
Gemini 3.1 Flash-Liteとは?低コスト高速AIの特徴・料金・実装方法まとめ

- 低コストかつ高速応答を実現するGemini 3シリーズの軽量モデル
- 推論量を調整できる「thinking levels」による速度と精度の柔軟な制御
- テキスト・画像・音声・動画などに対応するマルチモーダルAIモデル
2026年3月、GoogleのGeminiシリーズに新たな軽量モデルが登場しました。
今回公開された「Gemini 3.1 Flash-Lite」は、大量リクエスト処理を想定して設計された生成AIモデル。低コストで高速な応答を実現しながら、複雑なタスクにも対応できる推論能力を備えています。
特に注目されているのが、推論量を調整できる「thinking levels」という仕組み。用途に応じてAIの思考量を制御できるため、高速な応答が求められる処理から複雑な推論タスクまで柔軟に対応可能。また、テキストだけでなく画像や音声、動画、PDFなどの入力にも対応しており、マルチモーダルAIとして幅広い用途に利用できる点も特徴のひとつでしょう。
しかし、新しいAIモデルが登場するたびに「従来のGeminiモデルと何が違うのか」「どのような用途に向いているのか」「実際のプロダクトでどのように活用できるのか」といった疑問を感じる方も多いのではないでしょうか。
そこで本記事では、Gemini 3.1 Flash-Liteの概要や仕組み、特徴を整理しながら、どのような活用方法が考えられるのかを解説します。最後までお読みいただければ、Gemini 3.1 Flash-Liteがどのような思想で設計された生成AIモデルなのか理解できるはずです。
\生成AIを活用して業務プロセスを自動化/
Gemini 3.1 Flash-Liteの概要
Gemini 3.1 Flash-Liteは、Googleが開発した生成AIモデル「Gemini 3」シリーズの中で、最も高速かつコスト効率に優れたモデルです。
生成AIをプロダクトや業務システムに組み込むケースが増えた一方で、「推論コストの高さ」や「応答速度の遅さ」が大規模運用の障壁となる場面も少なくありませんでした。
こうした課題を解決するために登場したのがGemini 3.1 Flash-Liteです。高頻度なリクエスト処理を前提に設計されており、低レイテンシと低コストを両立する点が最大のポイント。
性能面では、前世代モデルと比べて応答速度が大幅に改善。最初の回答トークンが生成されるまでの時間は約2.5倍高速化し、出力速度も約45%向上しています。こうした性能向上により、リアルタイム性が求められるアプリケーションでも利用しやすいモデルです。
| 項目 | 内容 |
|---|---|
| モデル名 | Gemini 3.1 Flash-Lite |
| 提供元 | |
| リリース | 2026年3月 |
| 提供方法 | Gemini API / Vertex AI |
| 主な用途 | 大量リクエスト処理、リアルタイムAIアプリ |
| 特徴 | 低コスト・高速応答・推論量調整 |


Gemini 3.1 Flash-Liteの仕組み
Gemini 3.1 Flash-Liteは、応答速度と低コストを意識して開発されたモデルです。加えて、AI StudioとVertex AIでは「thinking levels」を標準で使えるため、タスクに応じてモデルがどれだけ推論するかを調整できます。
アーキテクチャと動作原理の考え方
「thinking levels」は、最小/低/中/高の思考レベルから選択でき、推論量をコントロールできます。
例えばリアルタイム性を優先する場面では思考を浅くし、複雑な指示に追従させたい場面では思考を深くする、といった使い分けが可能になりました。
一方で、内部のモデル構造そのものの詳しい説明は公開されていません。
構成モジュールと処理フロー
実装時の処理フローは、次の流れです。
- テキスト、コード、画像、音声、動画、pdfを投入
- 推論レベルを選択
- 必要に応じてシステム指示、関数呼び出し、構造化出力などを組み合わせ
- 生成結果をアプリ側で表示/保存/後続処理へ接続
この流れにより、翻訳やコンテンツモデレーションのような大量処理から、UIやダッシュボード生成のような複雑タスクまで幅広く扱えます。
主な仕様
本記事執筆(2026年3月)時点での提供形態としてはpre-GAの扱いで「現状のまま」提供され、サポートが制限されることがあります。運用に組み込むなら、段階的な検証から入るのが無難です。
| 項目 | 内容 |
|---|---|
| モデルID | gemini-3.1-flash-lite-preview |
| 入力 | テキスト/コード/画像/音声/動画/pdf |
| 出力 | テキスト |
| 最大入力トークン | 1,048,576 |
| 最大出力トークン | 65,535(デフォルト) |
| 思考レベル | 最小/低/中/高 |
| 機能対応(例) | Google検索によるグラウンディング、コードの実行、システム指示、関数呼び出し、構造化出力、トークンのカウント、コンテキストキャッシュ など |
なお、性能向上・高速化されたコーディングエージェントであるGPT-5.3-Codexについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Gemini 3.1 Flash-Liteの特徴
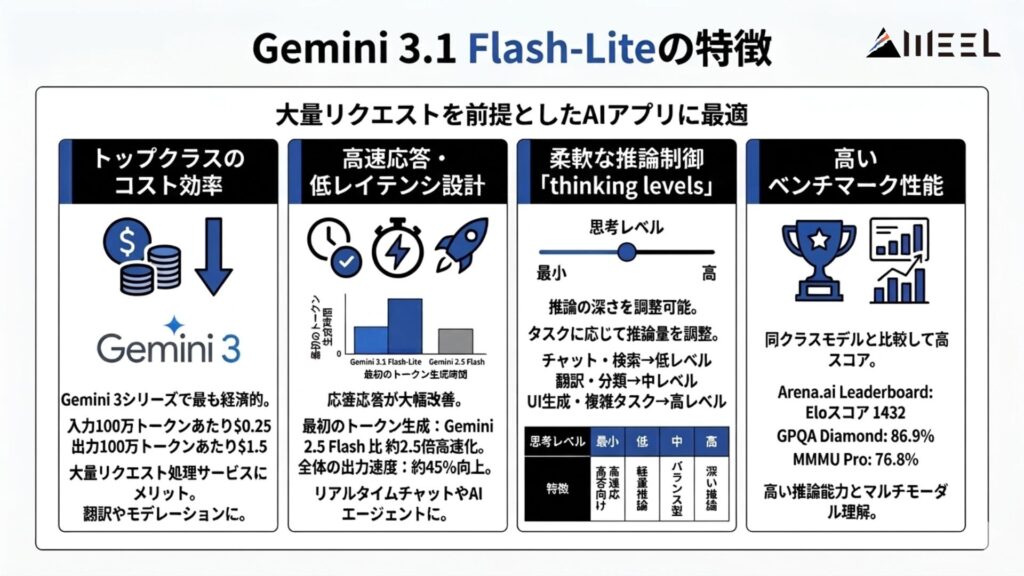
Gemini 3.1 Flash-Liteには、主に「高速性」「コスト効率」「柔軟な推論制御」「マルチモーダル対応」といった特徴があります。大量リクエストを前提としたAIアプリケーションに適した設計が大きな強み。
Geminiシリーズの中でもトップクラスのコスト効率
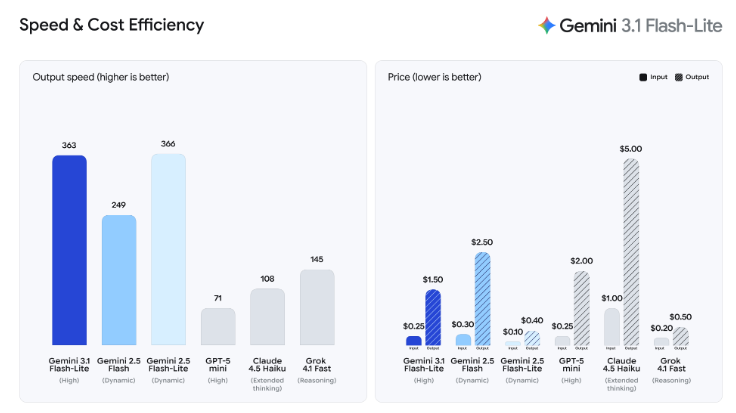
Gemini 3.1 Flash-Liteは、Gemini 3シリーズの中で最もコスト効率の高いモデルです。入力100万トークンあたり0.25ドル、出力100万トークンあたり1.5ドルの価格設定です。
この価格は、大量リクエストを処理するサービスにとって大きなメリットになります。翻訳やモデレーションなどの高頻度APIを運用する場合、モデル単価の差が月額コストに直結。
高速応答を実現する低レイテンシ設計
Gemini 3.1 Flash-Liteは、従来モデルよりも応答速度が改善されています。特に最初の回答トークンが生成されるまでの時間は、Gemini 2.5 Flashと比べて約2.5倍高速化しました。
さらに、全体の出力速度も約45%向上しています。リアルタイムチャットやAIエージェントなど、レスポンス速度がUXに直結するアプリでは重要なポイントです。
推論量を制御できる「thinking levels」
Google AI StudioとVertex AIでは、thinking levelsという仕組みが利用できます。これはモデルがどれだけ深く推論するかを調整する機能です。
| 思考レベル | 特徴 |
|---|---|
| 最小 | 高速応答向け |
| 低 | 軽量推論 |
| 中 | バランス型 |
| 高 | 深い推論 |
処理内容に応じて推論量を調整できるため、次のような使い分けができます。
- チャットや検索→低レベル
- 翻訳や分類→中レベル
- UI生成や複雑なタスク→高レベル
高いベンチマーク性能
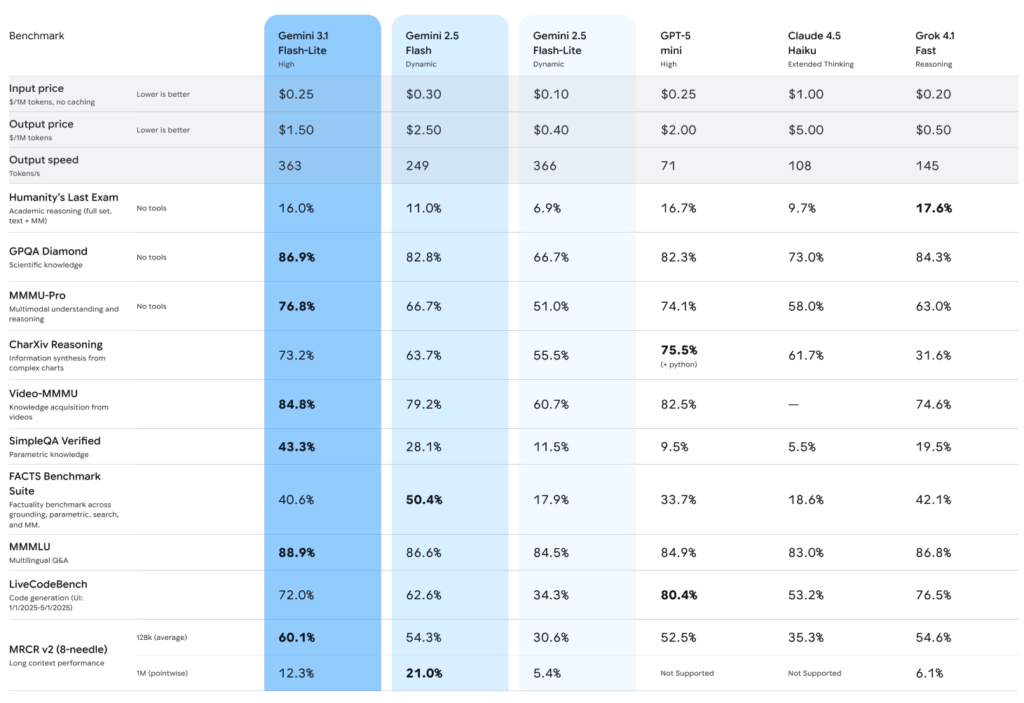
性能面でも、同クラスモデルと比較して高いスコアを記録しています。Arena.ai LeaderboardではEloスコア1432を達成しました。
GPQA Diamondで86.9%、MMMU Proで76.8%と、いずれも高い結果です。推論能力やマルチモーダル理解の高さを示す指標として注目されています。
なお、Z.aiが送り出す「エージェント時代」の最強オープンソースLLMであるGLM-5について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Gemini 3.1 Flash-Liteの安全性・制約
Gemini 3.1 Flash-Liteを導入する際には、性能だけでなく安全性や利用制約の理解も必要です。特に本モデルはプレビュー版として提供されているため、運用面での注意点もいくつかあります。
セキュリティ・運用上の前提
Gemini 3.1 Flash-LiteはGoogle CloudのAI基盤で提供されるモデルであり、Vertex AIやGemini API経由で利用するクラウド型AIサービスのため、Geminiのチャット画面ではモデルを選択することができません。
また、このモデルは現在プレビュー段階です。pre-GAのプロダクトは「現状のまま」で提供され、サポート範囲が限定される場合があります。長期運用を前提としたプロダクトに組み込む場合、段階的な検証を進めるのが現実的です。
マルチモーダル入力の技術的制限
マルチモーダルAIとしてさまざまなデータ形式を扱えるものの、それぞれの入力には個別の制限があることが公式で発表されています。
| データタイプ | 主な制限 |
|---|---|
| 画像 | プロンプトあたり最大3,000枚 |
| ドキュメント | 最大1,000ページ / 50MB |
| 動画 | 約45分(音声あり) / 約1時間(音声なし) |
| 音声 | 約8.4時間まで |
大量データを扱える設計ですが、AIアプリではファイルサイズや処理時間の影響を考慮する必要がありそうです。
Gemini 3.1 Flash-Liteの料金
Gemini 3.1 Flash-Liteは、トークンベースの従量課金モデルが採用されており、利用量に応じて費用が発生します。
入力トークンは100万トークンあたり0.25ドル、テキスト出力トークンは100万トークンあたり1.5ドルです。
この料金設定により、大量のAPIリクエストを処理するサービスでも比較的低コストで運用できます。
Gemini 3.1 Flash-Liteのライセンス
Gemini 3.1 Flash-LiteはGoogle Cloud上で提供されるAIサービスであり、一般的なオープンソースモデルとは利用形態が異なります。
現在の提供形態は、Google AI StudioもしくはVertex AIおよびGemini API経由で利用するクラウドサービス型モデルです。モデルの重みをダウンロードして自由に実行する形式ではなく、Google Cloudのサービス利用規約の範囲で利用します。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕ |
| 個人利用 | ⭕ |
| 改変 | ❌ |
| 配布 | ❌ |
| 特許利用 | 不明 |
プレビュー版としての注意点
Gemini 3.1 Flash-Liteは現在、pre-GA(一般提供前)のプレビュー版。pre-GAの機能は現状のままで提供され、サポートや仕様変更の可能性がある点に注意が必要です。
そのため、次のような対応が推奨されます。
- 本番導入前に十分なPoCを行う
- API仕様変更に備えた設計にする
- SLAやサポート範囲を事前に確認する
特に企業システムに組み込む場合、正式版への移行タイミングを見ながら導入を検討するのが現実的です。
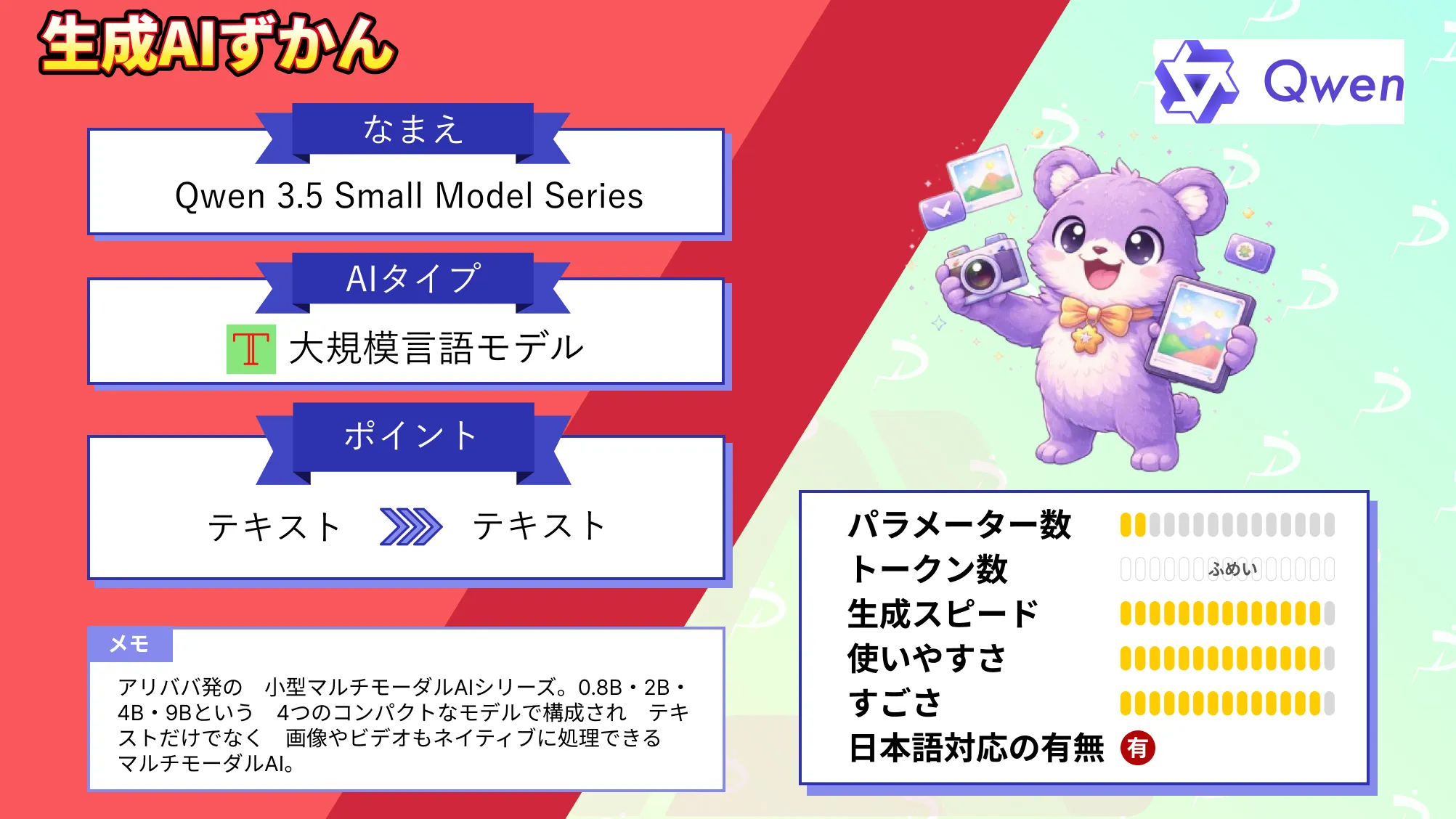
なお、アリババの0.8B〜9Bの小型マルチモーダルAIであるQwen 3.5 Small Model Seriesについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
【業界別】Gemini 3.1 Flash-Liteの活用シーン
Gemini 3.1 Flash-Liteは、高速処理と低コストを重視して設計された生成AIモデルです。大量リクエストを処理できる特徴があるため、リアルタイム性やスケール性が求められる業界での活用が期待されています。
ここではGemini 3.1 Flash-Liteの活用シーンについて考えていきます。
マーケティング・EC業界
マーケティングやECでは、大量の商品データやユーザーコンテンツを扱う必要があります。Gemini 3.1 Flash-Liteは低コストで大量処理が可能なため、こうした分野と相性の良いモデルです。
ECサイトでは商品説明文やレビュー分析などのAI処理が日常的に発生。モデルの低レイテンシ特性により、大量の商品ページを短時間で生成するような用途にも対応しやすいでしょう。
主なユースケースは次の通りです。
- 商品説明の自動生成
- レビューの感情分析
- 商品カテゴリ分類
- レコメンド用のテキスト生成
なお、リサーチ業務の効率化について、詳しく知りたい方は以下の記事も参考にしてみてください。

なお、ECサイト運営における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

SaaS・アプリ開発
生成AIを組み込んだSaaSサービスでは、応答速度と運用コストが非常に重要。Gemini 3.1 Flash-Liteは高速応答と低価格を重視したモデルのため、AI機能をプロダクトに組み込む用途に向いていると言えるでしょう。
具体的には次のような活用があります。
- AIチャットサポート
- ドキュメント要約
- UIやダッシュボードの自動生成
- AIエージェント機能
また、thinking levelsを使うことで推論量を調整できます。軽量な処理では高速応答を優先し、複雑な処理では深い推論を使うといった使い分けが可能です。
なお、生成AIによるシステム開発について、詳しく知りたい方は以下の記事も参考にしてみてください。

なお、生成AIを搭載したSaaSについて、詳しく知りたい方は以下の記事も参考にしてみてください。

カスタマーサポート
カスタマーサポートでは、大量の問い合わせ対応が必要。AIチャットボットやFAQ生成の用途では、低コストで高速応答できるモデルが特に重要です。
Gemini 3.1 Flash-Liteは高頻度ワークロード向けに設計されているため、問い合わせ対応の自動化にも適しているでしょう。
主な活用例は次の通りです。
- AIチャットボット
- FAQ自動生成
- メール返信のドラフト作成
- 問い合わせ内容の分類
こうした業務では1日に数万件以上のリクエストが発生することも珍しくありません。大量処理を前提とした設計が活きる分野です。
なお、生成AIをカスタマーサポートで活用する方法について、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】Gemini 3.1 Flash-Liteが解決できること
Gemini 3.1 Flash-Liteは、高速処理と低コストを両立した生成AIモデルです。
大量のリクエストを扱う業務やリアルタイム処理が求められるシステムでは、従来のLLMではコストやレスポンス速度が課題になるケースもありました。こうした課題を改善する手段としても活かすことができるでしょう。
大量のAIリクエストを低コストで処理できる
生成AIをサービスに組み込む場合、最も大きな課題の一つがAPIコストの増大。ユーザー数が増えるほどトークン消費量も増えるため、運用コストが急激に上がるケースがあります。
Gemini 3.1 Flash-Liteは、入力100万トークンあたり0.25ドルという価格です。
こうした低価格設計により、大量のリクエストを処理するAIサービスでも比較的コストを抑えやすくなりました。
リアルタイムAIアプリでも高速応答を実現できる
リアルタイムAIアプリでは、応答速度がUXに直結。しかし、モデルサイズが大きくなるほど推論時間が長くなり、ユーザー体験に影響する場合もあります。
Gemini 3.1 Flash-Liteは低レイテンシを重視した設計で、従来モデルと比べて応答速度が改善されています。
最初の回答トークンが生成されるまでの時間は約2.5倍高速化し、出力速度も45%向上しました。こうした改善により、チャットやリアルタイム分析などの用途でも使いやすくなっています。
タスクに応じて推論量を柔軟に調整できる
生成AIを使ったアプリケーションでは、すべての処理に同じ推論コストが必要なわけではありません。簡単な分類処理と複雑な推論タスクでは、求められる計算量が大きく異なります。
Gemini 3.1 Flash-Liteには「thinking levels」という仕組みがあり、モデルの推論量を段階的に調整ができます。
思考レベルを下げれば高速処理を優先でき、上げればより深い推論が可能。
複数のデータ形式を一つのAIで処理できる
AIシステムでは、テキストだけでなく画像や動画、音声などのデータを扱う場面が増えています。従来は用途ごとに異なるモデルを用意する必要があり、システム構成が複雑になるケースもありました。
Gemini 3.1 Flash-Liteはマルチモーダル入力に対応しており、テキスト・コード・画像・音声・動画・PDFなどを入力として扱えます。複数のデータ形式を同じモデルで処理できるため、AIアプリの構成をシンプルにできます。
Gemini 3.1 Flash-Liteの実装方法
では実際にGemini 3.1 Flash-Liteを実装していきます。今回はAPI経由でgoogle colaboratoryで実装をしていきます。
まずは必要ライブラリのインストール。
!pip -q install -U google-genai続いてAPIキーの設定から実装までです。
APIキーの設定はこちら
import os
os.environ["GEMINI_API_KEY"] = ""サンプルコードはこちら
from google import genai
client = genai.Client()
resp = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="Gemini 3.1 Flash-Liteを1文で説明して"
)
print(resp.text)結果はこちら
Gemini 3.1 Flash-Liteは、圧倒的な低遅延と低コストを両立させ、単純なタスクや高速なレスポンスが求められる用途に最適化された軽量かつ高性能なAIモデルです。
使用自体は非常に簡単ですね。出力自体も真っ当な出力が返ってきていると思います。
Gemini 3.1 Flash-Liteの活用事例
ここでは実際にGemini 3.1 Flash-Liteを活用している事例をリサーチして紹介していきます。
レスポンス速度と精度の検証
こちらの投稿では実際のレスポンス速度と精度を検証されています。
実際のレスポンスや精度についての結果記載はありませんでしたが、レスポンスは早いですね。
AI秘書のモデル
下記の投稿では、AI秘書エージェントのモデルをGemini 3.1 Flash-Liteにされていました。速度は高速になり、Pass Rateも改善されているようです。
Gemini 3.1 Flash-Liteは普段使い・高頻度使用では、かなり良いモデルなのではないでしょうか。


Gemini 3.1 Flash-Liteを実際に使ってみた
ではもう少しGemini 3.1 Flash-Liteを使ってみたいと思います。
Gemini 3.1 Flash-Liteで指定できるパラメータを一部抜粋したのが下記です。
| パラメータ | 指定方法(Python例) |
|---|---|
| thinkingBudget | “thinkingConfig”: {“thinkingBudget”: 0} |
| maxOutputTokens | “maxOutputTokens”: 512 |
| cachedContent | “cachedContent”: “cache_id” |
| temperature | “temperature”: 0.3 |
実際に上記を指定したサンプルコードがこちら。
サンプルコードはこちら
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="AIの未来を説明して",
config={
"temperature": 0.3,
"maxOutputTokens": 2048,
"thinkingConfig": {"thinkingBudget": 0},
}
)
print(response.text)結果はこちら
AIの未来は、私たちの生活、仕事、そして社会のあり方を根本から変える可能性を秘めています。その未来を理解するために、いくつかの重要な視点に分けて解説します。
### 1. 技術的な進化:AIは「道具」から「パートナー」へ
現在、AIは「指示されたことをこなす道具(チャットボットや画像生成など)」ですが、今後は以下のように進化すると予測されています。
* **自律型エージェント(AI Agents):** 単に質問に答えるだけでなく、目標を与えれば「旅行の計画を立てて、予約まで完了させる」「プロジェクトの進捗を管理し、必要な資料を作成する」といった、自律的な実行能力を持つようになります。
* **マルチモーダル化:** テキスト、画像、音声、動画、センサーデータなど、あらゆる情報を同時に理解・処理できるようになります。これにより、AIは人間と同じように世界を認識できるようになります。
* **AGI(汎用人工知能)への接近:** 特定のタスクだけでなく、人間のようにあらゆる知的作業をこなせる「AGI」の実現が、数年〜数十年以内には起こると多くの専門家が予測しています。
### 2. 社会への影響:仕事と生活の変容
AIの普及により、私たちの日常は大きく変わります。
* **仕事の再定義:** 単純作業や定型的な事務作業はAIが担うようになります。一方で、人間は「AIを使いこなす力」「創造性」「共感力」「複雑な意思決定」といった、人間にしかできない価値に集中するようになります。
* **パーソナライズの極致:** 教育、医療、エンターテインメントなど、あらゆるサービスが「あなた専用」に最適化されます。例えば、AI家庭教師が個人の理解度に合わせて教え方を変えたり、AI医師が個人の遺伝子情報に基づいて最適な治療法を提案したりする未来です。
* **科学技術の加速:** 新薬の開発、気候変動の解決策、新しい素材の発見など、人間だけでは何十年もかかる研究が、AIによって数ヶ月、数週間に短縮される可能性があります。
### 3. 課題とリスク:私たちが直面する壁
明るい未来だけでなく、乗り越えるべき大きな課題もあります。
* **雇用と経済格差:** AIが仕事を奪うことによる失業問題や、AIを所有する企業とそうでない人との間の経済格差が懸念されています。
* **倫理と安全性:** AIが偏った判断を下す(バイアス)、フェイクニュースやディープフェイクによる情報の混乱、AIの暴走といったリスクに対する規制や倫理ガイドラインの整備が急務です。
* **人間性の喪失:** AIに頼りすぎることで、人間自身の思考力やコミュニケーション能力が低下するのではないかという懸念もあります。
### 4. 結論:未来は「共存」の形を探る旅
AIの未来は、**「AIが人間を支配する」のか「人間がAIを道具として使いこなす」のかという二元論ではありません。**
最も可能性が高いのは、**「AIと人間が協働する社会」**です。AIが人間の知能を拡張し、これまで解決できなかった課題を解決するパートナーになる未来です。
**私たちが今すべきこと:**
AIを「怖いもの」として遠ざけるのではなく、**「AIをどう使いこなせば、より良い未来を作れるか」**を考え、学び続ける姿勢が重要です。AIの進化は止められませんが、その進化の方向性を決めるのは、私たち人間一人ひとりの選択と社会のルール作りにかかっています。
あなたは、AIとどのような未来を歩みたいと思いますか?続いてキャッシュを作って、キャッシュを活用してみます。
キャッシュ作成のサンプルコードはこちら
from google import genai
from google.genai import types
client = genai.Client()
fixed_context = """
あなたはプロの編集者です。
回答は日本語で、結論→理由→補足の順で簡潔に。
"""
# 1024 tokens未満だと弾かれるので、まずは動作確認用に長文を追加
padding = "これはキャッシュサイズを満たすためのテキストです。" * 2000
cache_text = fixed_context + "\n" + padding
cache = client.caches.create(
model="gemini-3.1-flash-lite-preview",
config=types.CreateCachedContentConfig(
contents=[cache_text],
ttl="3600s"
)
)
cache_id = cache.name
print("cache_id:", cache_id)
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="AIの未来を説明して",
config={
"temperature": 0.3,
"maxOutputTokens": 512,
"thinkingConfig": {"thinkingBudget": 0},
"cachedContent": cache_id
}
)
print(response.text)キャッシュ利用のサンプルコードはこちら
cache_id = ""
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="AIの未来をもう少し具体的に。3点で",
config={
"temperature": 0.3,
"maxOutputTokens": 2048,
"thinkingConfig": {"thinkingBudget": 0},
"cachedContent": cache_id
}
)
print(response.text)結果はこちら
AIの未来は**「人間の創造性を拡張するパートナー」**へと進化します。
**理由**
AIは単なる自動化ツールから、複雑な文脈を理解し、個人の思考やスキルを補完する「共創型」の存在へと移行するからです。AIが定型業務を担うことで、人間はより高度な意思決定や創造的な活動に集中できるようになります。
**補足**
具体的には、以下の3点で私たちの生活や仕事が大きく変わります。
1. **パーソナライズの極致**:個人の学習履歴や好みを完全に把握したAIが、教育、医療、エンターテインメントにおいて、一人ひとりに最適化された体験をリアルタイムで提供します。
2. **「専門職」の民主化**:プログラミングやデザイン、高度な分析といった専門スキルがなくても、AIを介することで誰でも高いレベルの成果物を作成可能になり、個人の生産性が飛躍的に向上します。
3. **意思決定の高度化**:膨大なデータから未来の予測やリスクを瞬時に提示することで、ビジネスや政策決定における不確実性が減り、より合理的で迅速な判断が可能になります。なお、Opus4.6に匹敵する性能をコスト効率よく実現したモデルであるClaude Sonnet 4.6について詳しく知りたい方は、下記の記事を合わせてご確認ください。

よくある質問
まとめ
本記事では、Googleが提供する生成AIモデル「Gemini 3.1 Flash-Lite」について解説しました。Gemini 3シリーズの中でも特に高速処理とコスト効率を重視して設計されたモデルであり、大規模AIアプリケーションに適した特徴を持っています。
Gemini 3.1 Flash-Liteはコストと応答速度のバランスを重視したモデルであり、翻訳処理やコンテンツモデレーション、AIチャットボットなどの用途で活用が進むでしょう。
また、thinking levelsのように推論量を制御できる仕組みが導入されたことで、用途に応じて速度と推論精度を柔軟に調整できる点も大きな特徴。
一方で、現在はプレビュー段階のモデルであり、仕様変更やサポート範囲の制限がある可能性もあります。導入を検討する場合は、まずPoC環境で検証を行い、実際のワークロードでの性能やコストを確認することが重要です。
AI機能を自社サービスに組み込むなら、まずGemini APIやVertex AIの環境で試してみてください。高速かつ低コストなAIモデルとして、プロダクト開発の有力な選択肢です。

最後に
いかがだったでしょうか?
Gemini 3.1 Flash-Liteは、高頻度なAPI利用やリアルタイム用途で、コストと速度の両立を狙えるモデルです。一方で、実運用では「要件に合うモデル選定」「プロンプト設計」「キャッシュや推論設定を含む最適化」「既存システム連携」まで含めた設計が成果を左右します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

