
OpenAIを超えた?!話題の中国最強LLMまとめ!オープンソース化の理由も解説

現在多くの生成AIが発表されており、様々な分野で応用され始めています。ChatGPTは生成AIの代名詞となり、その性能や可能性が広く認知されました。
生成AIの開発には高度な技術と大量のデータが必要で、世界的に競争が激化しています。今回取り上げる中国では、国家レベルでAIの開発を支援する政策を打ち出し、多くのテック企業や研究機関が生成AIの開発に取り組んでいます。
ここでは、中国のAI業界で活躍する企業、および高精度のLLMモデルについて紹介いたします。
意外と知られていない「中国産LLMのオープンソース化戦略」についても解説しているので、ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
中国の有名なLLM開発企業
中国では、国家レベルの取り組みとして2017年に「次世代AI発展計画」が発表されて以降、多くの企業や研究機関が生成AIの開発に注力しています。
生成AIを開発している会社は数多く有りますが、その中でもChatGPTを開発したOpen AIにも劣らないと思われる高精度の生成AIを発表している会社も存在します。今回は高精度の大規模学習モデル(LLM)を開発している会社を紹介します。
アリババ

アリババグループは中国を代表する世界的なテクノロジー企業です。
もちろん生成AIの開発にも力を入れており、2023年には画像を生成するAI「通義万相」や、精緻な文章などを作成できる生成AI「通義千問」を開発しています。
また、生成AIの導入を支援するサービスも始めています。
バイドゥ

バイドゥは、中華人民共和国で最大の検索エンジンを提供する会社で、全世界の検索エンジン市場においてGoogleに次いで第2位となっています。
バイドゥはAI技術にも力を入れており、その一環として「文心一言」(Ermie Bot)という会話型AIを開発しました。また、AI解放プラットフォームを提供もしています。
バイトダンス

バイトダンス(ByteDance)は、中国のテクノロジー企業で、TikTokや抖音(Douyin)などのショートビデオアプリを運営しており、生成AI「Magic Animate」を発表しています。
また、ニュースアプリではToutiaoやTopBuzz等のアプリを提供しており、AIを活用してユーザーの興味・嗜好に合わせた配信を行っています。
テンセント

テンセント(Tencent)は、中国を代表する大手IT企業で、SNSやゲーム、クラウド事業など幅広い分野でサービスを展開しています。特に「WeChat(微信)」は中国国内で最も利用されるメッセージアプリとして知られ、日常生活やビジネスに欠かせない存在となっています。
AI分野においても積極的に研究開発を行っており、自社クラウドを基盤にした大規模言語モデル「混元(Hunyuan)」を発表しました。Hunyuanは1000億以上のパラメータを持つとされ、複雑な文章生成や数理問題の処理に強みを持っています。また、テンセントクラウドのAPIを通じて企業向けのAI活用を支援し、金融・教育・医療など幅広い分野で導入が進められています。


ChatGPTと並ぶレベルの中国産生成AI
中国の生成AIはソリューションの形で提供することを想定されています。このため特定の業界や企業に向けたAIモデルを開発し、そのニーズに応えることを目指していて、チャットボットという公開の仕方には消極的でした。
しかし、ChatGPTのブームを受けて、中国のテック企業もチャットインターフェースをつけた生成AIを発表するようになりました。ここでは、ChatGPTと並ぶレベルの中国産生成AIを紹介いたします。
文心一言(Ernie bot)
「文心一言」はバイドゥが発表した対話型生成AIです。文章作成能力の他、画像生成機能を持つ。
総合的な能力はChatGPTに及ばないものの、中国語においては高い言語処理能力を持ちます。
文心一言 のLLMの学習データは、数兆件のウェブデータ、数十億件の検索データや画像データ、1日平均数百億件の音声通話データ、5,500億件の事実に関する知識グラフとされている。
通義千問(Qwen)シリーズ
Qwenシリーズはアリババが開発したLLMのシリーズです。Qwenとは「通義千問」という意味で、自然言語理解や生成、対話などの様々なタスクに対応できることを目指しています。Qwenシリーズは、以下のような時系列で公開されています。
Qwen1.5(第2世代)
・Qwen-7B
2023年8月に発表された70億パラメータを有する大規模言語モデルです。同等サイズのモデルと比較すると、圧倒的なパフォーマンスを出しています。
その理由としては2つあり、一つは学習データが2.2兆トークンで学習していることです。もう一つの理由はトークナイザのボキャブラリ量にあり、15万以上を扱えます。
ボキャブラリーが多いことは、表現力・対応力に影響しますのでその分が優秀となっていると言えます。これらの相乗効果により特に、自然言語の理解や数学、コーディングのタスクでは優秀な実力を発揮しています。
・Qwen-14B
2023年10月3日にQwen-14Bが発表されました。Qwen-7Bの発展モデルでこれは140億パラメータ、3兆トークンを有するLLMで、チャットモデルとしても利用することができる対話型の生成AIとなっています。中国語・英語で学習されたモデルで多言語に対応したモデルになっています。
大量の高品質データを学習したことにより、このモデルは高度な推論、認知、および問題解決能力を持っています。
・Qwen-72B
2023年11月30日、中国の中国の大手IT企業アリババが、72Bパラメータを持つ大規模言語モデル「Qwen-72B」を公開しました。
Qwen-72Bは一般分野から専門分野までを含む 3兆トークンという巨大なデータセットでトレーニングされています。データセットには、中国語、英語、多言語テキスト、コード、数学などが含まれています。
2023年12月現在公開されているオープンソースのLLMの中でも最高クラスの性能を持っています。
大きなサイズと複雑さにも関わらず、Qwen-72Bは低コストで運用できるモデルになっています。最小限のメモリ使用(3GB未満)で運用できるため、様々なアプリケーションで利用可能となっています。
・Qwen-1.8B
2023年11月30日に公開されたこのモデルは18億パラメータを持つLLMです。他のシリーズと比べてパラメータは小さいものとなっていますが「特定のタスクに特化させる」というスタンスのモデルです。
BBHやAGIEvalなどのベンチマークでは強力なパフォーマンスを示しているモデルとなっています。
Qwen2.0(第3世代)
Qwen2は、上記で解説したQwen1.5の後継として2024年6月にリリースされたモデルです。
Qwen1.5と比較して、数学とコーディングの精度が大幅に向上しました。広範で高品質なデータセットを活用し、トレーニング経験とCodeQwenのデータを統合することでこれを実現しています。また、日本語を含む29言語をサポートし、グローバルな用途への適応性が高まりました。
0.5Bから72Bまでのモデルが公開されており、様々なハードウェア環境やタスク要件に合わせて選択できます。
【最新モデル】Qwen3.0(第4世代)
Qwenシリーズの最新世代であり、2025年5月に発表されました。推論能力、エージェント能力、多言語サポートにおいて画期的な進歩を遂げています。
Qwen3.0は、密モデルとMoE(Mixture-of-Experts)モデルの両方を組み合わせ、パフォーマンスと効率性の両立を実現。複雑な論理推論や数学、コードタスクには「思考モード」を、効率的な汎用対話には「非思考モード」をシームレスに切り替える機能が搭載され、あらゆるシナリオで最適なパフォーマンスを発揮します。
また、100以上の言語と方言をサポートし、多言語での指示追従と翻訳能力が大幅に向上しました。
さらに、2025年9月にはパラメータ数が1兆を超える最新モデル「Qwen3-Max-Preview(Instruct)」がリリースされました。主要なベンチマークで世界トップクラスの性能を発揮し、アリババクラウドのBailianプラットフォームでAPIとして利用可能です。
Qwen-VL(Vision-Language)シリーズ
Qwen-VLは、画像や動画を理解できるマルチモーダルモデルです。以下の2つのモデルがあります。
- Qwen2-VL
2024年8月に発表された最新版で、20分以上の動画を分析できる機能を持っています。高解像度画像(100万ピクセル以上)や様々なアスペクト比の画像にも対応し、GPT-4VやGeminiと同等以上の性能を一部のタスクで発揮します。 - Qwen-VL-Plus
2025年8月に最新スナップショットモデル「Qwen-VL-Plus-2025-08-15」がリリースされました。コンテキストウィンドウが128,000トークンに拡張されています。
Qwen-audio
Qwen-Audioは、11月30日に発表された大規模音声言語モデルで、Qwenという大規模モデルシリーズの多モーダルバージョンです。Qwen-7BとOpenAIの音声エンコーダーであるWhisper-large-v2を組み合わせたもので、マルチタスク音声言語モデルとなります。
複数のオーディオ分析、音声理解と推論 を行うことが可能で、音声に特化した生成AIとなっています。中国語、英語を中心に、日本語、韓国語、ドイツ語、スペイン語、イタリア語での音声理解をサポートしています。
通義万相
通義万相は、2023年7月にアリババグループ(アリババクラウド)から発表された画像生成AIです。
中国語や英語のテキストプロンプトに応答し、水彩画、油彩画、中国画、アニメーション、スケッチ、フラットイラスト、3D漫画など、多様なスタイルのディテールに富んだ画像を生成します。
独自の大型モデルであるComposerを使用して開発され、画像合成の品質と創造性を維持しながら、空間レイアウトやパレットなどの最終的な画像出力をより細かく制御しています。
2025年7月に最新版「通義万相2.2」として全面的なアップグレードが行われました。最新アップデートでは、特に画像生成機能と動画生成機能が大幅に強化されており、高解像度画像生成や複雑な動画生成能力、そしてプロンプトへの追従性などが向上しています。
また、アリババクラウドは2025年3月に日本市場における事業戦略を発表し、日本語性能の高い大規模言語モデル「Qwen2.5」とともに、動画生成モデルの最新版「Wan2.1」を日本市場に投入することを表明しました。通義万相シリーズが日本国内のユーザーや企業にも本格的に提供されるようになり、今後中国産LLMがより身近な存在になりそうです。
零一万物(Yi)シリーズ
Yi-6b(同シリーズにYi-6b-200k)
Yi-6bは2023年11月2日に公開された大規模言語モデルで、60億のパラメータを持っているモデルです。
主に中国語と英語で一般分野から専門分野までを含む大規模なデータセットでトレーニングされています。日本語でも問題なく出力されるみたいです。
パフォーマンスは一連のベンチマークで、同サイズのモデルであるLLaMA2-70bを上回る性能を示しており、現在公開されているLLMの中でも高い性能を有しています。
Yi-6kは4Kのシーケンス長でトレーニングされています。同シリーズのYi-6b-200kは200kの非常に長い文章をサポートしています。
Yi-34b(同シリーズにYi-34b-200k)
Yi34bは2023年11月2日にYi6bと同時に公開された大規模言語モデルで、340億のパラメータを持っているモデルです。パラメータ量の増大により、Yi-6bよりパフォーマンスが上昇しています。
Yiシリーズは、自然言語理解や生成、コーディング、数学などのタスクに対応できるとされ、さまざまなベンチマークで高い性能を示しました。
同シリーズであるYi-34b-200kは20万トークンに対応し、漢字約40万字の入力が可能となっています。
Yi-Large
Yi-Largeは、Yiシリーズの中で最も強力な閉鎖系(クローズドソース)モデルです。1000億パラメータ規模でありながら、GPT-4やGemini 1.5 Proといった数兆パラメータのモデルと肩を並べる性能を発揮している点が注目されています。
2025年5月に更新されたLMSYS Chatbot Arenaの盲目テストで、Yi-Largeは世界のトップクラスに位置づけられ、中国国内のAIモデルの中で首位を獲得しました。Llama-3-70BやClaude 3 Sonnetを上回る評価を得ています。特に中国語のベンチマークでは、GPT-4oと並んで1位になるなど、高いパフォーマンスを示しました。
Yi-VLシリーズ(Vision-Language)
Yi-VLは、画像とテキストの両方を理解するマルチモーダルAIモデルです。
Yi-VL-6BおよびYi-VL-34Bは、画像を認識し、それについて複数回にわたる会話をすることができるオープンソースモデルです。画像から情報を抽出したり、要約したりするタスクに優れています。 既存のオープンソースのビジョン・ランゲージモデルの中で、複数のベンチマークでトップにランクインするほどの高い性能を持っています。
Hunyuan(混元)
Hunyuanは、中国の大手IT企業テンセントが開発した大規模言語モデルで、1000億以上のパラメータを持っています。Hunyuanは、2兆以上のトークンを含む大規模なデータセットでトレーニングされています。
Hunyuanは、数千語の長文生成や複雑な数学問題の解決など、OpenAIのChatGPTをいくつかの面で上回る性能を示しているようです。
というのも、中国の企業がテンセントクラウド上のAPIを使用してテストおよびアプリの構築が可能となるモデルであり、実際に確認することはできません。
Hunyuanの最新の大きなアップデート(2025年7月)は、没入型でインタラクティブな3D世界の生成に特化した「HunyuanWorld-1.0」のリリースです。このモデルは、テキストや画像からパノラマ画像、シーン、空などを生成する能力を持っています。単に静止画を生成するだけでなく、探検可能で没入感のある3D世界を生成することが可能です。
また、動画生成AIや3Dモデル生成分野でも継続的にアップデートを行っています。
Skywork-13B
Skyworkは、「昆仑万维集团・天工团队」によって開発されたLLMのシリーズです。およそ130億ものパラメータを持っており、中国語と英語のデータセットで学習されています。学習トークンは3.2兆を超えており、高性能なモデルとして知られています。
AIアシスタントの総合評価を目的としたGAIAベンチマークでは、SkyworkのDeep Researchが次の通り業界トップクラスのスコアを出しています。※1
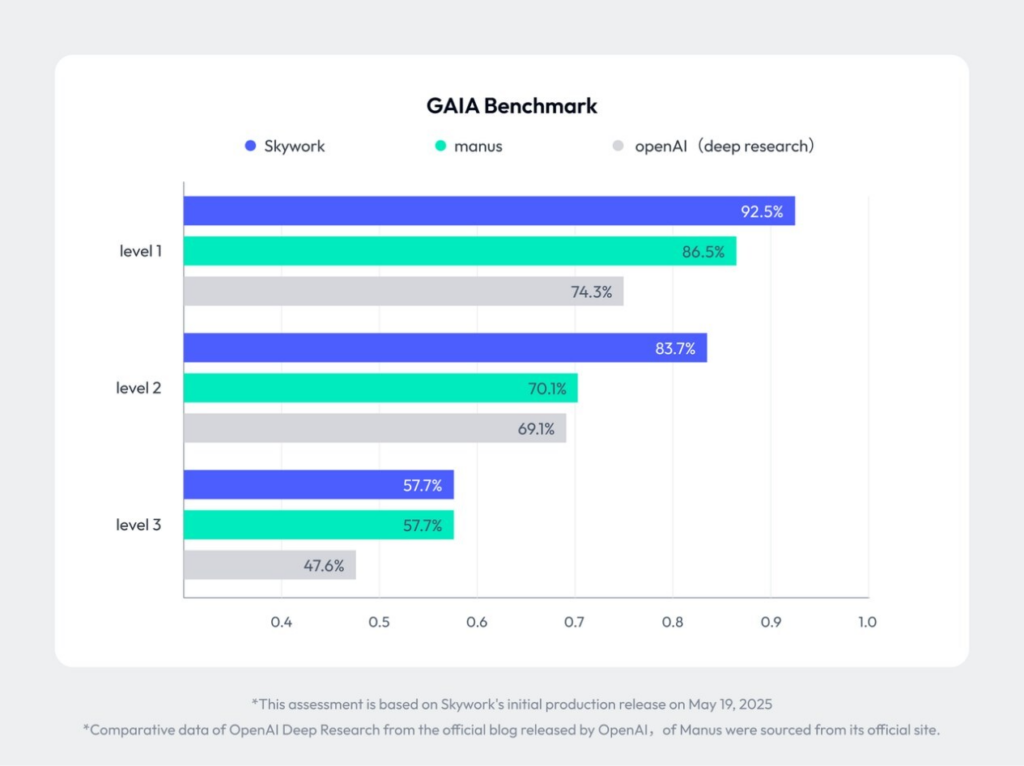
以下の4つの主要なLLMが存在し、今後も様々なモデルを公開していく予定とのことです。
- Skywork-13B-Base:基本的なモデルで、様々なベンチマークテストで優れた性能を発揮
- Skywork-13B-Chat:会話能力に特化しており、特に創造的な文章を書くのが得意
- Skywork-13B-Math:数学的な能力に特化したモデル
- Skywork-13B-MM:マルチモーダルモデルで、画像情報を利用してQ&Aや対話などのタスクをこなせる
Skywork-13Bは、2025年9月現在最新モデルの「Skywork-13B-V2」としてリリースされています。V2では、ユーザーの多様な好みや意図をより深く理解する能力が強化されており、モデルがより自然で文脈に合った役立つ応答を生成できるようになりました。
Skywork AIは、AIエージェントやRPAツールなどより広範なソリューションの開発にも注力しており、2025年5月には「Skywork Super Agents」もリリースされています。
DeepSeekシリーズ
各種DeepSeekLLMシリーズは、2023年11月29日にDeepSeek AI社より発表された大規模言語モデルで70億(670億)パラメータを持っているモデルです。英語と中国語で一般分野から専門分野までを含む大規模なデータセットでトレーニングされています。
DeepSeek-LLM-67B-Baseは推論、コーディング、数学、中国語理解などの分野で、同サイズのモデルであるLlama2 70B Baseを上回る性能を示しています。
また、DeepSeek LLM-67B-Chatは、コーディングと数学で優れたパフォーマンスを発揮しています。BaseとChatの違いは以下のようになります。
現在DeepSeekは、上記のモデルを基盤とした最新の汎用モデルである「DeepSeek V3.1」を2025年8月にリリースしました。これは、既存の「DeepSeek-V2」をさらに強化したものです。DeepSeek V3.1は、従来のMoE(Mixture-of-Experts)アーキテクチャをさらに進化させることで推論性能を43%向上させ、同時にハルシネーション(AIがもっともらしい嘘をつく現象)を38%削減したとされています。
他にも、OpenAIの最上位モデルと同等の性能を低コストで実現し大きな注目を集めた「DeepSeek-R1」や特定タスク特化モデルを多数リリースしており、飛ぶ鳥を落とす勢いで成長し続けています。
Xwin-LMシリーズ(7B, 13B, 70B)
Xwin-LMは、大規模言語モデル(LLM)のためのアライメント技術を開発し、オープンソース化することを目的としたプロジェクトです。
2023年9月、Xwin-LM-70B-V0.1、Xwin-LM-13B-V0.1、Xwin-LM-7B-V0.1という異なるサイズのモデルを開発、公開しました。これにより、ユーザーは異なるニーズやリソースに合わせて最適なモデルを選択できます。
以下の表のとおりAlpacaEvalのベンチマークで高いパフォーマンスを発揮しています。
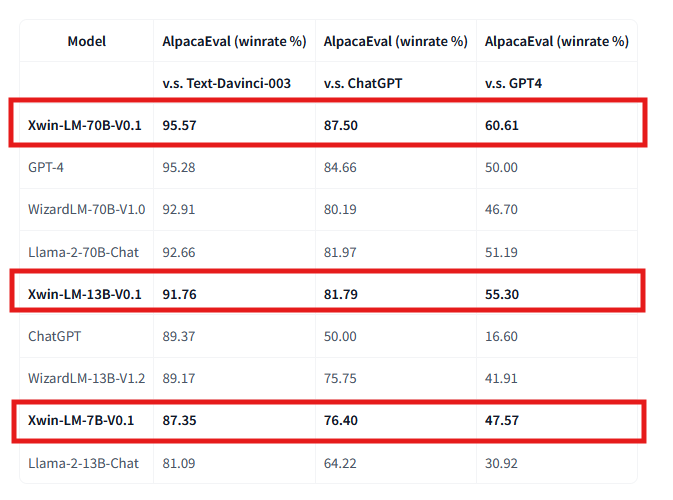
2023年10月12日にXwin-LM-13BとXwin-LM-7BはV0.2の改良版が公開され、さらに2024年1月のアップデートで両モデルの「V0.3」がリリースされました。V0.3はオープンソースモデルの中で、AlpacaEvalでトップにランクされています。
Xwin-LMシリーズの中でも数学能力に特化したモデルとしてリリースされている「Xwin-Math-7B/13B/70B」の最新版「Xwin-Math-7B/70B-V1.1」が2024年5月に発表され、MATHおよびGSM8Kベンチマークで優れた性能を示しています。
また、コード生成に特化したモデルとして「Xwin-Coder-7B/13B/34B」もリリースされています。
ChatGLMシリーズ(智谱AI )

ChatGLMは、2023年に清華大学発のスタートアップ「智谱AI(Zhipu)」が公開した対話特化型大規模言語モデル(LLM)です。初代ChatGLM-6Bは60億パラメータ規模で、中国語と英語のバイリンガルに対応し、公開直後から研究・商用の両面で高い人気を集めました。
ChatGLM2-6Bでは学習データを拡充し、強化学習(RLHF)を導入することで対話性能を大幅に改善。さらに2023年末には「ChatGLM3」が登場し、自然言語理解、推論、コーディングといった幅広いタスクで強力な性能を発揮しました。シリーズはオープンソースとして公開され、Apache 2.0ライセンスにより商用利用も可能です。
中国国内では教育、金融、ビジネス向けチャットボットなど幅広い領域で導入が進んでいます。
Baichuanシリーズ(百川智能)

Baichuan(百川)は、2023年に創業したAI企業「百川智能」が開発するオープンソースLLMシリーズです。代表的な「Baichuan-7B(70億パラメータ)」と「Baichuan-13B(130億パラメータ)」は、公開当初から商用利用可能なApacheライセンスで提供されました。
ベンチマークでは、同規模のLLaMAやFalconを上回る性能を記録。特にBaichuan-13Bは中国語・英語の双方向理解に強く、自然言語処理や数学タスクでも高い精度を発揮しました。2024年には改良版の「Baichuan2シリーズ」がリリースされ、パラメータ数の拡大と効率化が進み、実運用しやすいモデルとして注目されています。
WuDao(悟道)シリーズ

WuDao(悟道)は、北京智源人工知能研究院(BAAI)が2021年に発表した超大規模LLMシリーズです。特に「WuDao 2.0」は1.75兆パラメータという世界最大規模を誇り、自然言語処理、画像生成、音声認識などマルチモーダルAIとしても機能しました。
学術研究色が強く、主に基礎研究や技術実証のために利用されていますが、当時は「世界最大規模のAIモデル」として国際的に大きな注目を浴びました。現在は規模拡大よりも効率化・応用に重点を移し、教育・科学計算など特定分野での活用が進められています。
Pangu-Σ(盤古α)

Pangu(盤古)シリーズは、Huaweiが2021年から開発を進める大規模AIモデル群です。特に「Pangu-Σ」は産業特化型LLMとして、金融・気象・医療など専門領域での応用に強みを持っています。
Huaweiクラウド(昇騰AIインフラ)と連動し、商用利用に最適化されている点が特徴です。自然言語処理に加え、科学計算や産業シミュレーションに応用されており、政府や大企業向けプロジェクトでも積極的に採用が進んでいます。
MagicAnimate
2023年10月27日にバイトダンスが、人物やキャラクターの静止画や動画と、モーションシーケンスデータを組み合わせて、動画を生成できる動画生成モデル「MagicAnimate」を発表しました。
MagicAnimateは、時間情報を符号化するためのビデオ拡散モデルと、フレーム間の外観の一貫性を維持するための新しい外観エンコーダを導入しています。
これにより時間的一貫性の向上、参照画像の忠実な保存、アニメーションの忠実度の向上を実現しました。
AnimateAnyone
Animate Anyoneは、2023年11月にアリババグループの研究チームが発表した、画像1枚から高品質なアニメーションを作成できる技術です。
一貫性と制御可能な動きを持つ高品質なキャラクターアニメーションビデオを生成することを目指しており、時間情報をエンコードするためのビデオ拡散モデルを開発しています。
また画像の詳細な特徴を抽出する「ReferenceNet」と、動きを指定する「MotionNet」という2つのネットワークが導入されています。
2025年2月には「AnimateAnyone 2」がリリースされました。
AnimateAnyone 2では、キャラクターの静止画像と動画から高品質なアニメーションを生成し、キャラクターと環境の相互作用をリアルに再現する技術を採用。さらに、人間の主要な骨格点を正確に追跡し、肢体の動きや顔の微表情を捉えることが可能なダイナミックボーンバインディング技術を導入し、より自然でダイナミックなアニメーションが作成できます。
なお、Animate Anyoneについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

中国AI企業のオープンソース化戦略
中国のAI企業は、大規模言語モデル(LLM)のオープンソース化を積極的に進めており、米国のクローズドモデルとは対照的な路線を展開しています。以下では、その代表的なモデルや背景、戦略的な効果について解説します。
代表的なオープンソースLLMの特徴と成果
代表的な事例として、DeepSeek、AlibabaのQwen、智谱AIのChatGLM、百川のBaichuanが挙げられます。
DeepSeek-R1はMITライセンスの下でモデル重みを公開し、GPT並みの性能を低コストで提供することに成功しました。Qwenは長大な文脈処理に対応し、商用利用も可能なライセンスで普及を広げています。さらにChatGLMやBaichuanは中英語ベンチマークで高い評価を得ており、性能・効率・価格のバランスで米国の有力モデルに迫る水準に達している点が大きな特徴です。
オープン化に踏み切る背景と狙い
中国のAI企業が自社モデルをオープンソース化するのには、いくつもの理由があります。
まず、研究者や開発者にモデルを公開することで、多くの人が改良や検証に参加でき、技術の進歩が早まります。また、「技術を独り占めせず共有する姿勢」を見せることで、企業の評判や信頼性を高める効果もあります。
さらに、モデルそのものは無料で公開しても、API提供やクラウドサービスを通じて収益を得る仕組みをつくることができます。これは多くの開発者に利用してもらうことで市場シェアを広げる狙いにもつながっており、加えてアメリカのAI企業が「閉じたモデル(クローズドモデル)」で差別化しているのに対し、中国企業は「開放性」を強みにして対抗しています。
もう一つの重要な背景は、GPU不足という制約です。中国は米国の半導体規制により十分な計算資源を確保しにくいため、効率的な仕組みや新しい工夫を取り入れる必要がありました。オープンソース化によって世界中の知見を取り入れれば、限られたリソースでも大きな成果を生み出すことができます。
このように、オープン化は「善意の公開」ではなく、技術革新と市場拡大を同時に実現する戦略であり、国際競争を意識した長期的な取り組みでもあるのです。
オープン戦略の効果
オープンソース化の効果は主に以下の3つの側面に表れています。
- ビジネス
- 国家政策
- 国際競争
ビジネス面では、開発者コミュニティの形成による品質向上や人材獲得が進み、低価格APIやクラウド提供を通じて収益拡大につながっています。国家政策面では、中国政府の技術主権確立や効率化推進と合致し、官民一体の開発体制の強化が実現。国際競争面では、米国のクローズドモデルに対抗する差別化戦略として、低コストかつ高速改良を武器に市場を拡大し、制裁リスクを回避しています。
中国が進めるオープン戦略により、AI覇権争いの構図そのものを揺るがす可能性が高まっていると言えるでしょう。
なお、アリババの最強生成AIツールについて詳しく知りたい方は、下記の記事を併せてご確認ください。

中国LLMは今後進化していく
中国のLLMについてまとめました。LLM発表当初こそアメリカに出遅れているという感はありましたが、国家レベルでの研究開発やオープンソース化戦略も相まって、今では他のLLMとは一線を画す存在となってきています。
生成AIは、今後もアメリカと中国が競い合いながら進化をしていくことでしょう。
まだ日本語に対応しているものは多くありませんが、今回ご紹介したLLMの多くはChatGPTに勝るとも劣らない実力を備えています。ぜひその性能を試してみてくださいね。

最後に
いかがだったでしょうか?
中国発の最新LLMやオープンソース戦略を自社のAI活用にどう結びつけられるか、実務視点で具体的なヒントをご紹介します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

