
Stable Diffusion Web UIの使い方を徹底解説!ダウンロード・インストール・画像生成も紹介

- Stable Diffusion Web UIはStable Diffusionをブラウザから操作できるローカル画像生成インターフェース
- オープンソースでソフト自体は無料利用可能
- ローカル実行のためStable Diffusion Web UIは生成処理をオフラインで実行可能
みなさんは、Stable DiffusionをWebブラウザ上で手軽に利用できる「Stable Diffusion Web UI」をご存知でしょうか?
画像生成の自由度が高いのはもちろん、無料で利用できるのがなによりの利点です。
今回は、Stable Diffusion Web UIの概要や導入方法、使い方などを詳しく解説していきます。最後まで目を通すと、自身のPCで手軽にAI画像生成ができるようになるので、クリエイティブな仕事が捗ること間違いありません。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Stable Diffusion Web UIとは
Stable Diffusion Web UIとは、Webブラウザを通して、無料でStable Diffusionを利用できるアプリです。その名の通り、Web UIによる手軽な操作性が魅力で、プログラミングなどの複雑な工程は発生しません。
そのため、初心者でも比較的簡単に画像生成を始められます。ローカル環境にインストールして使用するため、インターネット接続が不要であり、プライバシーを確保しながら高品質な画像を作成できる点も特徴です。
また、拡張機能を追加することで、より高度なカスタマイズや表現の幅を広げられます。
AUTOMATIC1111版とForge版の違い
| 項目 | AUTOMATIC1111 | Forge | reForge |
|---|---|---|---|
| 開発状況 | 事実上停滞(2024年末〜) | 更新停止(2025年6月〜) | 継続中(2026年1月確認済み) |
| 動作の安定性 | 高い・実績豊富 | やや不安定な場合あり | 安定・A1111より高速 |
| 拡張機能の対応 | 最多 | 一部未対応あり | A1111との互換性高い |
| VRAM使用量 | 多め | 少なめ | 最も少なめ |
| 動作速度 | 標準 | A1111より30〜75%高速 | Forgeより高速な場合あり |
Stable Diffusion Web UIには、AUTOMATIC1111版とForge版の2種類が存在します。AUTOMATIC1111版はForge版よりも前からリリースされているのが特徴で、ドキュメントの豊富さと安定した動作が魅力です。
長年の開発により、数多くの拡張機能やカスタマイズオプションが提供されており、多様な用途に対応できます。
Forge版はA1111をベースに、VRAMの最適化と生成速度向上を目的として開発。同一プロンプト・同一条件での出力品質はA1111とほぼ同等で、VRAM消費を抑えながら生成速度が30〜75%向上します。
txt2imgとimg2imgの違い
Stable Diffusion Web UIでは、画像生成方法として「txt2img」と「img2img」の2つの機能が用意されています。
「txt2img」は、テキスト(プロンプト)のみをもとに画像を生成する機能です。例えば、「湖のほとりに立つ白い教会」のような文章を入力するだけで、AIがそのイメージに沿った画像を一から描き出します。構図や色合いなども自動的に決定されるため、まったく新しい発想の画像を生み出したいときに最適です。
一方、「img2img」は、もととなる画像にテキストを組み合わせて、新たな画像を生成する機能です。入力画像の構図や雰囲気を保ちつつ、スタイルや細部を変更できるため、ラフスケッチを清書したり、写真をイラスト風に変換したりといった用途に向いています。また、もとの画像の影響度合いは設定で調整可能で、微妙な変化から大胆な変化まで柔軟に対応できます。
両者を使い分けることで、アイデア出しから仕上げ作業まで、画像制作の幅が大きく広がります。


Stable Diffusion Web UIを利用するメリット
Stable Diffusion Web UIを利用するメリットは、以下の3つです。
- 無料で利用できる
- カスタマイズが可能
- オフラインでも利用可能
特に、高品質な画像を無料で生成できるのが大きな魅力です。
以下で、それぞれのメリットを紹介していくので、ぜひ参考にしてみてください。
無料で利用できる
Stable Diffusion Web UIは、オープンソースで公開されているので、誰でも無料で利用できます。どこかのサイトに会員登録をする必要もありません。
ほかの画像生成を利用する際は、月額もしくは従量課金で費用を請求されることが多いので、これは大きなメリットですね!
カスタマイズが可能
Stable Diffusion Web UIでは、拡張機能を利用して生成画像をカスタマイズできます。LoraやControlNetといった、コミュニティによって開発されたさまざまな拡張機能を利用可能です。
例えば、Loraを使用すると、アニメ風の画像やリアルな人間の画像など、特定のタスクに特化させられます。ニーズに沿った質の高い画像生成ができるようになるので、ぜひ試してみてください。
オフラインでも利用可能
Stable Diffusion Web UIは、オフラインでも利用できます。インターネット接続なしで作業がローカル上で完結するため、セキュリティ面での懸念を払拭できるのがメリットです。
ただし、PCのCPUやGPUのスペックによっては快適に動作しない場合があるため、スペック要件を事前に確認しておくと安心です。
Stable Diffusion Web UIのダウンロード手順
ここからは、Stable Diffusion Web UIの導入方法をご紹介します。WindowsやMacなどのOS別に、AUTOMATIC1111版のダウンロード手順を解説するので参考にしてみてください。
Windowsのダウンロード手順
必要スペック
| 項目 | 推奨スペック |
|---|---|
| CPU | 6コア以上(Core i5-11400以上/Ryzen 5 5600以上 推奨) |
| メモリ | 最低16GB、拡張機能を使用するなら32GB以上推奨 |
| GPU(VRAM) | 最低6〜8GB(RTX 2060以上)、推奨はRTX 3060(12GB)以上 |
| ストレージ(SSD) | 最低250GB(複数モデル使用予定なら512GB以上推奨) |
| OS | Windows 10/11(64bit) |
WindowでStable Diffusion Web UIをダウンロードする際は、おもに以下3つのステップに沿って実施します。
- Pythonのダウンロード
- gitのダウンロード
- Stable Diffusion Web UIのダウンロード
Pythonのダウンロード
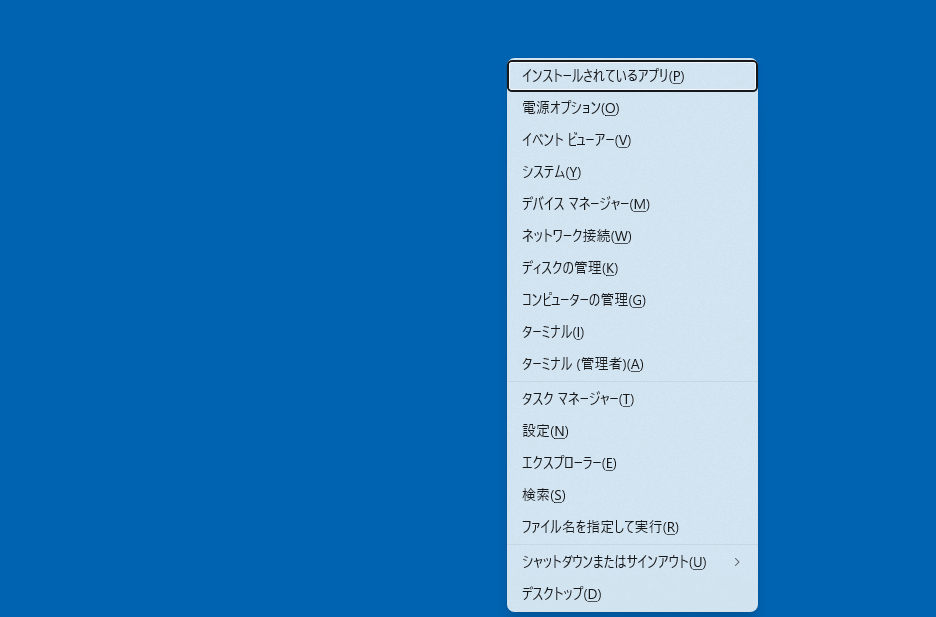
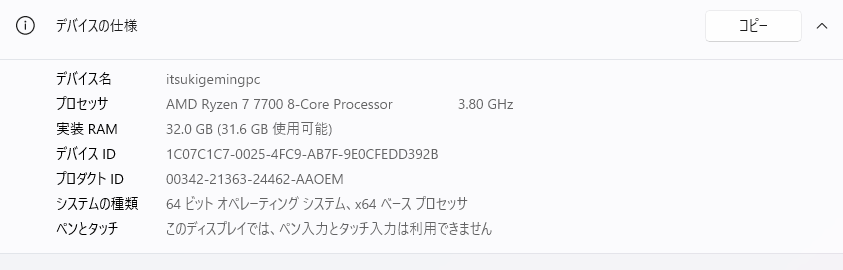
まずは、Pythonとgitをダウンロードするために、自身が使っているWindowsのビット数を確認します。
デスクトップでWindowsキー+Xキーを押して、上から4つ目にある「システム」をクリックしてください。
デバイス仕様の「システムの種類」を確認すれば、ビット数がわかります。
次はPython公式サイトにアクセスして、Python 3.10.6のインストーラーをダウンロードします。
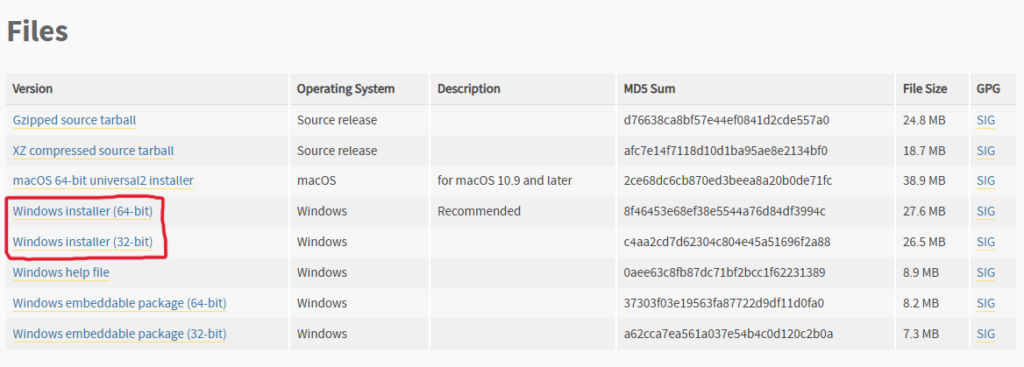
上記赤枠部分のどちらかビット数が自身のPCと一致するものをダウンロードしてください。
ダウンロードしたインストーラーを開きます。

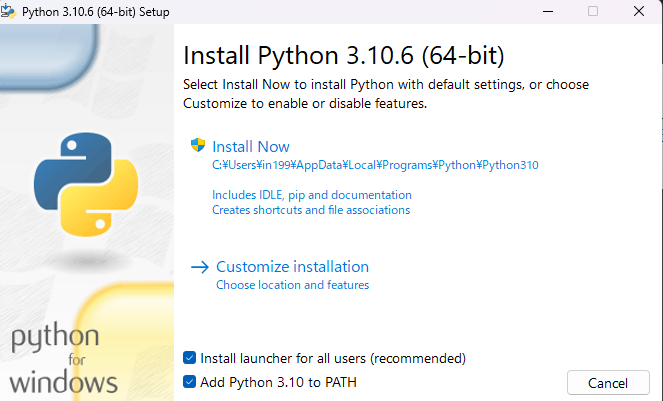
「Add Python 3.10 to PATH」にチェックを入れて、「Install Now」をクリックしてください。
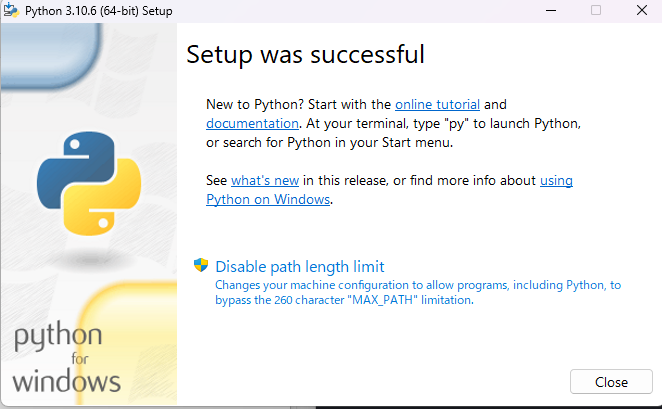
以下の画面が表示されたら、Pythonのダウンロードは完了です。
gitのダウンロード
次は、gitの公式サイトにアクセスして、gitのインストーラーをダウンロードします。
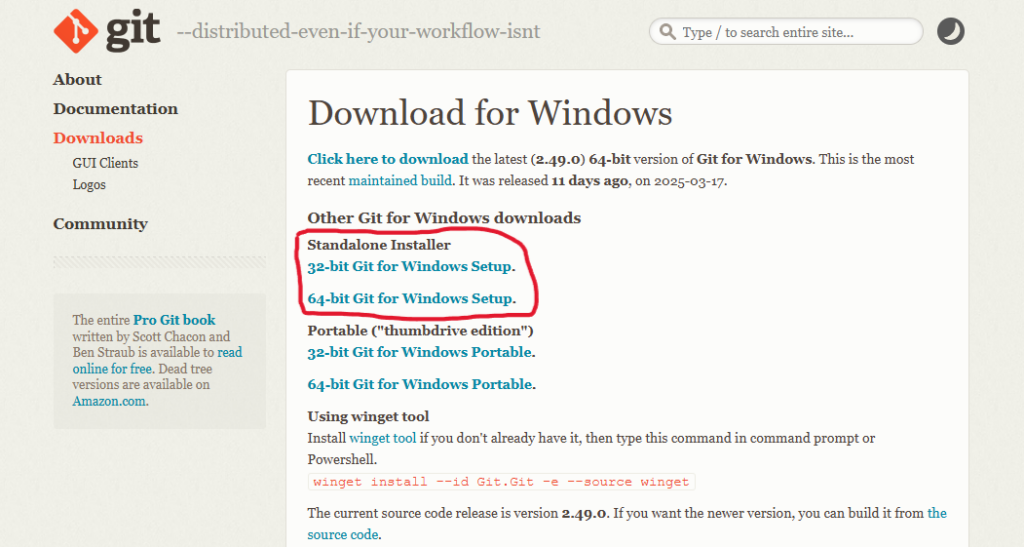
Python同様、自身のPCのビット数と一致するものをダウンロードしてください。
ダウンロード後は、gitのインストーラーを開きます。

gitのインストーラーを立ち上げると、いくつかの項目が立て続けに表示されますが、全て何もいじらずに「Next」をクリックしてください。
以下の画面が表示されれば、gitのダウンロードは完了です。
Stable Diffusion Web UIのダウンロード
次は、Stable Diffusion WebUI関連のファイルを格納する任意のフォルダを開きます。
右クリックして、「Open Git Bash here」をクリックしてターミナルを開きましょう。
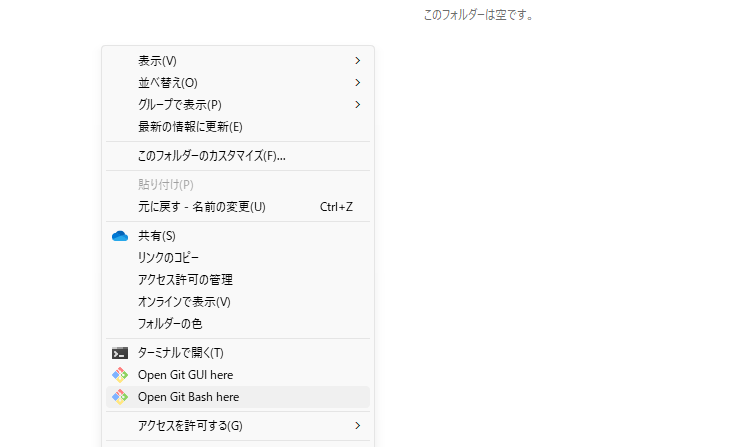
右クリックしても「Open Git Bash here」が見つからない場合は、「その他のオプションを確認」を押すと出てきます。
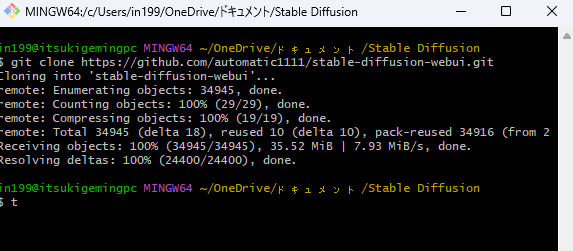
ターミナルを開いたら、以下のコマンドを入力します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitコマンドを入力すると、Stable Diffusion Web UIがローカル環境にダウンロードされ、以下画面のファイルが作成されます。
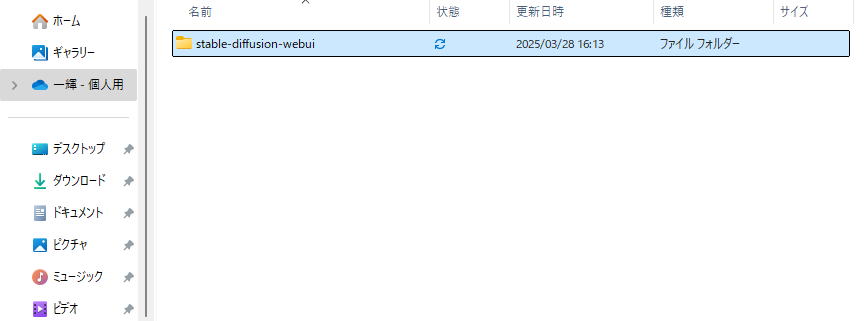
上記ファイルを開き、「webui-user.bat」もしくは「webui-user」と表示されているWindowsパッチファイルを開きます。
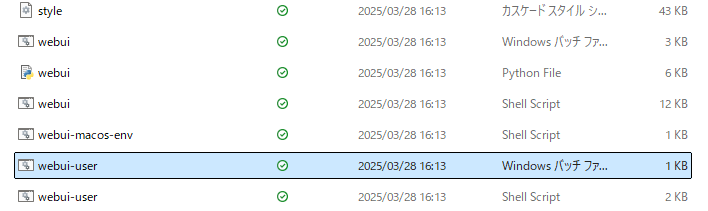
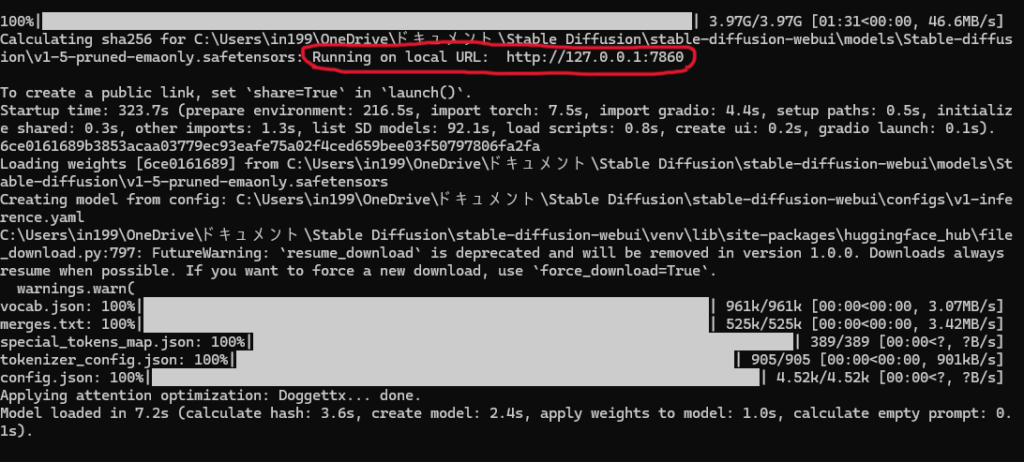
ファイルを開いてしばらくすると、ターミナルに「Running on local URL: http://127.0.0.1:7860」が表示されて、自動的にWebブラウザ上でStable Diffusion Web UIが立ち上がります。
Macのダウンロード手順
必要スペック
| 項目 | 推奨スペック |
|---|---|
| チップ | Apple Silicon(M1/M1 Pro/M1 Max/M2/M2 Pro/M2 Max)搭載Mac |
| メモリ | 最低16GB、生成や拡張機能利用なら32GB以上推奨 |
| ストレージ | 最低128 GB(Web UI+モデル1~2個)、余裕があるなら250~512GB以上推奨 |
| OS | macOS Monterey以降(Ventura/Sonomaなど) |
| 備考 | より高速な生成や安定性を求めるなら、InvokeAIやDraw ThingsなどCore ML対応アプリも検討すると良い |
Homebrewをインストール
まずは、アプリ一覧から「ターミナル」を開いて、「Homebrew」をインストールします。
「Homebrew」をインストールする際は、以下のコードをターミナルにコピペしてください。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"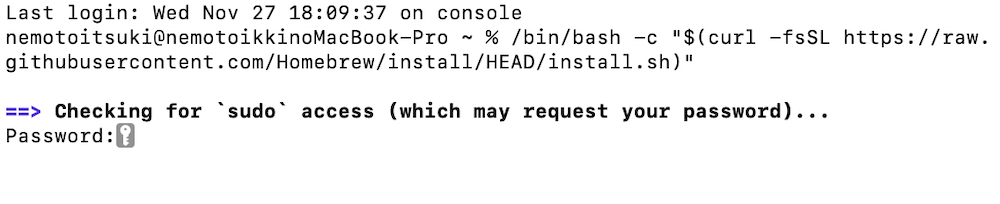
パスワードの入力を求められるので、いつもMacを開くときに使用しているパスワードを入力します。
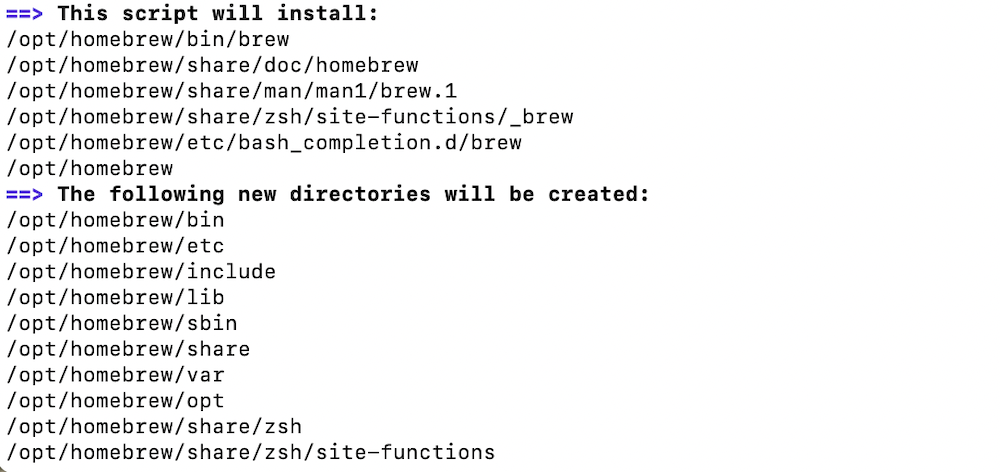
パスワードの入力後はenterを押して、Homebrewのインストールが終わるのを待ってください。
次はターミナルに以下のコマンドを入れます。
export PATH="$PATH:/opt/homebrew/bin/"以下のコマンドを入力して、インストールが完了していることやPATHが通っているか確認しましょう。
brew --version以下の画像のような画面になればOKです。

筆者も直面しましたが、Homebrewのインストール中に「zsh: command not found: brew」と表示されてエラーになることがあります。
その際は、ファインダーから「ターミナル」を検索して、右クリックで「情報を見る」を選択します。その後、「Rosettaを使用して開く」にチェックを入れて、PCを再起動してからもう一度やり直してみてください。

Stable Diffusion Web UIのダウンロード
今度はいよいよ、Stable Diffusion Web UIをダウンロードします。
以下のコマンドを入力して、必要なライブラリをインストールしてください。今回は、AUTOMATIC1111版をインストールしています。
brew install cmake protobuf rust python@3.10 git wgetインストール後の画面がこちらです。
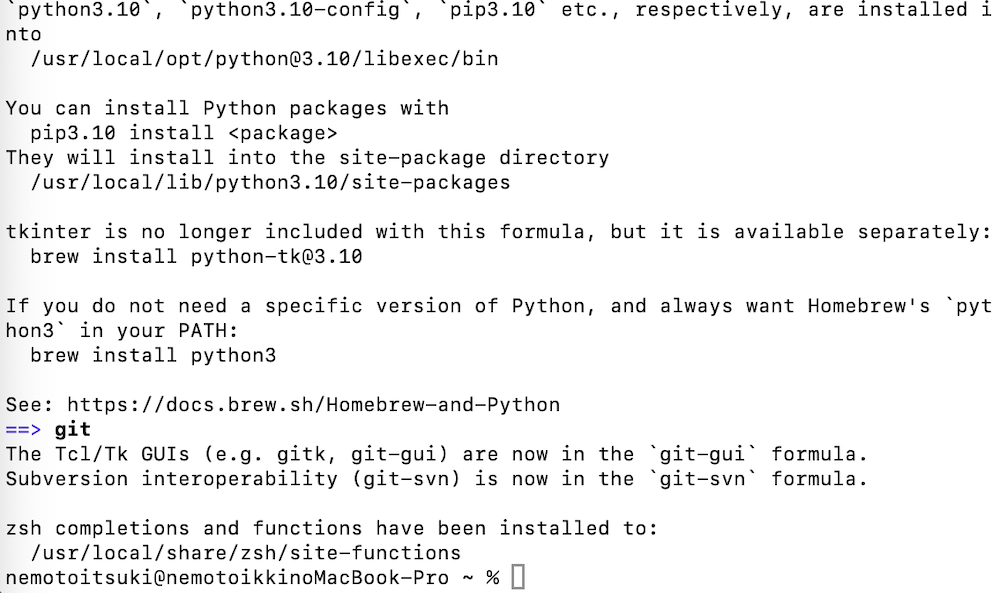
続いて、以下のコマンドを入力して、Stable Diffusion Web UIのリポジトリをローカルPCにcloneしてください。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui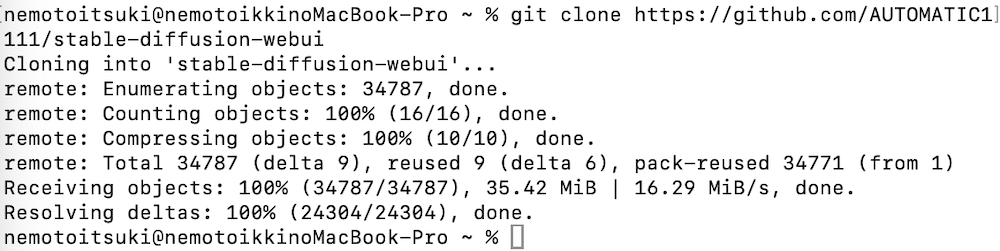
今度は、以下のコマンドを実行して、いよいよStable Diffusion Web UIを起動します。
bash stable-diffusion-webui/webui.sh正常に動作すると、以下画面のように「Running on local URL: http://127.0.0.1:7860」が表示されます。
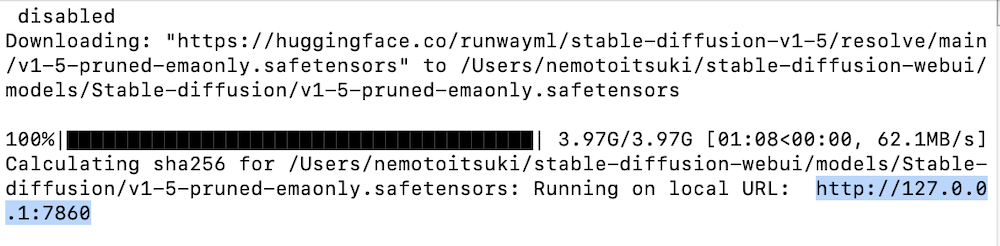
この時点で、Stable Diffusion Web UIが自動でブラウザ上で立ち上がるので、実際に利用してみてください。
Google Colabのダウンロード手順
google colaboratoryで使用する場合には、下記のコードを一つのセルで実行すればOKです。
%cd /content
!rm -rf /content/stable-diffusion-webui
!rm -rf /content/mamba
!rm -rf /content/bin
!wget -qO- https://micro.mamba.pm/api/micromamba/linux-64/latest | tar -xvj bin/micromamba
!/content/bin/micromamba create -y -p /content/mamba python=3.10
!/content/bin/micromamba run -p /content/mamba python -V
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
%cd /content/stable-diffusion-webui
!git switch dev || git checkout dev
!git pull
!sed -i 's#https://github.com/Stability-AI/stablediffusion.git#https://github.com/w-e-w/stablediffusion.git#g' modules/launch_utils.py
!rm -rf repositories/stable-diffusion-stability-ai
!rm -rf venv
import os
os.environ["MPLBACKEND"] = "Agg"
os.environ["STABLE_DIFFUSION_REPO"] = "https://github.com/w-e-w/stablediffusion.git"
%cd /content/stable-diffusion-webui
!/content/bin/micromamba run -p /content/mamba python launch.py --share --enable-insecure-extension-access --skip-python-version-checkやや煩雑ですが、Stable Diffusion Web UIがPython 3.10を要求するのに対して、google colaboratoryのPythonが3.12になっていることから、煩雑さが増しています。
上記コマンドを実行後、URLが表示されるのでそのURLにアクセスすればOKです。
Stable Diffusion Web UIを起動できない場合の対応策
Stable Diffusion Web UIの起動を試みた際に、何らかの影響でエラーになることもあります。
おもな理由は、PythonのバージョンがStable Diffusion Web UIが推奨している「python3.10.6」になっていないことが挙げられます。
この場合は、以下のコマンドを入力してください。
brew update
brew install pyenv続けて、以下2つのコマンドを1つずつ入力していきます。
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc
echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc
echo 'eval "$(pyenv init --path)"' >> ~/.zshrcsource ~/.zshrcここまでで、Pythonをインストールする準備が一通り整ったので、次は以下のコマンドを実行してください。
pyenv install 3.10.6あとは、上記のPythonバージョンをシステムで使用できるように、以下のコマンドを実行します。
pyenv global 3.10.6以下のコードを実行すれば、現在反映されているPythonのバージョンを確認できます。
python --versionこの時点で、「python3.10.6」が指定されていれば成功なので、再度以下のコードを実行してStable Diffusion Web UIを起動してみてください。
bash stable-diffusion-webui/webui.shこれでもまだエラーが出る場合は、ほかにも要因があるので、エラーメッセージをそのままChatGPTに入力して、原因や解決方法を聞いてみてください。

実際、筆者も何度もエラーが出たのですが、ChatGPTに聞いてその通りにコマンドを実行していったら、Stable Diffusion Web UIを起動できました。
筆者の場合は、指定されたPyTorchバージョン(torch=2.3.1)が現在の環境で利用できなかったので、対応するPyTorchを手動でインストールしています。
おそらく、いろいろなサイトで解決策を探すよりも楽に解決できるはずです。
今回はAUTOMATIC1111版のダウンロード手順を紹介しましたが、Forge版のダウンロード手順書気になる方は以下の記事をご覧ください。

Stable Diffusion Web UIインストール後にまずやる初期設定
インストールが終わっても、そのまま画像生成を始めると「色がくすむ」「生成のたびに設定が崩れる」といったつまずきに直面しやすいです。快適に使い始めるために、最初に確認しておきたい設定を3つ解説します。
保存先とVAEの確認
まず確認したいのが、生成画像の保存先。
デフォルトではWebUIのインストールフォルダ内「outputs」に自動保存されますが、モデルを複数使い始めると管理が煩雑になりがちです。
次に忘れずに設定したいのがVAEです。
VAEは生成画像の色味・鮮明さに直接影響するツールで、設定していない状態では色がくすんだり、全体が暗くぼやけた印象になることがあります。
サンプラー・Steps・CFG Scaleの目安
画像生成の品質を左右するパラメーターのうち、最初に押さえておきたいのがこの3つです。
| パラメーター | 推奨値 | 備考 |
|---|---|---|
| サンプラー | DPM++ 2M Karras | 汎用設定 |
| Steps | 20〜30 | 速度と品質のバランス帯 |
| CFG Scale | 7〜10 | 標準範囲・多くのモデルのデフォルト値 |
| CFG Scale(強め) | 11〜20 | プロンプト反映強化・彩度/コントラスト上昇 |
サンプラーは、AIがノイズから画像を描き起こす際のアルゴリズムです。選択肢は多いですが、初心者にはDPM++ 2M Karrasが安定・高品質で汎用的に使えるためおすすめです。
Stepsは、AIが計算を繰り返す回数です。一般的に20〜30が速度と品質のバランスが取れた推奨値で、最初はこの範囲から始めると安定します。
CFG Scaleは、プロンプトへの忠実度を制御する値です。7〜10がバランスの取れた標準範囲で、多くのモデルのデフォルト値もこの付近に設定されています。11〜20に上げるとプロンプトの内容を強く反映しますが、彩度やコントラストが強調されやすくなります。
低スペックPC向けの軽量化設定(xformers・medvram)
VRAM不足でエラーが出る場合、ソフト側の設定で状況を改善できることがあります。
設定はWebUIの起動ファイルwebui-user.batをテキストエディタで開き、set COMMANDLINE_ARGS=の行に引数を追記するだけで反映されます。
最初に試したいのが–xformersです。xformersライブラリを利用することでVRAM消費量を抑えながら生成速度も向上するため、多くの環境で効果が出ます。
それでも不足する場合は–medvramを追加します。CPU側のRAMをVRAMの補助として使うことで、VRAM 6〜8GB環境でも動作しやすくなります。
Stable Diffusion Web UIの使い方
ここからは、Stable Diffusion Web UIの使い方を解説していきます。
基本操作から応用まで紹介しているので、ぜひ参考にしてみてください。
Web UIの基本操作(テキストから画像を生成)
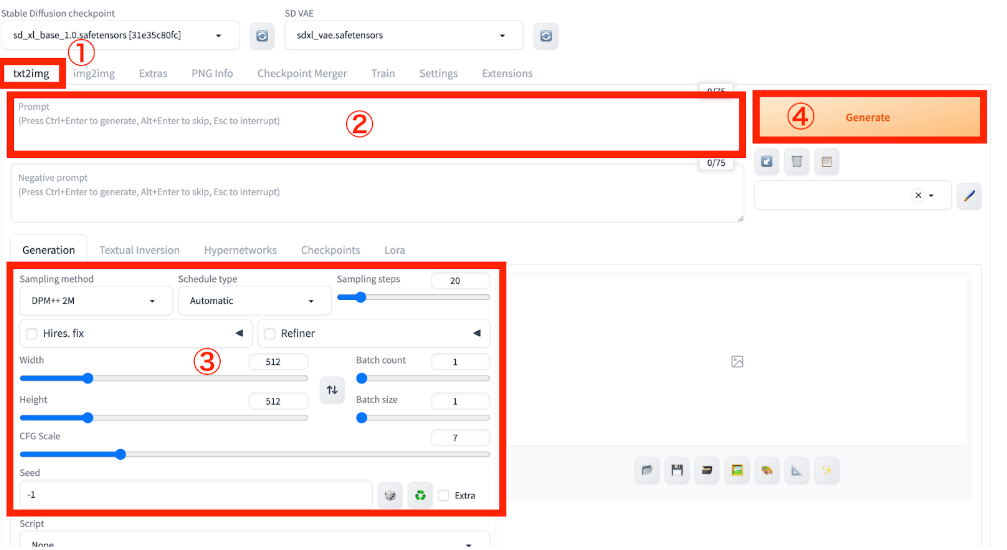
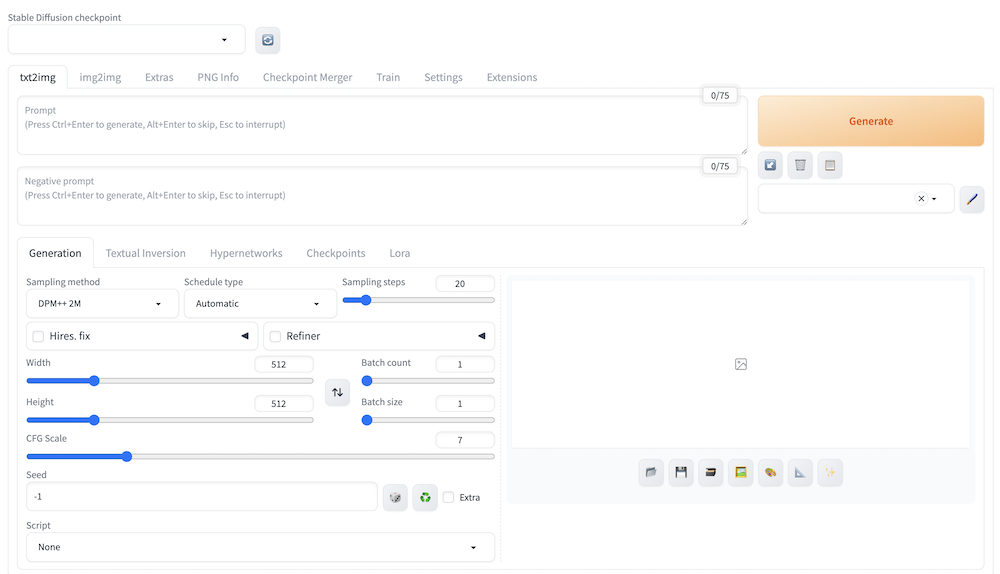
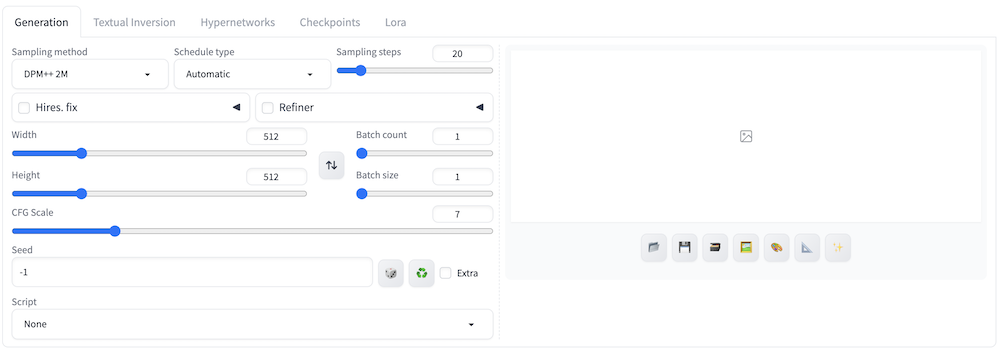
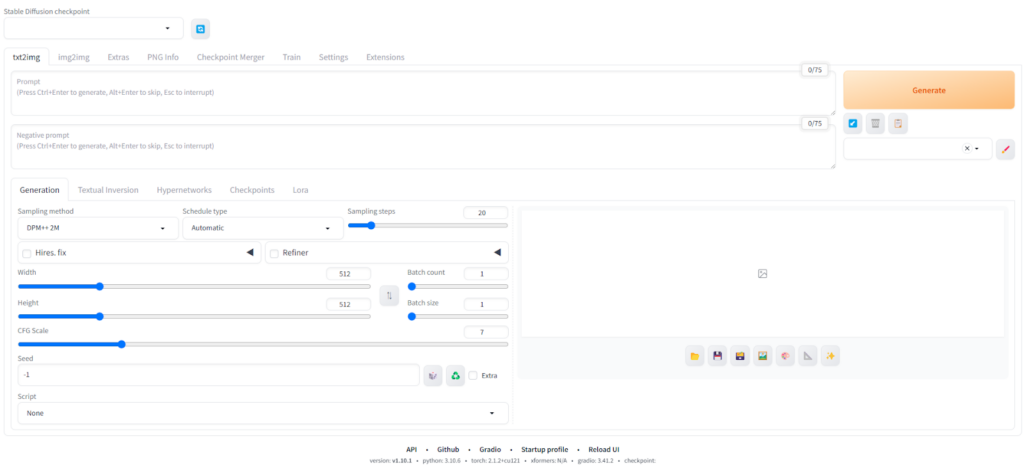
まずは、Stable Diffusion Web UIの見方や基本となるtxt2img(テキストから画像を生成)のやり方を解説します。
テキストから画像を生成する際は、上記画像の①に注目してtxt2imgを選択します。その後は②の部分にプロンプトを入力して、必要ならその下にネガティブプロンプト(画像に反映させたくない要素)を入力して指定しましょう。
③では各種パラメータの調整ができます。
| パラメータ | 意味 |
|---|---|
| Sampling method | サンプリング手法。手法によって生成速度や画像の品質が変わる。 |
| Sampling steps | サンプリングステップ数。値が大きいほど画像の品質が良くなるが、生成速度が落ちる。 |
| Width、Height | 画像のサイズ。大きいほど画像の生成速度が遅くなる。 |
| Batch Size | 生成する画像枚数。 |
| Batch Count | 一度に生成する画像の何枚。 |
| CFG Scale | プロンプトの影響の強さ。値が大きいほどプロンプトに忠実になるが、画像の品質が落ちることがある。 |
パラメータの調整後は、④の「Generate」を押して画像を生成しましょう。
img2imgの使い方(画像から画像を生成)
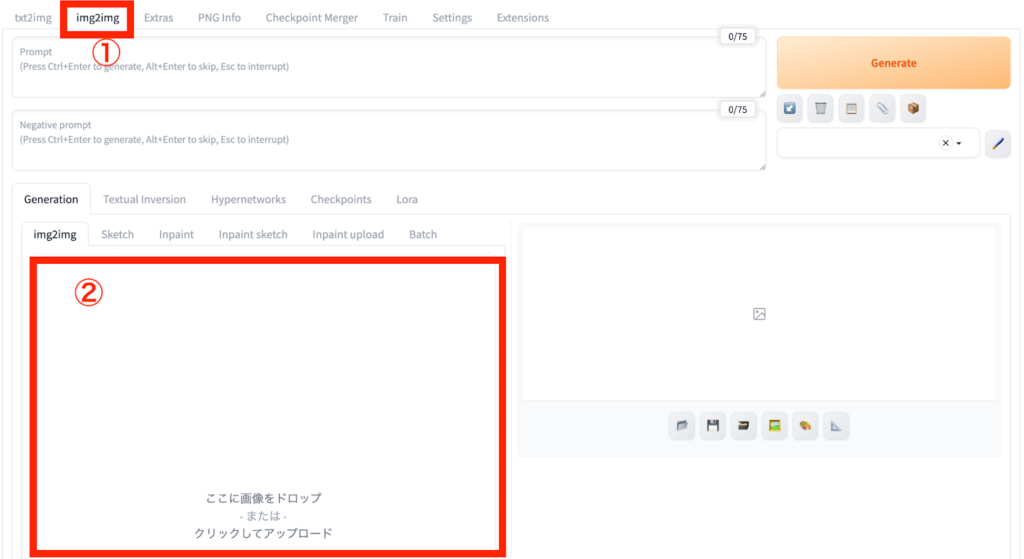
画像入力で画像を生成したい場合は、上部①のimg2imgを選択して、その下にプロンプトを入力します。
②で画像をアップロードして、その下にある各種パラメータを調整しましょう。最後に「Generate」ボタンを押せば画像生成が始まります。
inpaint・outpaintの使い方
inpaintとoutpaintはどちらもimg2imgタブ内から使えますが、役割がそれぞれ異なります。inpaintは画像の「内側の一部」を修正するもの、outpaintは「外側」に描き足して拡張するものです。
inpaintは、生成した画像の顔の崩れ・手の指の乱れ・服装の変更など、画像全体は気に入っているのに一部だけ直したいときに使います。
outpaintは、画像の外側に続きを描き足す機能です。縦横比を変えたい場面や、構図を広げて画角を拡張したい場面で力を発揮。
生成した画像の保存方法

生成した画像は、画像の右横にあるダウンロードボタンを押すことで保存できます。ボタンを押すだけでダウンロードが始まるので、複雑な工程はありません。
生成した画像を気に入った場合は、忘れずに保存しましょう。
Stable Diffusion Web UIを使って画像を生成してみた
ここからは、実際にStable Diffusion Web UIを使って画像を生成してみます。まずは、こちらのプロンプトを入力してみました。
東京のオフィス街を歩くスーツ姿の若い女性

プロンプトを入力したあとは、「Generate」を押して画像が生成されるのを待ちます。実際に生成された画像がこちらです。

顔の部分が潰れてしまっていて、あまりいい画像とはいえませんね。
次は、同じプロンプトを英語で入れてみました。

顔が若干ぼやけているように見えますが、さっきよりはプロンプトの再現度が上がっています。
ちなみに、Stable Diffusion Web UIにはさまざまなパラーメーターがあるので、これらをいじると生成される画像の結果も変化します。
おもなパラメーターをまとめました。
| 項目 | 内容 |
|---|---|
| Sampling method | ノイズの除去方法。変えると生成画像の結果にも影響が出る。 |
| Width・Height | 画像サイズの調整 |
| Sampling steps | ノイズを除去する回数で、多いと高品質になるが生成時間が長くなる。20〜30程度がおすすめ。 |
| CFG Scale | プロンプト従う影響度を調整できる。7〜12程度がおすすめ。 |
| Hires.fix | 使用すると画像が高解像度・高品質になる。 |
| Batch count | 1度に何枚の画像を生成するか指定できる。 |
| Batch size | 一度に大量の画像を生成するための機能。例えば「2」に設定すると、Batch countの値×2倍の画像を生成できる。 |
上記のパラメーターのうち、「Hires. fix」にチェックを入れ、「CFG Scale」は10にしてみました。同じプロンプトで再度画像生成してみます。

実際に生成された画像が上記ですが、顔の部分以外は確かに質が向上しました。着ているスーツや背景の再現度が向上しているように感じます。
ただし、「Hires. fix」にチェックを入れた影響か、画像生成の時間もかなり長くなったので注意が必要です。
次は、アニメスタイルの画像生成をしてみます。
今回は以下のプロンプトを入れてみました。
Beautiful green-haired girl elf living in the forest, anime style.生成された画像がこちらです。

ゲームに出てきそうなレベルのクオリティになりましたね!
このようにプロンプトやパラメーターをいじるだけで、生成される画像の質が大きく変わってくるので、自身でいろいろ設定をいじりながら試してみてください。
おすすめの画像生成AIは下記で解説

よくあるトラブルと解決方法
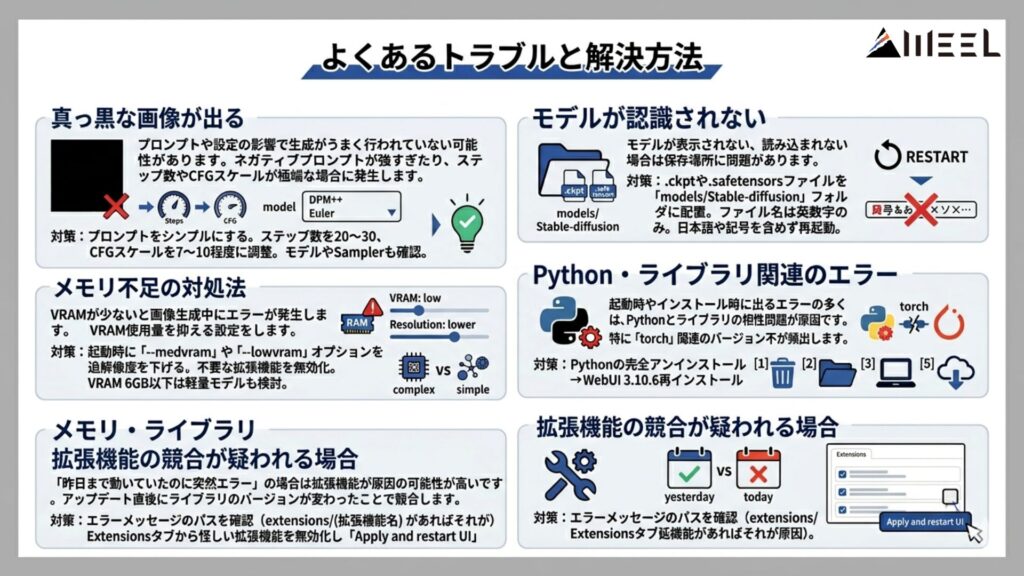
Stable Diffusion Web UIを使用する中で、初心者から上級者まで直面しやすいトラブルがあります。ここでは代表的な問題と、その対処法を紹介します。
真っ黒な画像が出る
画像が真っ黒になるトラブルは、プロンプトや設定の影響で生成がうまく行われていないケースが考えられます。ネガティブプロンプトが強すぎたり、ステップ数やCFGスケールの設定が極端だったりすると、正しく画像が描画されないことがあります。
まずはプロンプトをシンプルな内容に変えたり、ステップ数を20〜30、CFGスケールを7〜10程度に調整したりしましょう。また、使用しているモデルやSampler(例:DPM++系、Eulerなど)によっても結果が変わるため、設定を見直すことで改善が見込めます。
モデルが認識されない
モデルが表示されない、あるいは読み込まれない場合は、モデルファイルの保存場所に問題があるでしょう。基本的には 「models/Stable-diffusion 」フォルダ内に、「.ckpt」 または 「.safetensors」 ファイルを配置する必要があります。
また、ファイル名に全角文字や記号、日本語が含まれていると正常に読み込まれないことがあるため、英数字のみのファイル名に変更して再起動を試してみてください。
メモリ不足の対処法
VRAMが少ないPC環境では、画像生成中にエラーが発生することがあります。このような場合は、起動時に「–medvram」や「–lowvram」オプションを付けることで、VRAMの使用量を抑えることが可能です。
他にも、生成サイズ(解像度)を下げたり、不要な拡張機能(ControlNetなど)を無効にすることで、メモリ負荷を軽減できます。特にVRAMが6GB以下の場合は、モデル自体を軽量なものに切り替えるのも有効です。
Python・ライブラリ関連のエラー
起動時やインストール時に出るエラーの多くは、PythonのバージョンとWebUIが要求するライブラリの相性問題が原因であることが多いです。
最も頻出するのが「Could not find a version that satisfies the requirement torch」。
これはPythonのバージョンとPyTorchが嚙み合っていないサインで、対処はPythonの完全アンインストール→WebUIフォルダの削除→PCの再起動→Python 3.10.6の再インストール→WebUIの再クローンという順で行うのが確実です。
拡張機能の競合が疑われる場合
「昨日まで動いていたのに今日突然エラーが出る」という状況の多くは、拡張機能が原因であることが多いです。
特に、WebUI本体や拡張機能をアップデートした直後に崩れやすく、ライブラリのバージョンが内部で変わったことで既存の拡張機能との相性が壊れるパターンがよく起きます。
まず確認したいのがエラーメッセージの内容。extensions/(拡張機能名)のようなパスが含まれていれば、その拡張機能が直接の原因である可能性が高いです。そうでない場合も、Extensionsタブ → Installedから怪しい拡張機能のチェックを外して「Apply and restart UI」を押すことで、その拡張機能を一時的に無効化して再起動できます。
Stable Diffusion Web UIで使えるモデルの種類と選び方
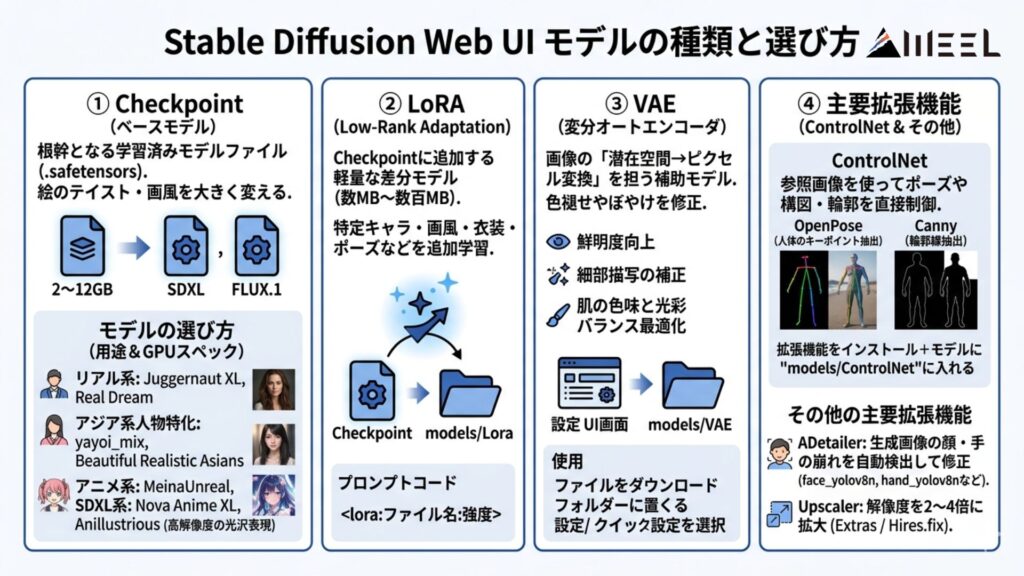
Stable Diffusion Web UIでは、画像スタイルを決める「Checkpoint」を中心に、LoRA・VAE・ControlNetなど複数のモデルを組み合わせて使うことで理想的な画像を生成できます。それぞれ役割が異なり、何をどう使うかを理解するだけで、出力クオリティは大きく変わります。
モデルの選び方
モデルは用途と自分のGPUスペックを軸に選ぶようにしましょう。
リアル系ならJuggernaut XLやReal Dreamが定番。アジア系人物に特化するならyayoi_mixやBeautiful Realistic Asiansも評価が高いです。
アニメ系の代表格はMeinaUnreal、SDXLベースではNova Anime XLやAnillustriousが高解像度の光沢表現に優れます。
Checkpoint(ベースモデル)とは
Checkpointは画像生成の根幹を担う学習済みモデルファイルで、拡張子は.safetensorsが主流。
ファイルサイズは2〜12GB程度と大きく、モデルを変えるだけで絵のテイスト・画風・得意な被写体が丸ごと変わります。現在主流のアーキテクチャはSD1.5・SDXL・FLUX.1の3系統で、LoRAやVAEはそのCheckpointの上に重ねて機能する仕組みです。
LoRAとは
LoRAとは「Low-Rank Adaptation」の略で、Checkpointに追加する軽量な差分モデルのことです。
Checkpoint全体を再学習するのではなく、重みの一部だけを低ランク構造で学習するため、ファイルサイズは数MB〜数百MBとコンパクト。
特定キャラクター・画風・衣装・ポーズなどを追加学習させたものが多く、使いたいLoRAファイルをmodels/Loraフォルダに置き、プロンプト内に<lora:ファイル名:強度>と記述するだけで適用されます。
VAEとは
VAEは、画像の「潜在空間→ピクセル変換」を担う補助モデル。VAEを適用しないと色が褪せたり、ぼやけた仕上がりになることがあります。
効果は鮮明度の向上・細部描写の補正・肌の色味と光彩バランスの最適化の3点。導入方法はシンプルで、ダウンロードした.safetensorsファイルをmodels/VAEフォルダに置き、Settings→VAEまたは画面上部のクイック設定から選択すればOKです。
ControlNetとは
ControlNetは、参照画像を使ってポーズや構図・輪郭を直接制御できる拡張機能で、複雑なポーズをプロンプトだけで表現することの限界を補います。代表的なモードは2つ。
OpenPoseは元画像から人体のキーポイント(肩・肘・膝など)を抽出し、同じポーズのキャラクターを別スタイルで生成が可能。Cannyは輪郭線を抽出して構図を再現しながら、色やスタイルだけを変えることができます。導入はExtensionsタブで「sd-webui-controlnet」を検索してインストールし、別途ControlNet用モデルファイルをmodels/ControlNetフォルダに配置する必要があります。
ADetailer・Upscalerなどその他の主要拡張機能
ADetailerは、生成画像の顔・手の崩れを自動検出してインペイント処理で修正する拡張機能。
低解像度で生成した後に顔と手だけをピンポイントで補正するため、生成速度を落とさずに仕上がりが大幅に改善されます。
Extensionsタブからインストールし、生成時に「Enable ADetailer」にチェックを入れるだけで動作し、顔ならface_yolov8n、手ならhand_yolov8nのモデルを選択。Upscalerは解像度を2〜4倍に拡大する機能で、Extrasタブまたはtxt2imgのHires.fixから利用可能です。
Stable Diffusion Web UIを日本語化する方法
Stable Diffusion Web UIは、デフォルト設定で英語表記になっていますが、日本語化が可能です。日本語化する際は、以下の手順に従ってください。
- txt2imgの行の一番右にある[Extension]タブを開く
- [Available]タブを開く
- [localization]タブからチェックを外す
- [Load form]ボタンをクリックする
Stable Diffusion Web UIを日本語化する方法について詳しく知りたい方は、画像付きで解説している以下の記事を参考にしてみてください。

Stable Diffusion Web UIの拡張機能について
拡張機能の代表例としては、ControlNet・LoRA・Checkpointなどがあります。
| 拡張機能 | できること / 役割 | 向いている用途 |
|---|---|---|
| ControlNet | 画像のポーズ・輪郭・構図など“形”を正確に指定できる | 写真のポーズ再現、トレース、構図固定、実写寄りの制御 |
| LoRA | 少ない計算量で、特定の画風・キャラの特徴を強く反映できる | アニメ調、美少女系、人物の特徴付け、特定作風の再現 |
| Checkpoint(モデル本体) | 画像生成全体の“スタイル”を決めるベースモデル | 写実/アニメ/イラストなど作品の方向性選び |
それぞれの特徴や導入方法について詳しく知りたい方は、以下の記事も併せてご覧ください。



Stable Diffusion Web UIが向いている人・向いていない人
Stable Diffusion Web UIは「自由度の高さ」と「導入ハードル」の両面を持つツールです。向き・不向きを事前に把握しておくことで、後悔のない選択ができます。
無料でローカル環境を構築し、ランニングコストを抑えたい人やLoRA・ControlNet・モデル切り替えなど、細かなカスタマイズを追求したいクリエイター、データをクラウドに上げずオフラインで完結させたい人はStable Diffusion Web UIが向いているでしょう。
一方でVRAM 6GB未満のGPU環境・GPU非搭載PCの利用者や環境構築の手間なく今すぐ試したい人にはStable Diffusion Web UIは向いていないと言えます。
Stable Diffusion Web UIを利用する際の注意点
無料で高品質な画像を生成できるStable Diffusion Web UIですが、利用する際は以下の点に注意が必要です。
| 注意点 | 内容 | 補足説明 |
|---|---|---|
| 導入するまでにハードルがある | コマンド入力やライブラリのインストールが必要で、初心者には難しく感じやすい | エラーも出やすいが、導入手順やChatGPTを活用すればほとんど解決可能 |
| 希望の画像を出すにはプロンプト知識が必要 | 思い描く画像を生成するには、プロンプト(指示文)の書き方を理解する必要がある | ネット上に事例やテンプレが多いため、調べることで習得しやすい |
| 商用利用・著作権などライセンスに注意 | 生成画像の商用可否はモデルごとのライセンスに依存する | CreativeML OpenRAIL-Mなどを確認し、プライバシー侵害や不適切利用は不可 |
特に、導入するまでにさまざまなコマンドを実行して必要なライブラリをインストールする必要があるので、ITに詳しくない方からするとかなりハードルは高いです。
以下で注意点を詳しく解説するので、ぜひ参考にしてみてください。
導入するまでにハードルがある
Stable Diffusion Web UIの導入方法で解説していますが、Stable Diffusion Web UIを導入する際は、いくつかのコマンドを入力して必要なライブラリなどをインストールする必要があります。
この作業が順調に進まず、エラーが出ることも多々あるので、ITに詳しくない人からするとかなりハードルが高いです。
ただ、すでにStable Diffusion Web UIの導入方法やエラーへの対応については、当記事の内容などを参照いただければ、おおよそは解決できます。
エラーの原因がわからない場合は、ChatGPTに聞くと意外とすぐに解決できることもあるので、ぜひ活用してみてください。
希望の画像を出すためにプロンプトに関する知識が必要
自分が希望する画像を出力するためには、プロンプトに関する知識が必要です。生成AIを初めて利用する方にとっては、難しいと感じるかもしれません。
ただ、現在は多くの人はStable Diffusion Web UIを利用しているので、インターネットで検索すれば、有効なプロンプトはすぐに調べられます。
商用利用や著作権などのライセンスに注意する
Stable Diffusion Web UIで作成した画像は基本的に商用可否はモデルのライセンスで異なるため、各モデルのCreativeML OpenRAIL-M等の確認が必要です。また、他人のプライバシーを侵害する内容や人に危害を加えるような目的での使用は認められていません。
CivitaiやHugging Faceでモデルをダウンロードする際も、個別に商用利用の可否などが設定されているので、ダウンロード前に確認しておきましょう。
\画像生成AIを商用利用する際はライセンスを確認しましょう/

他の画像生成AIとの比較
| 項目 | Stable Diffusion Web UI | Midjourney | ChatGPT(GPT-4o) | Nano Banana |
|---|---|---|---|---|
| 操作方法 | ローカルUI | Discord / Web | ブラウザ / アプリ | Gemini / AI Studio |
| カスタマイズ性 | 高い(LoRA・拡張機能) | 低め | やや低め | 低め |
| 生成スピード | スペック依存 | 速い | 速い | 速い |
| 無料範囲 | 無料(ローカル) | なし(完全有料) | 無料あり(枚数制限) | 無料あり(回数・解像度制限) |
| 商用利用 | 可(モデルによる) | 可(有料プランのみ) | 可(利用規約あり) | 可(ウォーターマーク・規約に注意) |
| 環境構築 | 必要(GPU推奨) | 不要 | 不要 | 不要 |
注意点として、Stable Diffusion Web UI自体は無料で使えますが、Stable Diffusion Web UIを使うにあたりかかってくる電気代やストレージ、クラウド費用などは別途かかります。Stable Diffusion Web UI以外にも、画像生成AIにはさまざまなツールが存在します。
その中でも特に代表的なのが「Midjourney」や「DALL·E」「Nano Banana」などです。ここでは、それぞれの特徴とStable Diffusion Web UIとの違いを比較します。
Midjourneyとの違い
Midjourneyは、Discord上で操作するスタイルが特徴の画像生成AIです。プロンプトを入力するだけで美しく仕上がった画像を素早く出力できるため、操作の手軽さやデザイン性の高さが評価されています。しかし、細かなカスタマイズやモデルの切り替えはできません。
Stable Diffusion Web UIは、自分のローカル環境に構築することで、モデルや拡張機能を自由に追加できるのが大きな強みです。構図やスタイルの細かい調整が可能で、より自分好みに作り込みたい場合に適しています。
DALL·Eとの違い
DALL·EはOpenAIが提供する画像生成AIで、特にテキストからの画像生成精度が評価されています。2024年以降は「inpainting(画像の一部だけを修正)」機能も強化されており、編集用途にも活用されています。ただし、無料プランには使用制限があり、大量に生成する場合は有料プランへの加入が必要です。
Stable Diffusion Web UIはローカルで動作するため、インターネット環境に依存せず、使用回数の制限もありません。商用利用や大量生成を行う場合でも、コストを抑えながら運用できるのが利点です。
ChatGPT画像生成(GPT-4o)との違い
2025年3月のアップデートで、ChatGPTの画像生成はDALL·Eを経由せずGPT-4oにネイティブ統合。
テキスト・画像・音声を同じトークン空間で扱うマルチモーダルモデルとなり、複数キャラクターを含む複雑な構図や、看板・UI内の文字描写の精度が大幅に向上しました。
無料プランでも利用できるが1日あたりの生成枚数に制限があり、制限なく安定利用するにはPlus(月額20ドル)が実質必要です。
Nano Bananaとの違い
Nano BananaはGoogleのGeminiに搭載された画像生成モデル。
最大の強みはキャラクターの一貫性維持と自然言語による直感的な編集で、「表情を柔らかくして」「背景をもっと明るく」といった日本語の会話口調でそのまま修正可能。
GeminiアプリやGoogle AI Studioから無料で使えるが、無料版には生成回数・解像度の制限があり、Geminiアプリ経由だと生成画像にウォーターマークが入ります。
Stable Diffusion Web UIと比べると、環境構築やモデル選定の手間が一切不要で誰でもすぐ始められる反面、LoRAでのスタイル追加やControlNetでのポーズ制御といった高度なカスタマイズは非対応。
Stable Diffusion Web UIの活用事例
Stable Diffusion Web UIは、個人利用だけでなく、企業による活用も広がりつつあります。特に、商品企画やプロモーションの分野では、画像生成AIの柔軟性や表現力を活かした事例が増加しました。ここでは、実際にWeb UIを活用した企業の取り組みを紹介します。
プロモーション施策への応用
2023年9月26日、アサヒビールは新商品「アサヒスーパードライ ドライクリスタル」のブランドサイトにて、画像生成AI「Stable Diffusion」を活用した体験型プロモーション施策 「Create Your DRY CRYSTAL ART」 を日本で初めて展開しました。
このサービスでは、ユーザーが自身の写真とテキスト(例:「こんなとき輝いている」など)を入力すると、水彩画風やアニメ風などのスタイルを指定して、オリジナルアート作品を生成することができます。満20歳以上であれば誰でも無料で利用可能で、スマートフォンからLINE連携でアクセス可能です。
このプロジェクトは、Stable Diffusionを活用した大規模かつ消費者参加型のプロモーションとして初の事例であり、ブランドの世界観を体験として届ける新しい試みとして注目されました。
ゲーム開発での活用
ゲーム開発を手がけるレベルファイブは、制作初期の案出し工程にStable Diffusionを活用しています。
ゲームタイトル画面のレイアウト案、背景美術のラフ、3Dマップの室内案など、複数のバリエーションを短時間で生成し、デザイナーの発想支援に利用しています。最終的なブラッシュアップは人が行うものの、AIによって初期アイデアの幅を大きく広げられる点が評価されています。
商品企画のスピード化と効率化
セブンイレブン・ジャパンは、2024年春から生成AIを商品企画プロセスに実験導入し、その後本格運用を開始しました。
これは、OpenAIやStability AIと連携して構築されたクラウドベースのAIシステムを活用し、販売データやSNS上の消費者の声をリアルタイムに分析する仕組みです。
この取り組みにより、商品コンセプトの文章や広告イメージ案をAIが自動生成し、従来の企画期間を最大で90%短縮できると報じられています。さらに、このAI活用は管理職層から導入が始まり、2024年春以降には一般社員への展開がされました。商品企画の初期段階だけでなく、パッケージデザイン案やPOP広告のイメージ生成にもAIを活用して、社内の作業工数やコストの削減、マーケティングのスピード向上に貢献しています。
Stable Diffusion Web UIでよくある質問
Stable Diffusion Web UIでよくある質問をまとめました。
Stable Diffusion Web UIでおすすめのプロンプトは?
Stable Diffusion Web UIでは、「high resolution」といった画質を指定するプロンプトや「manga style」といったスタイルを指定するプロンプトを入れるのがおすすめです。
また、高精度の画像を生成したいなら、優先順位の高い単語を前に持ってくる、重要な単語を「」で囲うといったテクニックも有効です。
おすすめのプロンプトについて詳しくは、以下の記事をご覧ください。

Stable Diffusion Web UIのおすすめモデルは?
「yayoi_mix」や「blue_pencil」がおすすめです。
「yayoi_mix」はリアルなAI美少女、「blue_pencil」はハイクオリティなアニメ風イラストが作れます。
なお、Stable Diffusionにおける「モデル」とは、画像生成を行うために学習するデータセットやアルゴリズムの組み合わせのことです。
おすすめモデル一覧や導入方法について詳しくは、以下の記事をご覧ください。

Stable Diffusion Web UIの「CFG Scale」とは?
「CFG Scale」とは、入力したプロンプトへの忠実度を設定するパラメータのことです。値が大きいほどプロンプトに忠実な画像が生成できますが、大きくしすぎると画像にノイズが入ります。
パラメータは、1〜30までありますが、基本的には15〜20あたりがおすすめです。
CFG Scaleについて比較検証した記事もあるので、ぜひご覧ください。

Stable Diffusion Web UIとは
Stable Diffusion Web UI(Automatic1111版)は、画像生成AI「Stable Diffusion」をWebブラウザ上の画面から簡単に操作できるようにした無料ツールです。複雑なコマンドを知らなくても、テキストを入力するだけでAI画像を作れるのが最大の特徴です。モデルの切り替え、LoRA・ControlNetなどの拡張機能、解像度やスタイルの細かな調整にも対応しており、プロのクリエイターから初心者まで幅広く利用されています。
インストール後はオフラインでも使えるため、セキュリティ面で安心して商用制作にも活用できる環境を構築できます。ただし、商用利用の可否はモデルのライセンスによるので確認が必要です。
Web UI のインストールが難しいのですが、簡単に使う方法はありますか?
Runpod のようなクラウドサービスで「Stable Diffusion Web UIテンプレート」を使えば、インストール不要・ブラウザで即利用できます。
手元のPCスペックに不安がある人や、Macユーザーに特に人気です。
起動しない・真っ黒な画像が出るときはどうすればいい?
よくある原因と対処方法は以下の通りです。
| 原因 | 具体的な症状 | 対処法 |
|---|---|---|
| Python のバージョンが合っていない | 起動しない / コンソールにエラーが表示される | 推奨の Python 3.10 系を再インストールし、再起動して起動し直す |
| モデルの配置フォルダが間違っている | モデルが読み込まれない / 生成が始まらない | models/Stable-diffusion フォルダに .safetensors または .ckpt を配置する |
| CFG Scale や Steps の設定が極端 | 黒い画像・崩れた画像が出る | CFG Scale を 7〜10、Steps を 20〜30 に戻して再生成する |
| VRAM 不足 | 生成中にエラーが出る / Web UI が落ちる | 解像度を下げる、ControlNetを切る、–medvram や –lowvram で起動する |
Stable Diffusion Web UIで画像を生成してみよう!
Stable Diffusion Web UIは、Webブラウザ上で手軽に画像を生成できる便利なアプリです。利用することで、以下のメリットを受けられます。
【Stable Diffusion Web UIを利用するメリット】
- 無料で利用できる
- カスタマイズが可能
- オフラインでも利用可能
ただし、導入する際の工程が多く、ハードルは少々高めです。
本記事でも導入方法を画像付きで詳しく解説しているので、ぜひ参考にしてみてください。

最後に
いかがだったでしょうか?
「Stable Diffusion Web UI」は、自由度の高い画像生成を可能にし、クリエイティブな業務を効率化します。この技術をビジネスにどう活用できるか、可能性を模索してみてください。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。

