 出力テキスト:$0.006/1K Tokens
例えば、100,000トークンの学習にかかる予想コストは約0.8ドルになります。100,000トークンの入力テキストの場合0.3ドルになり、100,000トークンの出力テキストだと0.6ドルのコストがかかります。
使用料金に関する注意点
ファインチューニングを利用する際に注意すべきなのは、気づかないうちに利用料金が高くなる点です。トレーニングデータにもコストがかかるので、大量のデータを使う場合は、事前におおよその費用を計算しておきましょう。
また、費用を抑制するための方法は、主に2つ考えられます。
- 利用金額の上限を設定する
OpenAIのAPI利用料金は上限を設定することができ、使いすぎを抑えられます。 - トレーニングデータを英語で作成する
APIの料金は1000トークンごとに計算されるため、トークン数が少ないほど料金も安くなります。日本語より英語の方がトークン数は少なくなるため、英語の方が経済的です。しかし、日本語での回答が必要な場合は、精度が落ちないか確認してください。
ファインチューニングのコストは意外に高くなる可能性があります。初期学習とテキストの入出力それぞれに料金がかかるため、事前にしっかりと費用計算を行いましょう。
そして、Open AIではなく、Azure Open AI serviceでファインチューニングを利用する際は別料金に注意してください。Azure Open AI serviceとは、Microsoft社提供のクラウドサービスであるAzure上で利用できるAIサービスです。
機能面はほぼ同じですが、Azureでファインチューニング済みのモデルを配置すると、1時間あたり3ドルが常に発生します。
ファインチューニングの安全性
結論から言うと、ファインチューニングの安全は確保されています。なぜなら、ファインチューニングを行う際には「モデレーションAPI」と「GPT-4のモデレーションシステム」を使って学習データが送られるからです。
このシステムにより、安全でない学習データがあれば検出され、OpenAIの安全基準に違反するようなデータは排除されるため、安全性が確保されているとOpenAIが説明しています。また、ファインチューニングで使われる全てのデータは顧客が所有しており、OpenAIや他組織がそれを他モデルの学習に用いることはありません。
これらの保証によって、開発者は自分たちの要求に完全に合ったAIモデルを安心して作成し、性能を最適化できるのです。
ファインチューニングの注意点
次に、ファインチューニングを実際に使用するときの注意点を3つ紹介します。ファインチューニングの機能を存分に活用するためには、使い方が重要です。
使い方が悪いと、ファインチューニングの効果やメリットが得られなくなってしまいます。ぜひ、注意点を参考にしてファインチューニングを活用してください。
学習済みモデルの全層の更新は避ける
ファインチューニングを行う際には、学習済みモデルの全層を更新するのではなく、特定の層だけを更新するのが一般的です。全結合層を持つ深層学習モデルの数は多く、各層の出力と入力が密接に関連しています。全層を更新すると、モデルが既に学習した知識を失ってしまう可能性が高くなるのです。
例えば、あなたが英語の文法を勉強した後にフランス語の文法を一緒に学ぼうとすると、英語の文法を忘れてしまう可能性がありますよね?AIも同様に、モデルの全層を更新すると既に学習した部分を忘れてしまう可能性が高くなります。
そのため、全層を更新すると、新しくモデルを学習させるのと同じような状態になり、ファインチューニングのメリットが失われてしまうので注意が必要です。
学習率を小さく設定する
ファインチューニングを行うときは、過学習を防ぐために学習率を小さく設定するのが重要です。一部の層の重みを固定すると、実際に学習する層の数が少なくなります。この状態で学習率が高いと、限られた層で大きな変更が起き、過学習が起こりやすくなるのです。
例えば先端の層を固定して中間層だけを学習させる場合、その中間層で急激な重みの変化が起きる場合を考えてください。モデルが特定のデータに過度に適応してしまい、新しいデータに対する性能が落ちてしまうのです。
そのため、学習率を低く設定して、モデルの重みを穏やかに更新することが推奨されます。このようにして、過学習を防ぎながら効果的なファインチューニングを行いましょう。
なお、ファインチューニングについて知りたい方はこちらをご覧ください。

GPT-3.5 Turboのファインチューニングのやり方
今回は、岸田文雄総理の発言を100個あつめて、モデルをファインチューニングします。プログラムも公開しているので、参考にしていただけますと幸いです。
まずはファインチューニングに必要なデータの形式についてです。以下のような、systemプロンプト、userの質問、aiの回答を持ったmessages配列を縦に並べてjsonlファイルを作ります。
{"messages":
[
{
"role": "system",
"content": "あなたは岸田文雄さんです。日本の政治家です。"
},
{
"role": "user",
"content": "このプロジェクトの具体的な内容は何ですか?"
},
{
"role": "assistant",
"content": "これはエネルギー安定供給上、我が国にとって重要なプロジェクトであると認識いたしております。"
}
]
}こちらが今回使ったjsonファイルです。
それでは、学習を始めましょう!まずは、こちらのGoogle Colabにアクセスします。
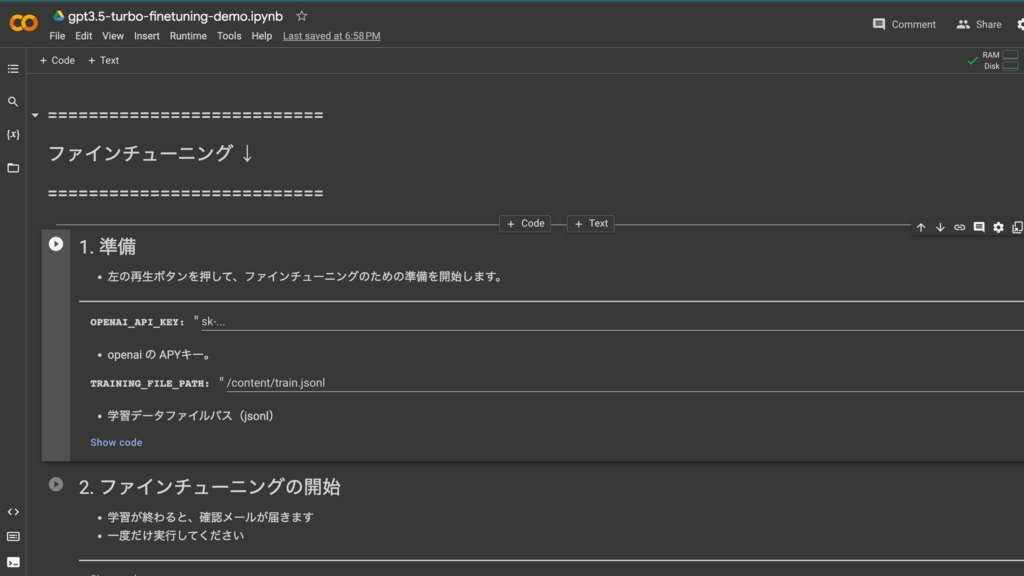
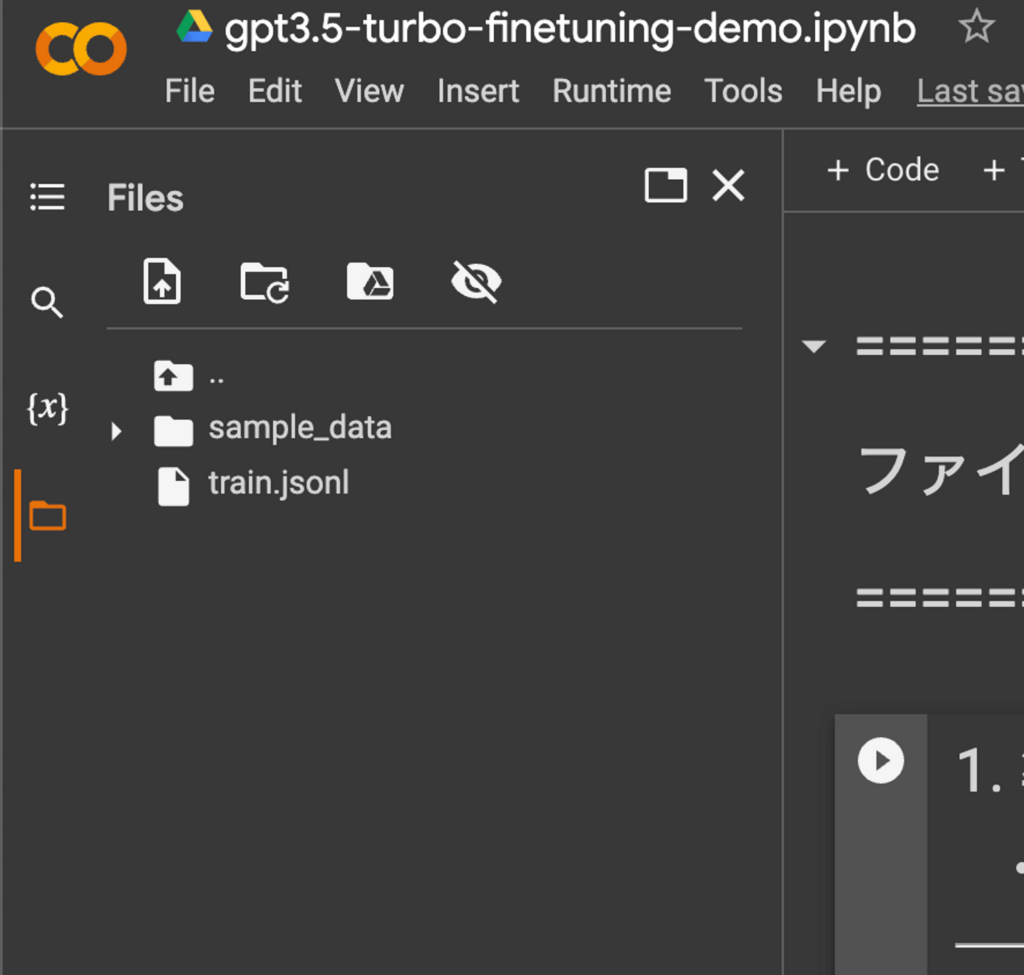
次にGoogle Colabに学習データのtrain.jsonlをアップロードします。
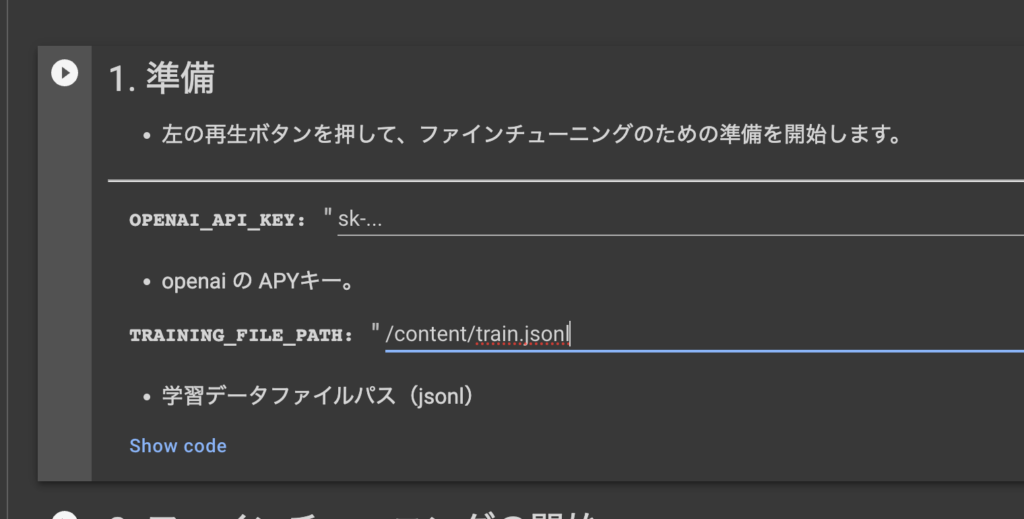
OpenAI APIキーと学習データのパスを入力します。
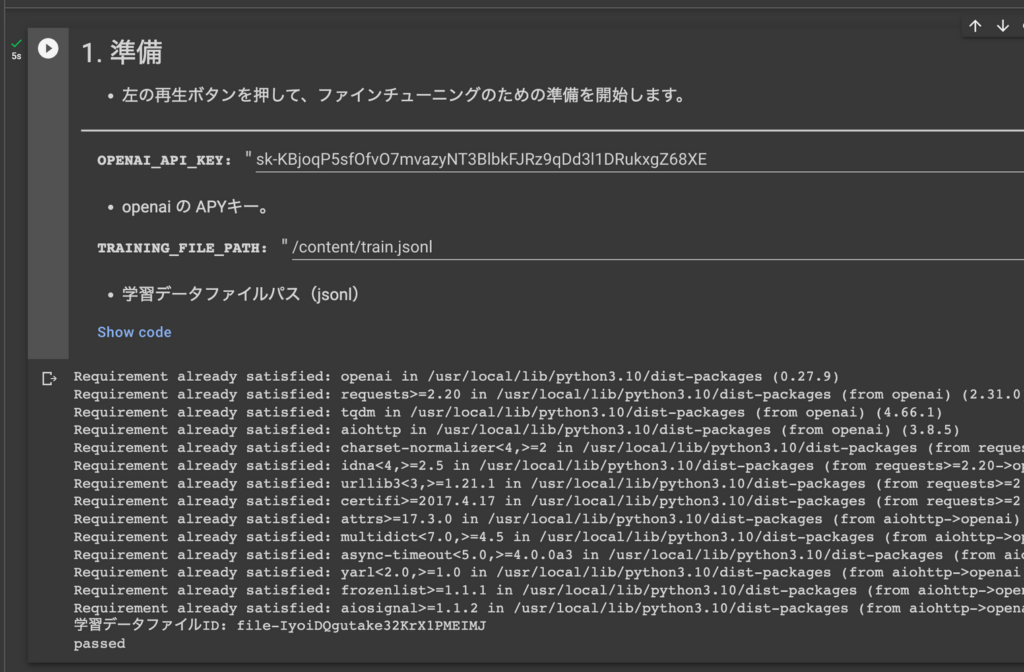
準備を実行します。passedが表示されたら成功です!
ファインチューニングを開始します。再生ボタンをクリックしましょう。
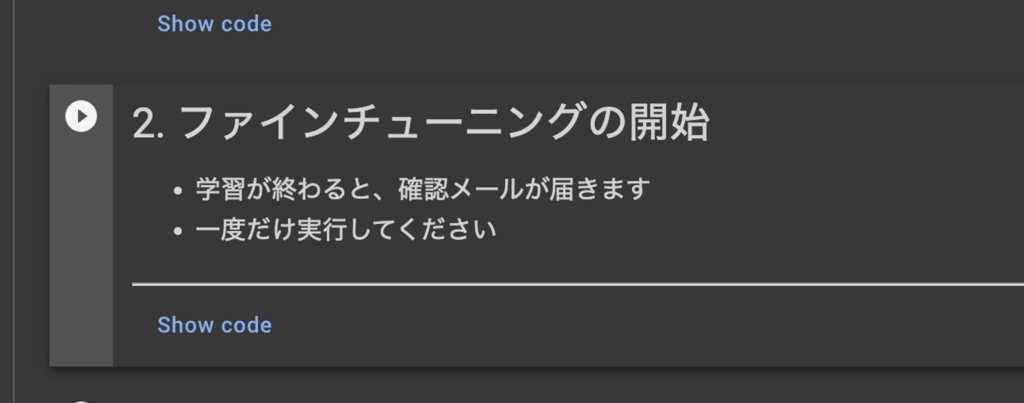
学習経過を確認しステータスがsucceededになるまで待ちましょう。succeededになるとファインチューニングは終了です。
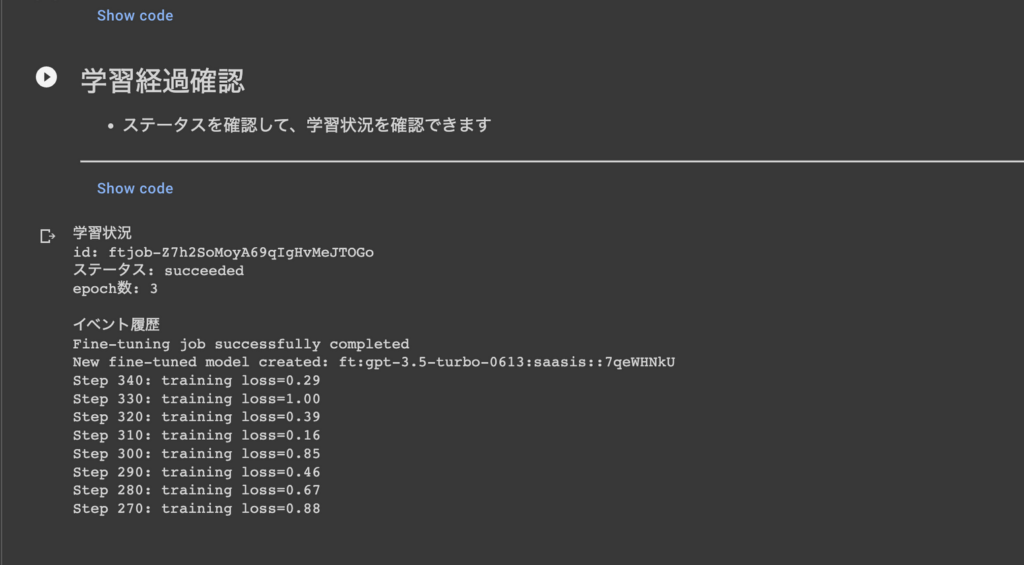
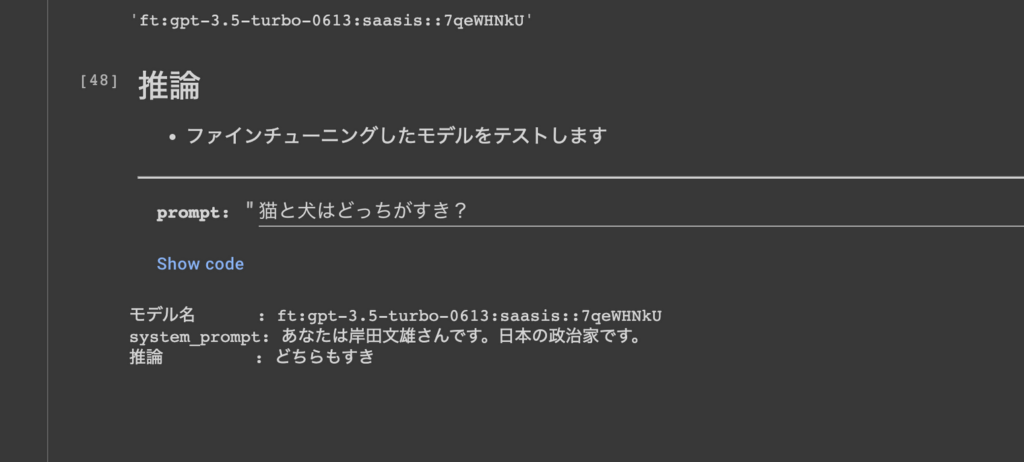
モデル名を確認します。

推論のテストをします。今回は、「猫と犬はどっちがすき?」と質問してみたところ、「どちらもすき」と返答がありました!
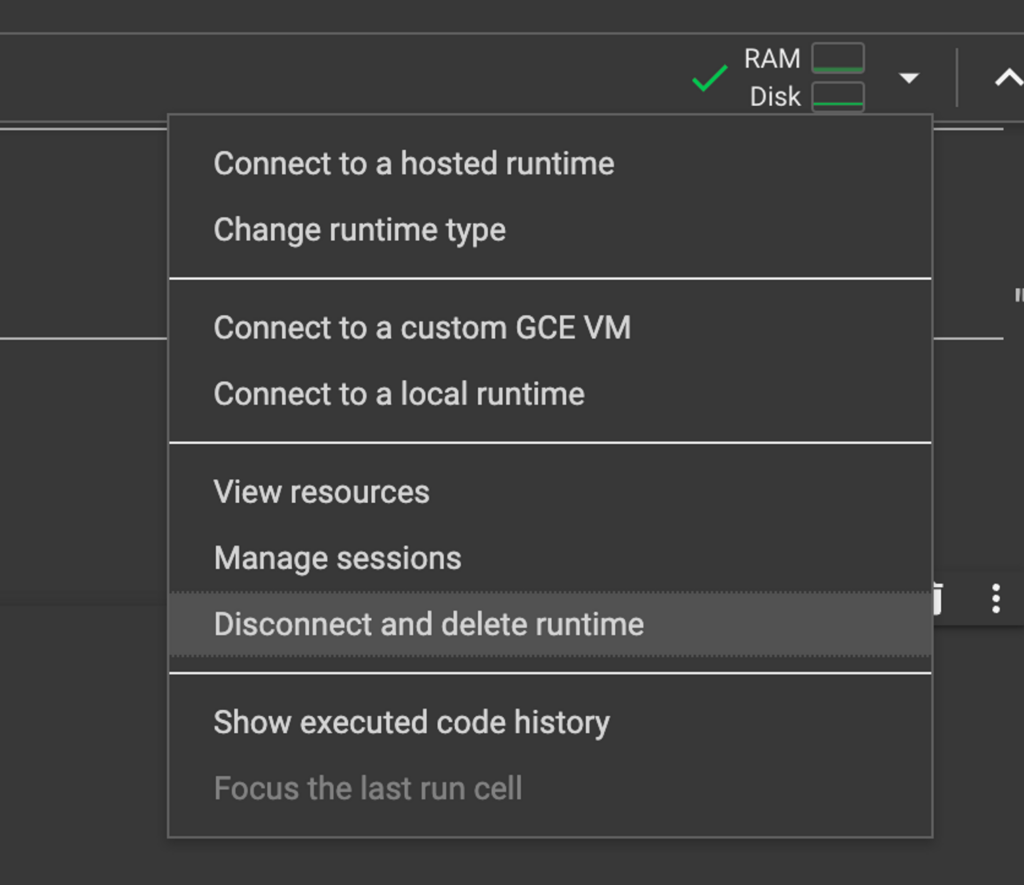
質問が終わったら、右上のボタンから”Disconnect and delete runtime”からランタイムを削除。
以上で導入は終了です。次は、いくつかプロンプトを試してみましょう!
GPT-3.5 Turboのファインチューニングを使って首相ボットを作ってみた
3つのプロンプトを入力してみました。
- ご飯にする?それとも私にする?
- ガソリン補助金より減税してくれませんか
- 先日、東京大学で受講されたAIに関する講義はいかがでしたか?
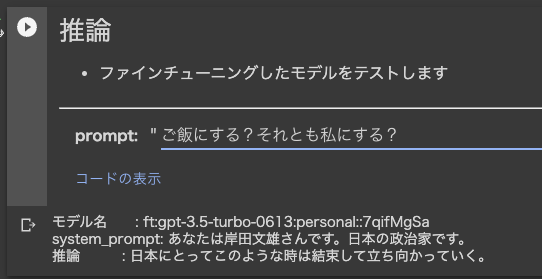
プロンプト1:ご飯にする?それとも私にする?
「日本にとってこのような時は結束して立ち向かっていく」
と回答。
頼もしいですね!ご飯にするか私にするか迷った時は、結束して立ち向かっていきましょう!
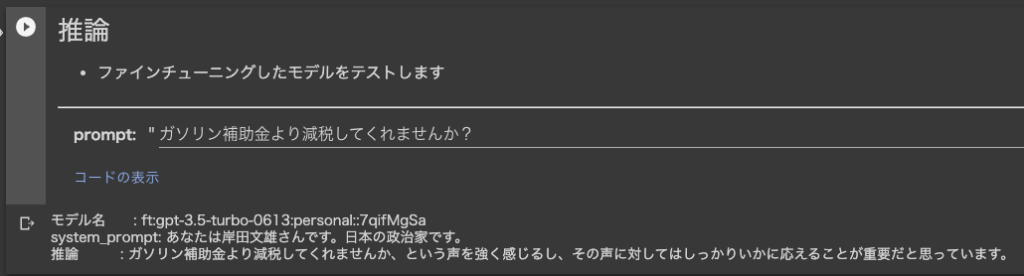
プロンプト2:ガソリン補助金より減税してくれませんか
「ガソリン補助金より減税してくれませんか、という声を強く感じるし、その声に対してはしっかりいかに応えることが重要だと思っています」と回答。
対応のほど、よろしくお願いします!
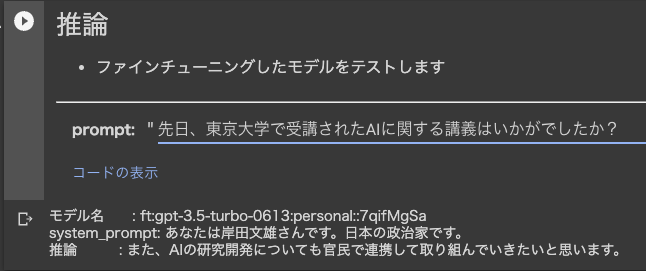
プロンプト3:先日、東京大学で受講されたAIに関する講義はいかがでしたか?
「また、AIの研究開発についても官民で連携して取り組んでいきたいと思います」と回答。
ぜひ日本をAI大国にしましょう!
なお、チャットボットが作れるDocsBotについて知りたい方はこちらをご覧ください。

OpenAIのファインチューニング機能を上手に活用しよう!
今回は、OpenAI が発表したファインチューニング機能についてまとめました。
概要
ファインチューニング機能は、GPTモデルを特定のタスクや分野へ特化させることが可能です。ファインチューニングできると以下のメリットがあります。
- 大量のデータを追加学習できるため、高精度な結果が出やすい
- プロンプトのトークン数を節約できる
- 特定タスクに特化させることでレスポンスが速くなる
ますますAI活用が広がっていくことでしょう。
導入
今回は、岸田総理大臣の発言をモデルに追加学習させるプログラムをもとにご紹介しました。こちらのGoogle Colabをご参照ください。
実際に動かしてみた
実際に動かす際は、以下の3つのプロンプトを入力しました。
- ご飯にする?それとも私にする?
- ガソリン補助金より減税してくれませんか
- 先日、東京大学で受講されたAIに関する講義はいかがでしたか?
それぞれへの回答はこちらです。
- 日本にとってこのような時は結束して立ち向かっていく。
- ガゾリン補助金より減税してくれませんか、という声を強く感じるし、その声に対してはしっかりいかに応えることが重要だと思っています。
- また、AIの研究開発においても官民と連携をして取り組んでいきたいと思っています。
首相らしさを追加学習できているなと感じました。ぜひファインチューニングを活用して、GPTモデルの精度を上げましょう。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

