
画像生成AI「Stable Diffusion 3」とは?性能や使い方を徹底解説!

2024年2月23日、Stability AIから最新の画像生成AIである「Stable Diffusion 3」が公開されました!
2022年のStable Diffusion 1.4のリリース以来、Stability AIはStable Diffusion1.5、2.0 、2.1、XL、XL Turboと次々にバージョンアップモデルをリリースし、今回のStable Diffusion 3を発表しました。
その進化は目覚ましく、Stable Diffusion 3は前バージョンと比較して、複数の主題のプロンプトへの対応力、画像品質、テキスト生成の品質が大幅に向上しています。
以下が、Stable Diffusion 3で生成された画像とそのプロンプトです。
Prompt
Resting on the kitchen table is an embroidered cloth with the text 'good night' and an embroidered baby tiger. Next to the cloth there is a lit candle. The lighting is dim and dramatic.
この記事では、Stable Diffusion 3の特徴や使い方を詳しく解説していきます。最後まで目を通していただくと、Stable Diffusion 3の使い方を理解できるので、より高度な画像生成ができるようになるでしょう。
\生成AIを活用して業務プロセスを自動化/
Stable Diffusion 3の概要
Stable Diffusion 3は、2024年2月23日にStability AIが公開した最新の画像生成AIです。
すでに、Stability AI Developer Platform APIで利用ができるほか、Stable Diffusion 3 Mediumも公開されています。このモデルは、これまでのStable Diffusionシリーズと比較して、複数主題のプロンプト、画質、スペリング能力が大幅に向上しており、現在最も高性能な画像生成AIのうちの一つです。
特に注目すべき点は、従来の画像生成AIでは難しかった画像内での文字の表示も可能になっています。(アルファベット限定)
以下の画像は、Stable Diffusion 3で生成された画像です。
Prompt
Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says "Stable Diffusion 3" made out of colorful energy
非常に高品質であることに加え、しっかりと指定した文字が画像内に表記されていますね!
試しに、これと全く同じプロンプトでStable Diffusion 2.1に出力させてみましょう。結果はこのようになりました。

画像内に文字を表記することはできず、画像の品質もStable Diffusion 3より劣っていることが分かります。
そんなStable Diffusion 3は、800Mから8Bのパラメータを持つモデルが提供され、ユーザーのニーズに最適な形で応えるため、拡張性と品質に関するさまざまなオプションを用意しています。
なお、Stable Diffusion 3.5について詳しく知りたい方は、下記の記事を合わせてご確認ください。

そもそもStable Diffusionとは
Stable Diffusionは、テキスト形式でプロンプトを入力して画像を生成できる、画像生成AIの代表格ともいえるモデルです。Stable Diffusionを搭載したツールやサービスは、無料で利用できるものも多く、初心者でも手軽に画像生成できるのが特徴です。
そのまま使ってもある程度思い通りの画像を生成できますが、ファインチューニングなどの追加学習させることでより高度な指示に沿った精度の高い画像を生成できます。
ここでは、Stable Diffusionについて以下3つの基本的な情報を解説していきます。
- Stable Diffusionのシリーズとおすすめのモデル
- Stable Diffusionの利用方法
- Stable Diffusionの商用利用について
Stable Diffusion 3 の利用に伴い、改めてStable Diffusionを詳しく知っておきたい方は参考にしてみてください。
Stable Diffusionのシリーズとおすすめのモデル

2025年8月8日現在、Stable Diffusionは以下のシリーズを主要なコアモデルとして展開しています。
・Stable Diffusion 3.5 Large
パラメータ数80億を誇り、Stable Diffusionファミリーの中で最も高性能。プロフェッショナル用途に最適です。
・Stable Diffusion 3.5 Large Turbo
Stable Diffusion 3.5 Largeの軽量化バージョン。SD3.5 Large Turboは、わずか4ステップで高品質な画像を生成できることが特徴です。
・Stable Diffusion 3.5 Medium
25億のパラメータ数を持ち、プロンプトの正確さと画像品質のバランスに優れている。高速かつ高性能な画像生成が得意です。
・Stable Diffusion 3.5 Flash
Stable Diffusion 3.5 Medium軽量モデル。SD3.5 Flash はMedium よりもさらに高速に動作します。
また、HuggingFaceではStable Diffusion 2.1やStable Diffusion 3も利用可能です。
次に、Stable Diffusionで利用できるおすすめのモデルの一覧です。
・yayoi_mix
・BRA V6
・CityEdgeMix
・HimawariMix
これらのモデルは、Hugging FaceやCIVITAIなどでダウンロードして使用でき、それぞれ実写モデルやアニメ調などに特化した画像を生成できるのが魅力です。
Stable Diffusionで利用できるモデルのダウンロード方法が知りたい方は、以下の記事をご覧ください。

Stable Diffusionの利用方法
Stable Diffusionの利用方法は、大きく分けてWebブラウザで利用する方法とローカル環境で利用する方法の2種類があります。
それぞれの特徴は以下のとおりです。
- Webブラウザで利用:PCのスペックに左右されないので低スペックPCでも手軽に画像を生成できる
- ローカル環境:高スペックなPCが必要だが枚数制限などがなく自由度が高い
初めてStable Diffusionを利用するなら、手軽に試せるWebブラウザ上での利用がおすすめです。Stable Diffusion Web UIをダウンロードしてWebアプリ上で使う方法やgoogle colabなどで呼び出す方法があります。
一方、枚数制限の制約をなくしたい方やカスタマイズ性を高めたい方は、自身のPCにStable Diffusionをインストールしてローカル環境で使いましょう。
Stable Diffusionの商用利用について
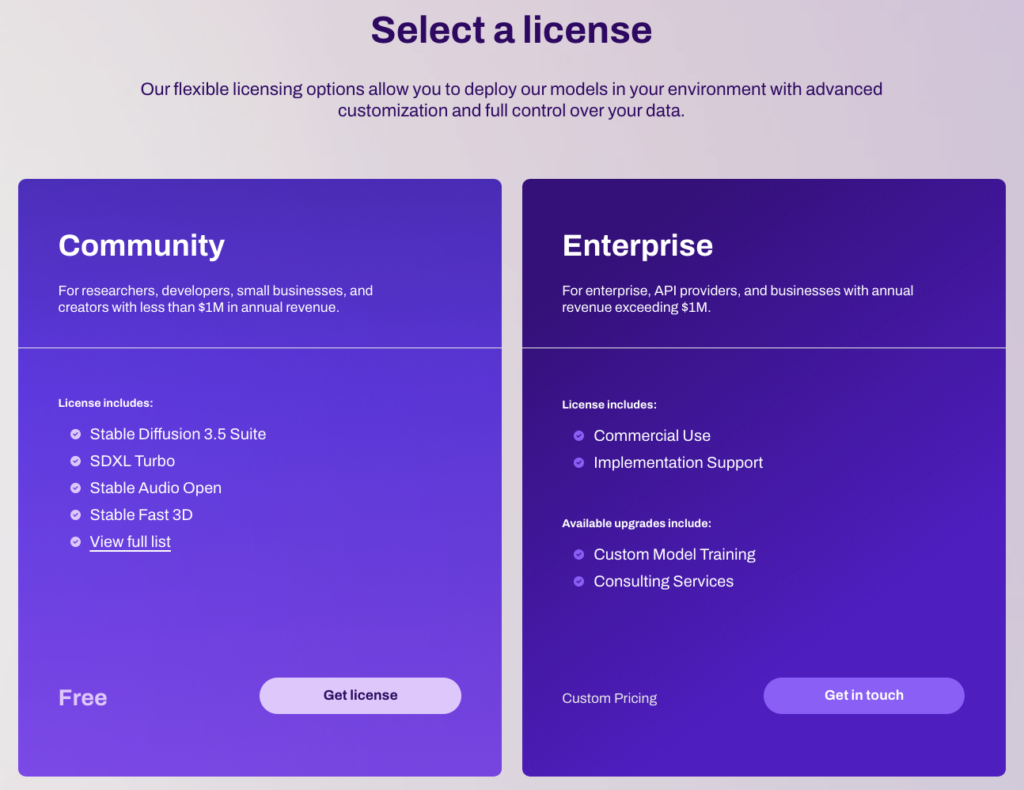
2025年8月8日現在、Stability AIは下記の2つのライセンス形態を提供しています。いずれのライセンスもStability AIへの登録が必要となります。
・Community
年間収益が100万ドル未満の研究者、開発者、中小企業、クリエイター向け。
・Enterprise
エンタープライズ、API プロバイダー、年間収益が100 万ドルを超える企業向け。
コミュニティライセンスの場合、年間収益が100万ドル未満であれば商用利用も可能です。
また、Hugging FaceやCIVITAIからモデルをダウンロードする場合は、モデルによって商用利用の可否が異なるので、ページの記載をよく確認しましょう。なお、商用利用が許可されている場合でも、著作権を侵害する可能性がある画像の商用利用はできません。とくに、image to imageで画像生成した場合は注意が必要です。
Stable Diffusionの基本的な情報をもっと詳しく知りたい方は、以下の記事をご確認ください。

Stable Diffusion 3で使用されている技術
ここからは、Stable Diffusion 3で使用されている技術について紹介します。
なお、詳細な技術レポートはまだ公開されていませんので、ここでは軽い概要の紹介のみとなりますが、技術レポートが公開され次第判明した内容を追記します。
拡散トランスフォーマー・アーキテクチャ
Stable Diffusion 3は、拡散トランスフォーマー・アーキテクチャという方法を後述するフローマッチングという技術と組み合わせて使用し、画像を生成しています。
これは、先日公開されて大きな反響を呼んでいるOpen AIのSoraと同様の手法です。
拡散トランスフォーマー(Diffusion Transformer)は、従来の拡散モデルの主要コンポーネントであるU-Net畳み込みニューラルネットワーク(CNN)をトランスフォーマーに置き換えたものです。
これにより、画像からノイズを除去していく学習プロセスを改善しており、主に画像の潜在表現(より単純な形式)にノイズを加え、それを徐々に取り除くことで新しい画像を生成します。
このアプローチにより、効率的にスケールアップするだけでなく、より高品質の画像を生成できます。
以下の画像は、拡散トランスフォーマーのスケールアップによる効果を可視化したものです。

さらに、Stability AIのCEO、Emad Mostaque氏は、以下のポストの中で、「さらに拡張できるだけでなく、マルチモーダル入力にも対応できる」と述べています。
これは技術レポートの公開や、モデルの一般公開が楽しみですね!
なお、拡散トランスフォーマー・アーキテクチャの詳細については、以下の論文をお読みください。
Scalable Diffusion Models with Transformers
フロー・マッチング
Stable Diffusion 3では、ランダムなノイズから構造化された画像にスムーズに移行する方法を学習して画像を生成できるAIモデルを作成する技術である「フロー・マッチング」も利用しています。
フロー・マッチングは、連続正規化フロー(Continuous Normalizing Flows、CNF)を効率的に訓練するためのシミュレーションフリーなアプローチを提供し、生成したいデータの種類に応じて、より正確かつ高品質な結果を得ることが可能になります。
フロー・マッチングについて、より詳しく知りたい方は、以下の論文を参照してください。
Flow Matching for Generative Modeling
このように、Stable Diffusion 3は、新しい手法や技術を組み合わせることで、かつてない程高品質な画像生成および拡張性を獲得しました。
さらに、CEOのEmad Mostaque氏は、ユーザーの「Stability AIがより多くの GPU を獲得した場合、SD3とStablevideoをトレーニングしてSoraレベルのモデルを構築できる可能性がある」というポストに対して、以下のように返答しています。
本当に。SD3アーチはビデオや画像以上のものを受け入れることができる。
我々は、この分野で他社の100分の1以下のリソースしか持っていない。
リソースさえあればSoraレベルのモデルを開発できますが、リソースが圧倒的に足りないと言っています。
何とかリソースの問題を解決して、OpenAIに並ぶような企業になってほしいですね!


Stable Diffusion 3で生成された画像をDALL-E 3で生成した画像と比較してみた!
ここからは、Stable Diffusion 3で実際に生成された画像を、同じプロンプトでDALL-E 3で生成した画像と比較しながら紹介します。
早速見ていきましょう!
まずは以下の画像です。
Prompt
cinematic photo of a red apple on a table in a classroom, on the blackboard are the words "go big or go home" written in chalkStable Diffusion 3

プロンプトが忠実に再現され、指定した文字もしっかり表示されていますね!
以下が同じのプロンプトでDALL-E 3で生成した画像です。
DALL-E 3

さすがDALL-E 3ですね、プロンプトを忠実に再現した高品質な画像を生成してくれました。
クオリティも再現度もほぼ同等であり、Stable Diffusion 3はあのDALL-E 3に迫る性能を有していることが分かります。
もう一枚見てみましょう。
Prompt
Three transparent glass bottles on a wooden table. The one on the left has red liquid and the number 1. The one in the middle has blue liquid and the number 2. The one on the right has green liquid and the number 3.Stable Diffusion 3

こちらもプロンプトを忠実に再現した高品質な画像を生成できていますね。
そしてこちらがDALL-E 3で生成した画像です。
DALL-E 3

こちらもStable Diffusion 3と同様に、プロンプト通りの高品質な画像を生成しました。
今回の比較から、Stable Diffusion 3はDALL-E 3とほぼ同等の性能を有しているといえます。
また、Stable Diffusion 3がDALL-E 3より優れている点として、オープンソースモデルであることが挙げられます。
オープンソースモデルであるため、一般公開後はモデルをローカルにダウンロードして実行することも可能で、さらに出力を変更するための微調整も行うことができます。
なお、今回比較対象にしたDALL・E3について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Stable Diffusion 3は、DALL-E 3レベルの超高性能画像生成AI!
Stable Diffusion 3は、2024年2月23日にStability AIが公開した最新の画像生成AIです。
話題沸騰中のOpenAI Soraにも使われている、「拡散トランスフォーマー・アーキテクチャ」という手法を、「フロー・マッチング」という技術と組み合わせることで、これまでにない高品質な画像生成を可能にしています。
具体的には、画像品質の向上やプロンプトの再現度向上はもちろん、これまで難しいといわれていた画像内での文字の表記を実現しています。
さらに、Stable Diffusion 3はオープンソースモデルであるため、ローカルにダウンロードして実行やチューニングを行って、自分好みにカスタマイズすることも可能であり、その点はユーザー目線で言えばDALL-E 3より優れているといえます。
なお、2024年6月に公開されたStable Diffusion 3 Mediumは、モデルが小さいため、個人向けシステムや企業向けGPUなどで動作させられるのも魅力です。
Stable Diffusion 3 APIの公開
2024年4月17日、Stable Diffusion 3およびStable Diffusion 3 TurboがStability AI Developer Platform APIで利用可能になりました!
Stability AIはこれらのモデルを提供するにあたり、市場で最も高速かつ信頼性の高いAPIプラットフォームであるFireworks AIと提携しています。
現時点でモデルは利用可能ですが、Stability AIは近い将来、Stability AIメンバーシップでモデルのウエイトを利用できるようにすることを目指しています。
また、Stable Diffusion 3を搭載したチャットボットである「Stable Assistant Beta」の早期リリースに参加するユーザーを限定数募集しています。
こちらは、より気軽にStable Diffusion 3を利用して画像を生成できるので、期待大です!
ここからは、Stable Diffusion 3 APIの利用方法を解説し、実際に使ってみたいと思います。
Stable Diffusion 3 APIの使い方
Stable Diffusion 3 APIの利用方法は、以下のサイトに詳しく書かれています。
まずは、Stability AIのアカウントにサインイン(登録していない場合はサインアップ)します。
https://platform.stability.ai/account/
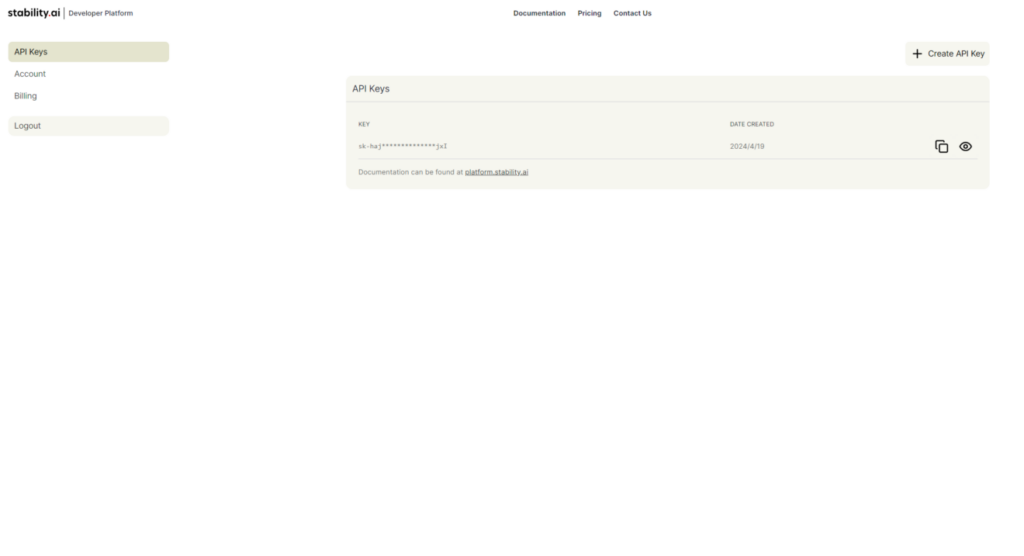
サインインしたら、画像のようにAPIキーを取得してください。
なお、アカウントを新規作成した場合は25クレジットが無料付与されます。
クレジット残数の確認や、課金などはBillingページから行えます。
これでAPIを利用するための事前準備は完了です。
ここからは実際にPythonを使って、Stable Diffusion 3 APIを利用してみます。
とはいってもその利用方法はそれほど難しくなく、以下のコードを実行するだけです。
import requests
response = requests.post(
f"https://api.stability.ai/v2beta/stable-image/generate/sd3",
headers={
"authorization": f"Bearer Bearer sk-MYAPIKEY",
"accept": "image/*"
},
files={"none": ''},
data={
"prompt": "dog wearing black glasses",
"output_format": "jpeg",
},
)
if response.status_code == 200:
with open("./dog-wearing-glasses.jpeg", 'wb') as file:
file.write(response.content)
else:
raise Exception(str(response.json()))“authorization”の部分には自分のAPIキーを入力し、”prompt”や”output_format”なども必要に応じて変更してください。
また、このコードで指定しているもの以外にも、modeリクエストを追加して、image-to-imageに変更したり、ネガティブプロンプトや出力画像のアスペクト比を設定できます。
なお、SD3 Turboを使用する場合はこのようになります。
import requests
response = requests.post(
f"https://api.stability.ai/v2beta/stable-image/generate/sd3",
headers={
"authorization": f"Bearer Bearer sk-MYAPIKEY",
"accept": "image/*"
},
files={"none": ''},
data={
"model": "sd3-turbo",
"prompt": "dog wearing black glasses",
"output_format": "jpeg",
},
)
if response.status_code == 200:
with open("./dog-wearing-glasses.jpeg", 'wb') as file:
file.write(response.content)
else:
raise Exception(str(response.json()))では、試しにこちらのコードでSD3およびSD3 Turboで同じプロンプトを使用して画像を生成させてみましょう!
SD3

SD3 Turbo

このように、公開前に生成例として公開されていた画像たちと同等の非常に高クオリティな画像を生成してくれました。
ちなみに、SD3は文字を含んだ画像も生成できるので、その機能も試してみましょう。
以下のプロンプトを入力します。
Dog with a collar marked Pochi.結果はこうなりました。
SD3

SD3 Turbo

SD3-Turboのものは、”Pohi”になってしまっていますが、SD3はしっかり指示通りの文字を含んだ画像を生成してくれました。
ここからは、Stable Diffusion 3 APIの料金体系を紹介します。
Stable Diffusion 3 APIの料金体系
Stable Diffusion 3 APIの料金は以下のようになっています。

SD 3 Largeは1回の画像生成ごとに6.5クレジット、SD 3 Large Turboは1回の画像生成ごとに4クレジットかかります。(失敗した場合は料金は発生しません)
これは従来のSDXL 1.0の0.9クレジットと比較して、かなり高額な料金体系になっています。なお、$10で1000クレジットを取得できるので、SD 3は1枚あたり$0.065、SD 3 Turboは1枚あたり$0.04です。
参考までにDALL-E3の料金との比較表です。
| モデル | 画質 | 料金 |
|---|---|---|
| SD 3 Large | – | 0.065ドル/枚 |
| SD 3 Large Turbo | – | 0.04ドル/枚 |
| DALL-E 3 | Standard | 0.04ドル/枚 |
| DALL-E 3 | Standard | 0.08ドル/枚 |
| DALL-E 3 | HD | 0.08ドル/枚 |
| DALL-E 3 | HD | 0.12ドル/枚 |
DALL-E3と比較すると、決して高いわけではなく、DALL-E3のHD画質のものより安い料金になっています。
なお、Appleが公開した画像生成AI「Matryoshka」が気になる方は、以下の記事をご覧ください。

Stable Diffusion 3で自分好みの高品質な画像を生成しよう!
Stable Diffusion 3 APIの公開によって、ついにStable Diffusion 3が利用できるようになりました!
使用できるモデルは、Stable Diffusion 3およびStable Diffusion 3 Turboの2種類であり、それぞれの料金はこちらです。
| モデル | 料金 |
|---|---|
| SD 3 Large | 0.065ドル/枚 |
| SD 3 Large Turbo | 0.04ドル/枚 |
また、2024年6月には、サイズの小さいモデルとしてStable Diffusion 3 Mediumも公開されています。
Stability AIはこれらのモデルを提供するにあたり、市場で最も高速かつ信頼性の高いAPIプラットフォームであるFireworks AIと提携しています。
今回は、PythonでAPIからStable Diffusion 3を使用する方法を紹介しましたが、Hugging Face SpaceやComfyUIで直感的に利用できる方法も続々と公開されています。
リンクを載せておきますので、気になった方はこちらも併せてご確認ください。
皆さんもStable Diffusion 3で自分好みの画像を生成しましょう!

最後に
いかがだったでしょうか?
Stable Diffusion 3を活用すれば、クリエイティブ制作の効率化や独自モデルの開発など、事業に直結する可能性が広がります。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


