
マルチモーダルAIとは?意味・仕組み・代表モデル・活用事例をわかりやすく解説

- テキスト・画像・音声・動画を横断的に理解できるAIとして、対話や解析の高度化が進行
- GPT-4oやGemini 3 Proなどの登場で、リアルタイム支援や業務活用が急速に拡大
- 高い将来性がある一方、計算コストや説明責任・プライバシー対応が課題
近年は、ChatGPTやGeminiなどの登場により、「画像を見せながら相談する」「会話しながら画面や資料を一緒に読んでもらう」といった使い方が一気に広がりました。こうした体験を支えているのが、テキストだけでなく画像・音声・動画など複数の情報をまとめて処理できるマルチモーダルAIです。
2024年以降、OpenAIのGPT-4oやGoogleのGemini 3 Proなど、テキスト・画像・音声・動画を一体的に扱える高性能なマルチモーダルモデルが次々と登場し、リアルタイムの音声対話や動画解析、画面共有を通じた支援など、ビジネス現場での活用も加速しています。
この記事では、マルチモーダルAIの概要やできること、活用事例などを紹介いたします。最後まで読めば、マルチモーダルAIの特徴を理解できるので、マルチモーダルAIを活用したサービスの導入をいち早く検討できるようになるでしょう。ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
マルチモーダルAIとは
マルチモーダルAIとは、テキスト・画像・音声・映像など、異なる種類の情報を複数同時に処理できるAIのことです。単一の情報だけを処理するシングルモーダルAIよりも、より複雑な情報を理解できるほか、異なる情報同士の関係を把握することもできます。
マルチモーダルAIの根底には、ディープラーニングという機械学習技術があり、この技術が画像、音声、自然言語といった複雑なデータパターンの認識や生成を可能にしているのです。近年は、テキストだけでなく画像・音声・動画まで一度に扱える大規模マルチモーダルモデル(MLLM: Multimodal Large Language Model)という概念もよく使われるようになりました。
GPT-4oやGPT-5、Gemini 3 Pro、Claude 4.5 Sonnetなどが代表的な例で、チャットボットとしての対話だけでなく、カメラ映像や画面共有、音声通話を組み合わせた高度なサポートを提供できるようになっています。
マルチモーダルの意味
「モーダル」とは入力情報という意味を示しており、2種類以上の情報を入力できるAIを「マルチモーダルAI」と呼んでいます。
LLMへの応用
マルチモーダルAIをLarge Language Models (LLM)に応用することで、AIはテキストだけでなく、画像や音声などの多様な情報を理解し処理できるようになります。
わかりやすくいうと、スマートフォンのアシスタント機能が単に音声での質問に答えるだけでなく、ユーザーが送った写真を理解して、その内容について話してくれるようなものです。この技術は、医療、教育、エンターテイメントなど、多岐にわたる分野での応用が期待されています。※1
実際に、ChatGPTでは、音声と画像、テキストを組み合わせてリアルタイムに会話できるインターフェースが提供されており、会議の議事録作成やプレゼン資料のレビューなどに活用され始めています。
なお、LLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
とは?仕組みや代表例、サービス、できることを徹底解説-300x169.jpg)
マルチモーダルAIとシングルモーダルAIの違いと仕組み
マルチモーダルAIと対照的なのが、シングルモーダルAIです。マルチモーダルAIは複数の入力モード(例えば、テキスト、画像、音声など)を扱うことができるのに対し、シングルモーダルAIは一つのモードのみを扱います。
両者を比較すると、以下のようになります。
| AIの種類 | マルチモーダルAI | シングルモーダルAI |
|---|---|---|
| データの種類 | 複数のモードを組み合わせて処理できる(テキスト、画像、音声など) | 単一のモードのみを処理できる(テキストまたは画像など) |
| 処理能力 | 異なるモード間の関係を理解できる | 各モードを個別に処理する |
| 実用例 | 画像とテキストの関連性分析、動画解析など | テキスト分析、画像認識など |
マルチモーダルAIは複数の情報(モード)を組み合わせることで、より高精度な情報を出力して複雑な問題に向き合うことが可能です。
これは人間が視覚と聴覚を使って情報を得ている状態に該当します。一方、シングルモーダルAIは、テキスト分析や画像認識などを個別に処理することしかできません。
人間でいうと、視覚のみで状況を分析しようとしているのと同じですね。よって、比較的単純な業務にはシングルモーダルAI、高度で複雑な業務にはマルチモーダルAIが適しています。


マルチモーダルAIの歴史
マルチモーダルAIの研究は、1980年代半ばから始まりました。
当初の研究は、比較的単純なタスクに焦点を当てていましたが、2011年頃からディープラーニングの導入により、研究は大きく進展。2013年にはテキストと人間の表情(画像)をもとにした「Expressive Visual Text-to-Speech」という研究が行われました。
この研究ではテキストの入力情報に対して内容を理解し、アバターの表情と音声で感情を表現することに成功したことが報告されています。※2
その後、画像に関連する質問に対して回答するAIや、画像情報から音声を生成するAIが登場し、マルチモーダルAIの研究が加速していきました。
こうした技術の進化により、2025年現在では、製造・医療・自動運転だけでなく、動画生成やリアルタイム翻訳、コールセンターの自動応答など、より日常的な業務にもマルチモーダルAIが組み込まれ始めています。
マルチモーダルAIにできること
マルチモーダルAIは、テキスト・画像・音声・動画といった、異なる種類の情報を組み合わせることで、さまざまな業務を可能にします。情報の組み合わせごとにできることを紹介いたします。
テキスト⇄画像or音声or動画
テキストから画像への変換、画像からテキストへの分析、テキストと画像の同時入力からの分析指示など、幅広い処理が可能です。まさかと思うかもしれませんが、マルチモーダルAIの代表格ともいえる「GPT-4」は、問題文と図を参照する物理の問題を解けるようになっています。※3
さらに、音声とテキスト間では音声をテキストに、テキストを音声に変換することができ、特に言語間の翻訳においてその能力が注目されています。
日本語の音声を英語のテキストに変換したり、逆に日本語のテキストを中国語の音声に変換できるので、海外の方との円滑なコミュニケーションが期待できます。
また、テキストと動画間では、テキストから動画を生成したり、動画内容をテキストで解析したりすることが可能です。これは、防犯対策や危険察知などに役立つ技術として注目されています。
画像⇄音声or動画
画像と音声間では、テキストとサンプル音声を組み合わせて、特定の人物が話しているかのような音声出力を生成することが可能です。この機能は、すでにChatGPTに実装されており、コンテンツ作成の完成度や効率の大幅な向上が期待されています。※4
一方、画像・動画間においては、静止画から短時間の動画を生成することが可能です。外観の一貫性を保ちながら、滑らかな動きを表現できるので、広告やLPなどで活用されていくでしょう。※5
2024年以降は、RunwayのGen-3 Alphaのように、テキストや画像から高品質な動画を生成できる商用サービスも広がっています。これによって、広告動画や SNS 用クリエイティブなどを少ない工数で量産しやすくなってきました。
音声⇄動画
音声・動画間では、音声と動画を統合して解析できるため、より複雑な状況や行動を認識できます。
たとえば、監視カメラにマルチモーダルAIを搭載すれば、音声と動画の両方の情報を読み取ることができます。※6
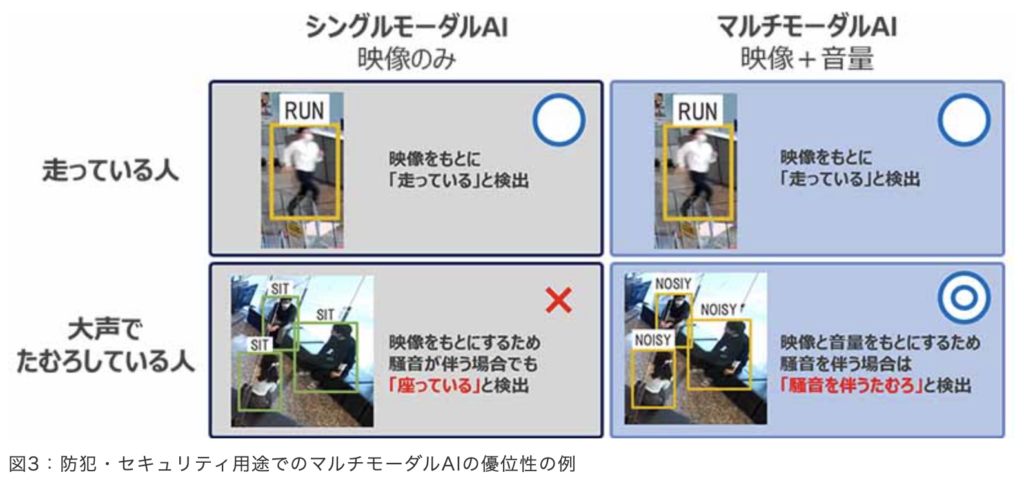
従来のカメラでは、複数人が建物内でたむろしていても特に問題は検出されませんでした。しかし、動画と音声情報を認識できるマルチモーダルAIなら、音声から「大声で会話している」という状況を認識して、トラブルの防止策を実行できるようになります。
なお、画像・音声入力に対応したGPTについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Pythonでの実践学習
マルチモーダルAIのPythonによる実践学習も可能です。その一例として、TorchMultimodalライブラリをご紹介します。
TorchMultimodalは、テキスト、画像、ビデオ、オーディオなど複数の入力タイプを理解し、それらを基に異なる形式の出力を生成するマルチタスクマルチモーダルモデルの訓練を加速するPyTorchドメインライブラリです。
このライブラリを利用することで、Pythonでの実践学習を以下のように進めることができます。
- ビルディングブロックの利用
- 最新研究のモデルの訓練と評価
- 実践的なプロジェクトへの適用
- チュートリアルとコミュニティリソースの活用
詳しくは以下の記事で解説されていますので、興味のある方はぜひご覧ください。
また、最近では、TorchMultimodalのような研究寄りのライブラリだけでなく、GPT-5や Gemini 3 Pro、Claude 4.5 Sonnet などのマルチモーダルAPIをPythonから直接呼び出し、画像・音声・テキストをまとめて処理するケースも増えています。
こうしたSaaS型のAPIを活用すれば、大規模なGPU環境を自前で用意しなくても、比較的少ないコード量でマルチモーダルAIのPoCを進められる点が実務では大きなメリットです。
代表的なマルチモーダルAI
世の中には、すでにマルチモーダルAIを活用したサービスが多数登場しています。ここでは、代表的なマルチモーダルAIをご紹介するので、導入を検討してみてください。
GPT-4【ChatGPT言語モデル】
GPT-4はOpenAIによって開発された最先端の自然言語処理モデルで、テキストと画像の両方を受け入れるマルチモーダルAIです。
このバージョンは、従来のモデル(GPT-3やGPT-3.5)に比べて安全性と有用性が大幅に向上しており、創造的なタスクや問題解決においてより高い精度を実現しています。※7

GPT-4の主な特徴
- マルチモーダル入力:テキストと画像の入力に基づいて、関連するテキスト出力を生成。
- DALL-E 3統合:テキストから具体的な画像を生成する能力。
- 安全性の向上:不適切なコンテンツに対する応答の可能性を低減し、事実に基づいた応答の精度を向上。
これらの特徴により、GPT-4は教育、ビジネス、クリエイティブな分野での応用が特に期待されています。
Google Gemini
Googleが提供する対話型AIサービス「Bard」は、2024年2月8日に「Gemini」という新しい名前で生まれ変わりました。
ChatGPTに対抗する製品として開発されたGeminiは、テキストベースのやり取りだけでなく、画像、音声、動画といった複数の情報を処理するマルチモーダルAIとして注目を集めています。※8

Geminiは、単にテキスト情報を理解して応答するだけではなく、画像の内容を分析したり、音声データの処理もできます。
例えば、写真の内容について質問したり、音声入力で情報を得たりするなんてことも可能です。
なお、Geminiの使い方について詳しく知りたい方は、下記の記事を合わせてご確認ください。

NExT-GPT
NExT-GPTは、テキスト・画像・動画・音声など、さまざまなモダリティの入力に対応しているマルチモーダルAIです。入力した複数の情報を組み合わせ、新しいコンテンツを作成することができます。
たとえば、テキストや画像入力から動画作成、音声や動画入力からテキスト作成といった業務が可能に。まだまだ精度が低いものの、今後は文字起こしや簡単な動画製作など、ほとんどの単純作業を幅広く効率化してくれることでしょう。
なお、NExT-GPTについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Gen-2 by Runway
Gen-2 by Runwayは、テキスト・画像・動画などのデータから新しい動画を生成できるマルチモーダルAIです。入力情報としてテキストや画像を入力するだけで、簡単操作で動画を生成できます。
また、Gen-2 by Runwayは、ブラウザ上で動画を生成できるのも嬉しいポイント。専用ツールやソースコードなどをPCにインストールしなくてよいので、ハイスペックなPCを用意する必要がありません。無料かつ、手軽に動画生成を楽しみたい方におすすめです。
Copilot(旧BingAI)
Copilot(旧BingAI)は大規模言語モデル(LLM)の「GPT-4」が使われており、対話形式でユーザーの疑問や要望を解決します。テキスト生成だけでなく、イラスト生成機能なども備えているため、創作物の制作や、コーディングのツールとしても活用できるのが特徴です。また、マルチモーダルに対応し画像の解析ができるようになりました。※9
すべての機能を無料で誰でも利用できるため、導入しやすいツールといえるでしょう。
なお、Copilot(旧BingAI)について詳しく知りたい方は、下記の記事を合わせてご確認ください。

マルチモーダルAIの活用事例
マルチモーダルAIが実際に活用されている事例を5つ紹介いたします。
マルチモーダルAIと医療ビッグデータの活用
日本電気株式会社(NEC)と理化学研究所、日本医科大学は、医療分野での電子カルテとAIの融合の研究を進めていて、さまざまな医療ビッグデータを統合的に解析するマルチモーダルAIを構築しました。
前立腺がんを対象としたもので、病気の早期発見や治療計画の最適化を可能としました。また、医療費の削減や医療従事者の負荷の軽減が期待されています。
このAIシステムでは、複数種類の検査データから病気の状態や経過を多角的に判断・予測が可能です。
電子カルテのデータや、がんの組織画像などを用いてマルチモーダルAIが解析したところ、手術後から再発までの年数によりAIが捉えた予測因子のパターンに違いが見られており、さらなる研究が進められています。※10
材料データからさまざまな機能を予測
産業技術総合研究所(産総研)、日本ゼオン株式会社などが共同で、AIを用いて複雑な構造を持つ材料データより、高精度で複合材料の機能を予測できる技術を開発しました。このマルチモーダルAI技術は、様々な配合を持つ複雑材料系でのマテリアルズ・インフォマティクスに対して非常に有効なツールとなります。
画像データや分光スペクトルなどの異なる複数のデータを計測し統合することにより、複雑な材料系でも異なる特性を高精度で予測することが可能となりました。膨大な条件から選定・成形加工・評価といった材料開発プロセスの大幅な高度化・効率化が可能となりました。※11
自動車の自動運転
自動車の自動運転技術は、複数の情報を処理する「マルチモーダルAI」の特徴的な事例です。中央線をはみ出したら、自動的に戻す技術などは、この技術の最たるものだと言えます。
複数のカメラの他、車両や人物などの速度を検知するミリ波センサー、加速度センサー、GPS、踏切などの音を聞き取るマイクなどが搭載されていて、状況を判断して処理を行っています。
Turing株式会社は、『We Overtake Tesla』をミッションとして、2030年までに完全自動運転EVを10,000台量産することを目指しているようです。
産業用ロボットへの活用
マルチモーダルAIの産業用ロボットへの応用は、画像・角度・速度・力覚などの複数の情報を組み合わせて判断することで、ロボットアームによる繊細な作業ができます。
デンソーウェーブによって開発されたマルチモーダルAIロボットは、多指ハンドを装着した双腕型ロボットアームをディープラーニングでリアルタイム制御し、不定形物を扱う作業が可能です。
さらに、デンソーウェーブが開発した「AI模倣学習」システムは、人の動作を模倣して学習する技術で、産業用ロボットがサラダの盛り付けやタオルをたたむなどの動作を可能にしています。※12

マルチモーダルAIを活用した産業用ロボットは、工場内の作業だけでなく、医薬・医療、農業や物流など様々な分野での活躍が期待されています。
ホームロボットへの活用
介護支援ロボット「RoBoHoN」は、従来の対話型AIに加え、マルチモーダルAIシステム「MICSUS」を搭載しています。このシステムは、言語だけでなく、非言語コミュニケーション(例えば、身振り手振り)も理解し、組み合わせることができる高度なマルチモーダル対話処理技術を用いています。※13

実証実験では、「RoBoHoN」を使って高齢者の健康状態や生活状況の変化に関する情報を収集し、ケアマネジャーや家族とのコミュニケーションを支援しました。
また、高齢者がロボットに話しかけることでいつでも雑談が可能となっており、高齢者の関心事などの情報もケアマネジャーと家族へ共有されるようになっています。
防犯カメラへの活用
防犯カメラの映像解析AIは、映像のみで解析されていることが一般的です。これは人間に例えると視覚情報のみで迷惑行為などを検出しているといえます。ここにマルチモーダルを導入することで、映像に加えて音の情報を分析が可能です。※6
映像だけでは曖昧な状況が、音声データが加わることで危険性が高い状況なのか判断できるようになるでしょう
スポーツへの活用
愛知県立大学の情報科学部によると、ロボカップサッカーの標準プラットフォームリーグにおいて、MLLMを用いて自動で試合の実況・解説をするシステムの実験が行われました。生成された実況・解説文章に対して、面白さ・明瞭さ・適切さの観点からアンケートを行ったところ、どの項目においても肯定的な結果が半数以上得られたそうです。※14
将来的に実況がAIによって行われるようになる可能性があるといえるでしょう。
教育現場での活用
マルチモーダルを活用することで、学生一人一人の理解度に合わせて教育を提供ができるようになります。テキスト・画像・動画など異なる形式の教材を活用して、学生に最も効果的な学習方法の提供が可能です。
また、試験や課題の自動評価が可能になります。画像認識や音声認識で多方面から学習の進捗の評価をしたり、リアルタイムでフィードバックも可能です。これにより学生が学びやすくなるだけでなく、教師にかかる負担の軽減が期待できます。※15
マルチモーダルAIの課題
マルチモーダルAIがさまざまな業界で利用できることをご紹介しましたが、まだまだ課題はあります。
異なるデータの統合が難しい
テキストは言葉や文法のルールに基づくデータ、画像はピクセル(色と明るさの情報)、音声は時間の経過とともに変化する波形データ、というようにデータごとに性質が異なります。性質が異なることで、それぞれのデータを同じ基準で理解させたり関連付けたりする事が困難です。そのためAIが取得する情報に偏りが出て、全体の文脈を正しく理解できなかったり、誤った判断を下したりします。
大規模なデータが必要
マルチモーダルAIを高性能にするには、各モードに対応する膨大なデータ(例:画像+説明文、音声+字幕)が必要です。このデータを集めるのはコストが高く、プライバシーや著作権の問題が生じるリスクが高まります。
計算負荷が大きい
マルチモーダルAIは複雑なモデルを使用しており、特に深層学習モデルをトレーニングするためには、大規模なデータセットと高性能なハードウェアが必要です。しかし、大規模なデータセットや高性能なハードウェアは高額なため、コスト面での課題が生じています。
説明責任の欠如
マルチモーダルAIはブラックボックス化しやすく、「なぜその答えを出したのか」を説明するのが難しい場合があります。例えば、「画像を見て判断したのか、説明文を読んで判断したのか」を明確にできません。これがAIの信頼性を低下させたり、説明責任の欠如に繋がったりします。
セキュリティ・プライバシーへの配慮が必要
マルチモーダルAIに画像や動画、音声をアップロードする場合、個人情報や機密情報が含まれやすい点にも注意が必要です。
クラウドサービスにデータを送る際は、暗号化やアクセス制御、データの保存ポリシーなどを確認し、自社のセキュリティポリシーに沿った運用ルールを整えることが重要です。
企業向けサービスでは、プロンプトやファイルを学習に利用しないオプションが用意されているかどうかもチェックしておくと安心です。


マルチモーダルAIは幅広い将来性を持つ!
マルチモーダルAIは、テキスト・画像・音声・動画など、異なる情報を同時に処理したり、出力したりするAI技術で高い注目を浴びており、現在ではさまざまな企業が開発を行っています。
マルチモーダルAIは多数登場しており、今後も増え続けることが予想されます。現状では課題もありますが、研究が進むにつれ精度が向上し、より利便性が増していくことでしょう。
現在でも医療分野や車の自動運転、産業用ロボットなどに活用事例もあります。日々精度が向上しているので、今後も幅広い分野で導入が進んでいくことでしょう。
今後もマルチモーダルAIに着目し、自身の業務に取り入れられるモデルを見つけた際は積極的に導入を検討してみてください!

最後に
いかがだったでしょうか?
マルチモーダルAIの活用で、テキストや画像、音声、動画の統合処理を実現し、業務効率や成果を劇的に向上させる方法を検討してみてください。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。
- ※1:マルチモーダルAIとは?事例から見る活用方法や今後の展望を解説
- ※2:Expressive Visual Text-to-Speech Using Active Appearance Models
- ※3:GPT-4で「マルチモーダル」の威力痛感、アプリの世代交代に技術者は生き残れるか
- ※4:「ChatGPT」が見て、聞いて、話せるように ~音声・画像対応のマルチモーダルAI
- ※5:1枚の静止画から動画作成する「AnimateDiff」、Googleの画像学習改良版「HyperDreamBooth」など5本の重要論文を解説(生成AIウィークリー)
- ※6:マルチモーダルAIとは?身近な事例で解説します!
- ※7:https://openai.com/research/gpt-4?ref=subanima.org
- ※8:https://blog.google/technology/ai/google-gemini-update-sundar-pichai-2024/
- ※9:【マルチモーダル対応】BingAIチャットが画像解析のAI機能を追加!スマホアプリで手軽に使おう【無料です】
- ※10:NEC 、理化学研究所、日本医科大学、電子カルテとAI技術を融合し医療ビッグデータを多角的に解析
- ※11:AIが生成した材料の構造画像を用い、物性を予測する技術を開発
- ※12:https://monoist.itmedia.co.jp/mn/articles/2101/29/news055.html
- ※13:https://news.kddi.com/kddi/corporate/newsrelease/2023/11/13/7077.html
- ※14:大規模マルチモーダルモデルを用いたロボカップサッカー標準プラットフォームリーグにおける自動実況システム
- ※15:教育を変える!マルチモーダルAIの可能性とは

【監修者】田村 洋樹
株式会社WEELの代表取締役として、AI導入支援や生成AIを活用した業務改革を中心に、アドバイザリー・プロジェクトマネジメント・講演活動など多面的な立場で企業を支援している。
これまでに累計25社以上のAIアドバイザリーを担当し、企業向けセミナーや大学講義を通じて、のべ10,000人を超える受講者に対して実践的な知見を提供。上場企業や国立大学などでの登壇実績も多く、日本HP主催「HP Future Ready AI Conference 2024」や、インテル主催「Intel Connection Japan 2024」など、業界を代表するカンファレンスにも登壇している。


