
【MobileDiffusion】スマホで高精度画像が作れる画像生成AI!性能を徹底解説

WEELメディア事業部AIライターの2scです。
みなさん!Googleの画像生成AI「MobileDiffusion」はご存知ですか?
MobileDiffusionはなんと、スマホ上で動く画像生成AIで……

このクオリティの画像を最短0.2秒で生成できちゃう優れものなんです。
当記事ではそんなMobileDiffusionの仕組みや従来からの改良点を徹底解説!エンコーダ / デコーダ等の専門用語も噛み砕いて、わかりやすくお届けします。
完読いただくと、画像生成AIの原理までつかめる……かも!ぜひ、最後までお読みください。
\生成AIを活用して業務プロセスを自動化/
MobileDiffusionの概要
「MobileDiffusion」は、2023年11月にGoogleが発表した研究段階の画像生成AIです。(※1)その特徴・すごいところは……
● プロンプトから画像が生成できるText-to-Imageモデル
● スマートフォン上で、0.2秒以内に512×512画像が生成可能(※2)
● Stable Diffusion同様拡散モデルだが、パラメータ数は5億2000万とコンパクト
(→Stable Diffusion系は数十億)
● 既製の画像生成AIの学習結果を学習すること(蒸留)で、推論を8ステップにまで削減
● さらに拡散UNetの構成の見直しで、推論を1ステップにまで削減
以上のとおり。従来の画像生成AI比ではパラメータ数・推論のステップ数がそれぞれ削減されていますが、生成画像についても……

このように、申し分ないクオリティになっています。


MobileDiffusionの構成要素
MobileDiffusionはStable Diffusion(web UI) / DALL-E 3 / Midjourney同様、プロンプトから画像が生成できる「Text-to-Imageモデル」です。そんなMobileDiffusionは、他のText-to-Imageモデル同様……
- テキストエンコーダ:プロンプトをベクトルに翻訳する
- ディフュージョンネットワーク:ベクトルを参考に画像の大枠(潜在表現)を生成
- 画像デコーダ:画像の大枠から高精度な画像を生成
の3パートからなる「拡散UNet」を搭載しています。拡散UNetの各構成要素について、以下で詳しくみていきましょう!
テキストエンコーダ
画像生成AIの本体は画像の特徴を学習し、それをもとに新たな画像を生成するAIモデルに過ぎません。プロンプトを理解するためには別途、「テキストエンコーダ」が必要です。
このテキストエンコーダは、プロンプトを(画像の特徴を表した)ベクトルに変換する役割を担います。人間と画像生成AIの間を取り持つ、いわば通訳です。
今回のMobileDiffusionも、このテキストエンコーダを搭載。具体的には、小型(125Mパラメータ)のテキストエンコーダ「CLIP-ViT/L14」を採用しています。
ディフュージョンネットワーク
画像の特徴を表したベクトルを参考にして、新たな画像を生成するのは「ディフュージョンネットワーク」の仕事。MobileDiffusionやStable Diffusionの名前は、この処理に由来しています。
このディフュージョンネットワークの仕組みは……
学習時:画像をまっさらなキャンバスに戻す(ノイズをかける)過程を学習する
画像生成時:学習した過程の逆処理で、荒削りな画像(潜在表現)を描画する
以上のとおりです。
画像デコーダ
ディフュージョンネットワークが生成する画像は荒削り。人間が制作した写真・イラストに近づけるには、あともう一段階「画像デコーダ」が必要です。
この画像デコーダは、ベクトルで表現された荒削りな画像(潜在表現)を精細なピクセル画像に変換するためのもの。MobileDiffusionは後述するように、専用に改良された画像デコーダを搭載しています。
なお、ベクトルの概念について詳しく知りたい方は、下記の記事を合わせてご確認ください。

MobileDiffusionと従来型画像生成AIの違い
MobileDiffusionには、従来の画像生成AI(Stable Diffusion等)と比較して、3つの改良点があります。それは……
- 拡散UNetの構成:Transformerの割合を増やした
- 画像デコーダの種類:小型かつ高精度な画像デコーダを独自開発・採用した
- 学習の方法:既製の画像生成AIの学習結果を学習させた(蒸留)
以上のとおり。まずは、先ほども紹介した拡散UNetについて、詳しい改良点をみていきましょう!
拡散UNetの構成
MobileDiffusionの拡散UNetでは、従来型比でTransformer(ChatGPTと同じブレイン)の比率が増えています。
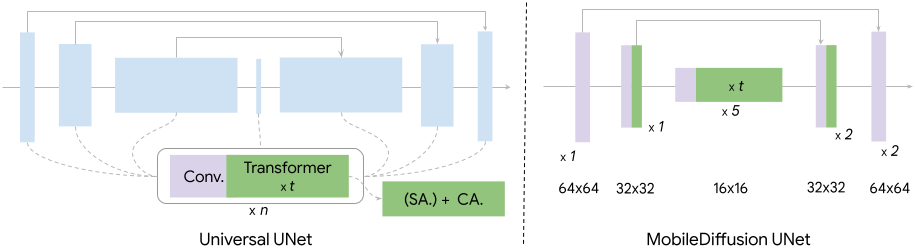
Transformerの比率が増えた結果、
- 高解像度における画像の特徴抽出のパートを省略、計算コストを削減
- 生成画像のクオリティはキープ
といったスペックが実現しました。一言でまとめると……
Transformer採用で賢くなったので、画像の特徴説明が省けるようになった
というわけです。
画像デコーダの種類
MobileDiffusionでは、生成画像の品質をブラッシュアップする画像デコーダにも改良が加わっています。Google独自開発の画像デコーダが採用されており……
| Decoder | パラメータ数 | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|
| Stable Diffusion の画像デコーダ | 49.5M | 26.7 | 0.76 | 0.037 |
| MobileDiffusion の画像デコーダ | 39.3M | 30.0 | 0.83 | 0.032 |
| MobileDiffusion の画像デコーダ(軽量版) | 9.8M | 30.2 | 0.84 | 0.032 |
- パラメータ数:小さいほど処理が速い
- PSNR(ピーク信号対雑音比):大きいほど画像がキメ細やか
- SSIM(構造的類似性指数):大きいほど画像が目にみえて綺麗
- LPIPS(Learned Perceptual Image Patch Similarity):大きいほど入力に対する生成画像の再現度が高い
というふうにLPIPSはそのまま、処理速度・精度が従来比で改善しているんです。
学習の方法
MobileDiffusionでは、トレーニング回数が10,000回未満に抑えられています。その秘訣は学習に用いられた手法「蒸留」で……
従来型画像生成AIの学習方法:ゼロから、大量の画像を全て学習
MobileDiffusionの学習方法(蒸留):既存のAIモデルを流用し、抽出済みの画像の要点だけを学習
このようにして、学習についても効率化がなされているんです。
なお、Apple発のスマホで動くマルチモーダルAIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

MobileDiffusionにできること
精度はそのまま、従来比で処理が軽くなったMobileDiffusion。そんなMobileDiffusionなら……
- スマートフォン上での高速画像生成
- スマートフォン上での高精度画像生成
が、可能です。それぞれ、以下で詳しくみていきましょう!
スマホ上での高速画像生成
MobileDiffusionなら、スマートフォン上でもたったの半秒ほどで画像が生成できます。
iPhone 15 ProおよびSamusung S24で、MobileDiffusionにおける画像生成までの待ち時間(Total Latency)を測ってみたところ……

このように、従来の画像生成AI(Stable Diffusion 1.5 / SnapFusion)比で大幅にスピードがUP。iPhone 15 Proにいたっては、なんと0.2秒で画像生成が完了しているんです。
スマホ上での高精度画像生成
MobileDiffusionは精度の面も抜かりありません。スマートフォン上でMobileDiffusionに画像を生成させると……

このように、リアルな画像が512×512サイズで返ってきます。
MobileDiffusion搭載のスマホは?
今回のMobileDiffusionを応用して、将来的には画像生成AIを搭載したスマートフォンが開発できるかもしれません。
実はすでに、Googleは小型LLM・Gemini Nanoを搭載した生成AIスマホ「Pixel 8 Pro」をリリース済み。Pixel 8 Proの時点で、
- 録音の文字起こしと要約
- 返信メールの文章生成
- 撮影した写真や動画の合成 / 加工…etc.
がオフラインのモバイル端末上で実現しています。ここに画像生成機能が加わるとなると……将来が楽しみですね!
なお、Pixel 8 Proを含むGeminiの活用事例について詳しく知りたい方は、下記の記事を合わせてご確認ください。

スマホ上でサクサク画像生成できるMobileDiffusion
当記事ではスマートフォン上で動くGoogleの画像生成AI「MobileDiffusion」について解説しました。このMobileDiffusionの特徴・すごいところは……
● プロンプトから画像が生成できるText-to-Imageモデル
● スマートフォン上で、0.2秒以内に512×512画像が生成可能
● Stable Diffusion同様拡散モデルだが、パラメータ数は5億2000万とコンパクト
(→Stable Diffusion系は数十億)
● 既製の画像生成AIの学習結果を学習すること(蒸留)で、推論を8ステップにまで削減
● さらに拡散UNetの構成の見直しで、推論を1ステップにまで削減
以上のとおりでした。すでに生成AIスマホをリリースしているGoogleがこれを発表した、ということは……今後のPixelシリーズにも期待がもてそうですね。

最後に
いかがだったでしょうか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。

