
【徹底検証】ChatGPT搭載の自社専用ボットの作り方3選!実際に性能を検証してみた!

みなさんは、ChatGPTに自社データを学習させた「自社専用チャットボット」が作成できるのをご存知ですか?
自社専用チャットボットがあれば、業務効率化だけでなく、コスト削減や社員の自己解決率の向上など、企業にとって大きなメリットがもたらされます。しかし、「作り方がわからない」という方も多いでしょう。
本記事では、ChatGPTに自社データを学習させたチャットボット3種類の開発手法について解説していきます。実際の検証結果をもとに3種類のボットの回答精度も比較していますので、ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
自社専用チャットボットの開発手法について
今回、チャットボットは次の3つの手法で開発しました。

簡単に概要と、各要素についてまとめます!
| 開発手法 | Python + GPT3 | ChatBotKit | DocsBot |
|---|---|---|---|
| 概要 | OpenAIのGPT3ライブラリを利用した開発 | ノーコードで、チャットボットが作成できるツール | ノーコードでチャットボットが作成できるツール |
| 作りやすさ(ノーコードかどうか) | △ | ○ | ○ |
| 導入のしやすさ | △ | △ | ○ |
| 精度 | ○ | △ | △ |
| 書類データ(pdf,wordなど)の読み込ませやすさ | △(※要コーディング) | ○ | ○ |
| 費用 | ○従量課金 | △$25〜 | △$19〜 |
各要素について、表だけでは伝わらない内容を補足しております。
- 作りやすさ
- ChatBotKit、DocsBotはともに、すでに出来上がっているサービス(いわゆるSaaS)のため、割と簡単です。
- Python + GPT3は、インフラ構築などが必要なため面倒に感じる方もいるでしょう。
- 運用のしやすさ
- ChatBotKitは、SlackやDiscordとデフォルトで連携できるため、運用しやすいです。
- DocsBotは、WEBサイトに組み込めるウィジェット機能の実装予定があるため、将来的にはどんどん運用しやすくなるでしょう。
- Python+GPT3は、作りやすさ同様インフラ管理が必要であり、前者2つと比較して運用コストが掛かります。
- 精度
- Pythonで作ったものがもっとも高く、その他の精度が少し下がります。(当社調べ)
検証項目なども含めて、次の見出しで詳しくお伝えします。
- Pythonで作ったものがもっとも高く、その他の精度が少し下がります。(当社調べ)
- 書類データ(PDF, Wordファイル等)の読み込ませやすさ
- ChatBotKitとDocsBotは、GUIでポチポチしたら簡単にできます。
- Python + GPT3の場合は、プログラミングが必要なため、やや難しいかも。
- 費用
- OpenAI本家を利用した方が安くなるでしょう。
なお、AIチャットボットの概要について知りたい方はこちらをご覧ください。



精度の検証方法と結果
今回の検証にあたり、次のような質問事項と基準を用意しました!
作成したボットは3種とも、弊社WEELが外部に公開している資料や一部公開してもいい社内情報を学習してます。
| ボットへの入力 | 判断基準 | Python + GPT3 | ChatBotKit | DocsBot |
|---|---|---|---|---|
| 会社の基本情報を教えてください | 基本情報(住所、資本金、事業内容、従業員数)を提示できているか | ○ | × | × |
| 製品やサービスの詳細を教えてください | 事業内容(SaaS連携、ChatGPT等)について触れているかどうか | × | × | × |
| 営業時間やサポート対応時間を教えてください | 学習させていないので、”ない”と答えるか | ○ | × | ○ |
| 私のニーズに合った製品やサービスを提案してください | ニーズを聞く力があるか、顧客の需要を把握し提案できるか | △(もう一歩) | × | × |
| 英語/中国語/スペイン語で情報を提供してください | 日本語以外の言語でも回答できるか | △(英語のみ) | △(英語のみ) | × |
| 企業/個人/パートナー企業向けの情報を教えてください | 学習させてないので、”ない”と答えるか | × | ○ | × |
精度の良さは次の順番でした。
- Python + GPT3
- ChatBotKit
- DocsBot
Python + GPT3のほうが、他2つより精度が良いという結果になりました!
実際の検証結果(スクショあり)
ここでは、実際の検証結果を見ていきましょう。各ボットの回答(一部抜粋)をキャプチャしたので、以下に貼り付けています。
3種を確認する前に、まずは本家であるChatGPT3.5を確認してみましょう!
弊社について学習させていないので、以下のようになります。

ChatBotKit
うまく回答できていないですね。
情報は間違っているし、会社の基本情報(住所、資本金、事業内容、従業員数など)が出せていません。
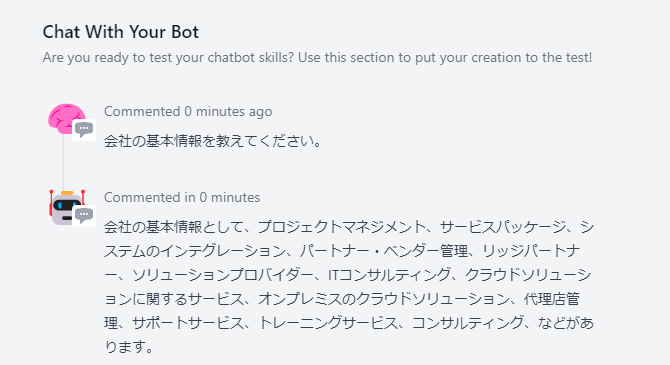
DocsBot
こちらは必要そうな情報を、分けて表示している!
ものすごくホスピタリティがあっていいのですが大外れ……!
山田太郎さん……だれやねん!?笑
設立が2010年……そんなに古くない!
しっかり学習させているはずなのですが……

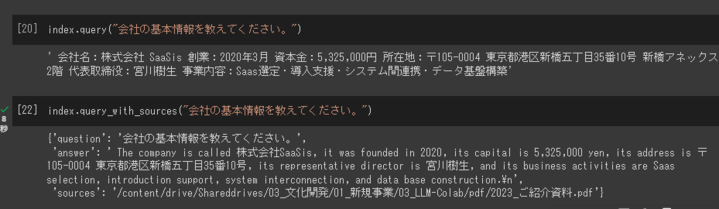
Python + GPT3
query()という関数で質問を入力した場合は成功! したのですが、どのファイルを参考にしたのかを表示しようとすると、なぜか英語で返答されてしまいます。
各ボットの回答を確認して、GPT3系を使っているため精度がいまいちな場合があるのかなぁと。
GPT4を使って精度が上がるのであれば、コンサルや営業をボットに置き換えられるかもしれません。
ツール自体はGPT4に対応しているので、APIキーを取得でき次第、再度実験したいと思います。
なお、自社AIチャットボットを作れる神ツールについて詳しく知りたい方は、下記の記事を合わせてご覧ください。

ChatGPTに自社データを学習させるその他の方法
ここでは、ChatGPTそのものに自社データを学習させ、自社専用ChatGPTを作成する方法をご紹介します。
上記でご紹介したチャットボットの開発手法とは異なり、AI人材が必要になるものもありますが、自社専用チャットボットを作成するうえで知っておいて損はありません。
今回ご紹介する方法は以下の4つです。
- プロンプトエンジニアリング
- ファインチューニング
- エンベディング
- RAG
1つずつ解説していきます。
プロンプトエンジニアリング
1つ目の方法は、プロンプトエンジニアリングによるデータの学習です。プロンプトエンジニアリングとは、ChatGPTに入力する質問や指示の内容を工夫することで、適切な回答を引き出すことを指します。
ChatGPTに入力する質問や指示に、自社データをテキストで入力したり、CSV、PDFファイル、URLなどを添付することで、自社データを学習した回答を得ることができます。
プロンプトエンジニアリングは、専門知識やスキルが必要ないため非エンジニアでも実行可能です。
ただし、プロンプトエンジニアリングでは入力できるデータ量に限りがあるため、膨大な顧客とのやりとりや社内データなどを学習させることには向いていません。
ファインチューニング
2つ目の方法は、ファインチューニングによるデータ学習です。ファインチューニングによる学習では、ChatGPTの提供するAIモデルに自社データを学習させることで、モデル自体を自社専用のものにアップデートします。
自社の業界や事業領域、特定のタスクに対して高精度で活用可能な自社専用のChatGPTを構築することができます。
モデル自体が自社のニーズにカスタマイズされたものになっているため、誰でも簡単に自社独自のChatGPTを利用できます。
ただし、ファインチューニングには設計と実装に高度なエンジニアリング知識やスキルが必要なため、AI人材による開発体制を整えなければなりません。
また、学習させるデータが少ないとAIが既に学習している情報に引っ張られてしまい、管理者が意図していない回答を提示してしまう可能性があるため、学習させる大量のデータを用意する必要があります。
エンベディング
3つ目の方法は、単語や文章などの人が使う言語を数値化(ベクトル化)するエンべディング(埋め込み)でデータを学習させる方法です。
数値化(ベクトル化)した情報を管理するベクトルデータベースを作ることで、ChatGPTへの質問文も数値化し、類似した数値から回答を提示できるようになります。これはGoogle検索にも使われており、AIが大量のデータを効率的に使うのに適しています。
エンべディングは、OpenAIが提供しているエンべディング用APIを使って実装できますが、Pythonコードを使うのでプログラミングの知識が必要です。
RAG
4つ目の方法は、RAG(Retrieval-Augmented Generation)によるデータ学習です。RAGとは、ChatGPTが質問に回答する際にChatGPTのデータベースに加え、膨大な自社のデータベースから情報を検索し回答させるように自社データを組み込む手法のことを指します。
プロンプトエンジニアリングと異なり、膨大な量のデータを学習させることができるため、自社データをフル活用した業務効率化やサービス創出が可能となります。
また、ChatGPTと自社のデータベースが接続されており、常に最新のデータを活用した回答を得ることも可能です。
ただし、RAGには設計と実装に高度なエンジニアリング知識やスキルが必要なため、AI人材による開発体制を整える必要があります。
なお、AIチャットボットの作り方についてさらに詳しく知りたい方は、下記の記事を合わせてご覧ください。

今回開発したPythonプログラムについて
Phytonプログラムを以下に記載しておきます。
お好きなインフラ環境でスクリプトを実行すると、質問に対しての回答が返ってきます。
ご自身の環境に合わせて変更したうえでご利用ください。
import os
# APIキー
OPENAI_API_KEY = "your-APIKEY" #@param {type:"string"}
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
# 学習させるPDFの格納先
PDF_DIR = "/your/path/to/directory/"
import glob
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.agents import initialize_agent, Tool
from langchain.llms import OpenAI
from langchain.indexes import VectorstoreIndexCreator
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from gpt_index import LangchainEmbedding
from gpt_index import GPTSimpleVectorIndex, SimpleDirectoryReader
from gpt_index.indices.prompt_helper import PromptHelper
from gpt_index import download_loader
tools = []
files = glob.glob(PDF_DIR + '/*')
# 日本語モデル埋め込み
embedding = HuggingFaceEmbeddings(
model_name="oshizo/sbert-jsnli-luke-japanese-base-lite"
)
loaders = [UnstructuredPDFLoader(f) for f in files]
index_creator = VectorstoreIndexCreator(
embedding=embedding,
text_splitter=CharacterTextSplitter(chunk_size=200, chunk_overlap=20)
)
index = index_creator.from_loaders(loaders)
index_creator = VectorstoreIndexCreator(
embedding=embedding,
text_splitter=CharacterTextSplitter(chunk_size=200, chunk_overlap=20)
)
res = index.query_with_sources("会社の基本情報を教えてください。") #()の中には質問を入れる
print(res["sources"])
print(res["answer"]) #回答が出力されます

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

