
初心者でも分かる!小規模言語モデル(SLM)の特徴やメリットを分かりやすく解説

生成AIを利用するためには、膨大な量のデータを処理するためスペックの高いデバイスが必要になることがあります。しかし、コスト的にハイスペックなデバイスを導入をすることが難しい環境もあるでしょう。
そんな時に活躍するのが小規模言語モデルです。この記事では、小規模言語モデルの概要だけではなく、メリットやデメリットまでご紹介します。最後には、代表的な小規模言語モデルもご紹介しますので、ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
小規模言語モデル(SLM)とは?
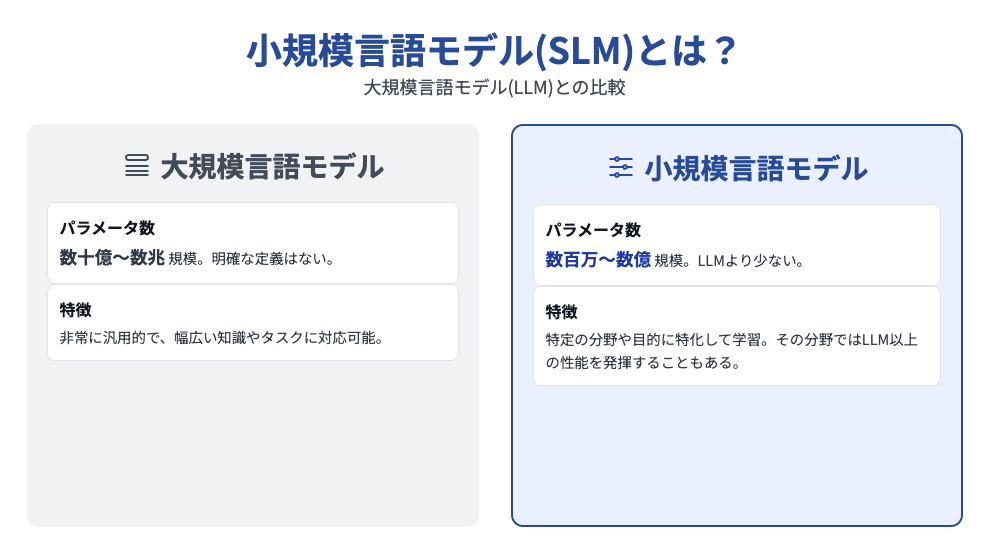
小規模言語モデル(Small Language Model)とは、名前の通りChatGPTやClaudeのような大規模言語モデル(Large language Models)に比べて、少ないパラメーター数で構成されているモデルのことを指します。
小規模言語モデルと大規模言語モデルの明確な定義はありませんが、小規模言語モデルは数百万〜数億、大規模言語モデルは数十億〜数兆のパラメーター数という具合に振り分けられていることが多いです。
また、小規模言語モデルの特徴としては、大規模言語モデルと比べると汎用性にかける部分がありますが、特定の分野や目的に絞ってトレーニングするため、小規模ながらも学習させた分野においては、大規模言語モデル以上の性能を発揮することがあるとがあります。
小規模言語モデル(SLM)のしくみ
小規模言語モデル(SLM)はトレーニングに用いる「データセットの質」に重きを置いた言語モデルです。こちらはデータセットの質を上げて量を減らすことで、データ処理の精度を保ったままパラメータ数のみの削減を実現しています。
この効果を示した論文として、小規模言語モデル「phi-1」と従来のLLMのデータ処理精度を比較した「Textbooks Are All You Need」というものがあります。この論文では、コーディングテストでのスコアを比較していて、その結果は以下のとおりです。
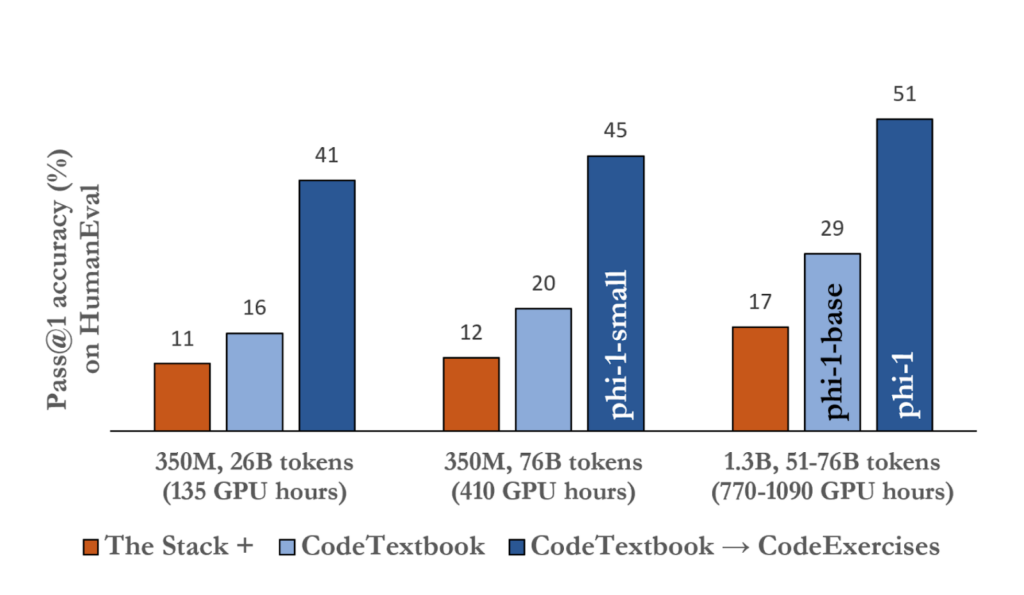
phi-1と従来のLLMを比較してみると、phi-1のパラメータ数は1.3Bと非常に小さい値であるにも関わらず、処理精度はむしろ優れているという結果になっています。
さらに、phi-1に使用されたデータセットはたったの7Bであり、トレーニングに要した期間はわずか4日間でした。
以上の結果より、LLMは質の高いデータセットでトレーニングすることで、「パラメータ数を小さく抑えつつデータ処理精度も高められる」ということがわかります。
なお、大規模言語モデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。


小規模言語モデル(SLM)が注目される背景
小規模言語モデルはその導入しやすさとコストパフォーマンスにより、企業からの注目を集めています。
ChatGPTの登場以降、国内外の企業では、LLMの導入・業務利用が推し進められてきました。ただ昨今では、企業のLLM導入について、以下の問題点が浮き彫りとなっています。(※1)
- 導入コスト(GPU等)が高騰しており、場合によっては数億〜十数億円単位となる
- AIモデルをクラウド上で稼働させるため、データのプライバシーを確保できない
- 用途に対してオーバースペックとなる
そこでLLMに代わって脚光を浴びているのが、パラメータ数の少ないSLMです。こちらはLLMに対して以下のアドバンテージがあり、金融・医療業界を中心に活用の裾野が広がってきています。
- オープンソースかつ省メモリ性が高いため、導入・学習・運用のコストが抑えられる
- ノートPC等のローカル環境上で稼働させられるため、機密性が高い
- 業界特化のデータセットで学習させることで、必要十分なスペックを確保できる
GoogleやMicrosoftのような生成AI開発の大手も、次々とSLMをリリースしており、LLMに続く一大ブームが起こりつつあります。
小規模言語モデル(SLM)と大規模言語モデル(LLM)の違い
ここでは、小規模言語モデルと大規模言語モデルについて、両者の違いとそれぞれに適した活用シーンを表形式でみていきます。以下、違いから比較を行っていきましょう!
違いの比較
小規模言語モデルと大規模言語モデルの違いは、表にまとめると以下のとおりになります。
| 小規模言語モデル(SLM) | 大規模言語モデル(LLM) | |
|---|---|---|
| パラメータ規模 | 数億〜数十億 | 数百億〜数兆 |
| 学習データ | 専門領域に特化 | 理数から人文、日常会話まで網羅 |
| 処理速度 | 高 | 低(加えてクラウド化によるタイムラグも) |
| 汎用性 | 低 | 高 |
| 開発に要する費用・時間 | 小 | 極大 |
| 稼働に必要なハードウェア | ノートPC(GPU1基) | 大規模なデータセンター(GPU数千基) |
LLMに比べ、SLMはスペックが限定される代わりに、ソフト面でもハード面でも導入しやすい点が魅力です。
使い分け早見表
小規模言語モデルと大規模言語モデルのそれぞれに適した活用シーンは以下のとおりです。
| 用途 | 小規模言語モデル(SLM) | 大規模言語モデル(LLM) |
|---|---|---|
| 長文の生成 | ❌ | ⭕️ |
| 文書の要約 | ⭕️ | ⭕️ |
| コーディング支援 | ❌ | ⭕️ |
| オンプレミスシステムとの統合 | ⭕️ | ❌ |
| 保険・金融・医療業界での活用 | ⭕️ | ❌ |
| 社内向けチャットボット | ⭕️ | ⭕️ |
| 顧客向けチャットボット | ❌ | ⭕️ |
| リアルタイムでの応答 | ⭕️ | ❌ |
LLMほどの回答精度・品質はないものの、SLMは幅広いユースケースに適しているといえるでしょう。
小規模言語モデル(SLM)のメリット
小規模言語モデルの概要は先ほどご紹介させていただきましたが、小規模言語モデルにはどのようなメリットがあるのでしょうか。
まずは、小規模言語モデルのメリットについてご紹介します。
開発コストを抑えられる
小規模言語モデルは大規模言語モデルに比べて、サイズが小さいため必要な学習データの量や計算リソースも限られた量だけでいいので、開発期間が短くなることが多いです。
生成AIの開発を外注する場合は、人件費や開発期間によって料金が前後するため、アサインする人数や開発期間が短い小規模言語モデルは大規模言語モデルに比べて開発コストを抑えることができます。
反応速度が早い
小規模言語モデルは、大規模言語モデルのように膨大なデータから回答を生成するわけではなく、限られた学習データの中で回答を生成するため、反応速度が早いのが特徴です。
そのため、待ち時間を減らし業務効率をあげることができるため、汎用性の高い大規模言語モデルではなく、業務に特化し反応速度の早い小規模言語モデルが重宝される場面も多くあります。
限られたリソースで動作可能
大規模言語モデルに比べて、小規模言語モデルはデータ量や計算リソースが少ないため、幅広いデバイスで利用することができます。
例えば、大規模言語モデルを利用するにはスペックが足りないPCやスマートフォン、タブレットなどの端末上でも動かすこともできるので、ハイスペックな端末が用意できない環境でも利用できるのがメリットでしょう。
ハルシネーションが発生しづらい
生成AIは便利なツールですが、あたかも真実のように嘘の情報を出力することがあります。この現象をハルシネーションといいます。
大規模言語モデルでは、膨大な学習データの中から回答を生成するため、このハルシネーションが発生する可能性が高いと考えられます。
それに対して小規模言語モデルは、特定の分野や目的に絞って学習・トレーニングを行うため不要な情報を挟まずに処理を行えるため、ハルシネーションが発生しづらいのが特徴です。
ファインチューニングが容易
ファインチューニングとは、簡単に説明すると回答精度を高めたり目的に沿ったモデルにするために、学習済みのモデルの一部や全てを再学習させる手法のことです。
大規模言語モデルをファインチューニングしようとする場合、膨大なデータを扱っているため、あらゆる場合を想定して再学習をする必要があるため手間がかかってしまいます。
しかし、小規模言語モデルの場合はもともとデータ量が少なく、特定の分野や目的に沿って構成されているモデルなので、再学習しやすい点もメリットと言えるでしょう。


小規模言語モデル(SLM)のデメリット
ここまで、小規模言語モデルのメリットについては理解いただけたかと思いますが、もちろん小規模言語モデルにもデメリットがあります。
次に、小規模言語モデルのデメリットについてみてみましょう。
汎用性が低い
小規模言語モデルは特定の分野や目的に絞って作られたモデルなので、専門的な分野や特定のタスクにおいては高い性能を持っています。
このように、専門的な分野においては高い性能を誇っていますが、大規模言語モデルのように幅広いタスクをこなすことはできません。あくまで、限られた環境でのみ性能を発揮する汎用性の低いモデルであるということは理解する必要はあるでしょう。
データ収集が難しい
小規模言語モデルは専門的な分野に特化したモデルであるため、ハルシネーションを起こしづらいというメリットがあることは前章でご紹介しましたが、それゆえに正確な専門的な情報を集める必要があります。
特に、専門性の高い法律や医療の分野で活用する場合は、データ収集や学習、トレーニングを行う際にも専門的な知識が必要なため、データ収集が難しいという点においてはデメリットといえるでしょう。
代表的な小規模言語モデル(SLM)

冒頭でもご紹介した通り、小規模言語モデルと大規模言語モデルの明確な定義はありませんが、世間一般的に小規模言語モデルと区分されるモデルはたくさんあります。
今回は、その中でも代表的な小規模言語モデルを4つご紹介します。
Phi-3
Phi-3はMicrosoft社が開発したオープンソースの高性能小規模言語モデルです。
Phi-3の中にも種類があり、その中でも2024年4月23日に公開された「Phi-3-mini」はシリーズ最小モデルで、スマートフォン等の小型デバイスでも動作するほど軽量かつ、数倍も大きいモデルと同等の性能を発揮することができます。
Phi-3-miniは高性能ながらも無料で利用でき、商用利用も可能なため幅広い分野で活用されています。
なお、Phi-3シリーズ最小のPhi-3-miniについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

StableLM 2 1.6B
StableLM 2 1.6Bは、代表的な画像生成AIであるStable Diffusionを公開しているStability AIが開発した小規模言語モデルです。
英語、スペイン語、ドイツ語、イタリア語、フランス語、ポルトガル語、オランダ語の多言語データでトレーニングされており、そのパラメータ数は16億という非常に小型の言語モデルですが、大規模言語モデルを上回る性能を持っています。
Stability AI Membershipに登録していれば無料で利用できるので、興味のある方は利用することをお勧めします。
なお、StableLM 2 1.6Bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Orca-2-13b
こちらのOrca-2-13bもMicrosoft社から公開された小規模言語モデルで、meta社が開発したLLAMA 2をベースにファインチューニングされており、推論や論理的な問題解決に焦点を当てた言語モデルとなっています。
パラメーター数は13億となっていますが、複雑な推論プロセスを模倣するように設計されているため、大規模な基礎モデル(LFM)のように複雑な推論を行う能力を持っているのが特徴です。
なお、Orca-2-13bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

TinyLlama-1.1B
TinyLlama-1.1Bは、シンガポールの大学のNLP研究チームが公開したモデルです。最大の特徴としては、Llama 2と同じアーキテクチャとトークナイザーを採用しながらも、Llama 2よりも軽量であるため、メモリを節約しつつ高速に文章を生成することが可能な点です。
こちらも、誰でも無料で利用が可能なオープンソースなので、高スペックな端末を持っていないけど、高速で文章を生成したいという方におすすめです。
なお、TinyLlama-1.1Bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Gemma 3n
Googleの「Gemma 3n」は、スマートフォンやノートPC上での稼働に最適化された小規模言語モデルです。こちらはテキスト(日本語を含む140+ヶ国語)と画像&音声の入力に対応したマルチモーダルAIモデルで、以下の軽量化技術が採用されています。(※2)
- PLEパラメータをローカルストレージに一時保存する「PLEキャッシング」
- タスクごとに最適な量の思考を行う「MatFormerアーキテクチャ」
- 平時は画像・音声の処理を停止する「条件付きパラメータ読み込み」
これらの技術により、Gemma 3nはエッジデバイスでの稼働(エッジAI)にも対応しています。
なお、Gemma 3nについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

TinySwallow-1.5B
「TinySwallow-1.5B」は、日本に本社を構える生成AIスタートアップのSakana AIが開発した、日本語特化の小規模言語モデルです。こちらは段階的に知識を蒸留する新手法「TAID(Temporally Adaptive Interpolated Distillation)」を採用。同規模のライバルを圧倒する日本語性能とiPhone等エッジデバイス上での稼働を両立しています。(※3)
tsuzumi
NTTが開発した「tsuzumi」は小規模言語モデルの条件を満たす、日本語特化・マルチモーダル対応の小型LLMです。このtsuzumiはなんと、社会科の知識を問う日本語ベンチマーク「Rakudaベンチマーク」による比較で、GPT-3.5に対して81.3%の勝率を実現。加えて、部分的にファインチューニングを行える「アダプタ」を採用しており、幅広い業界での導入に適しています。(※4)
cotomi
NECが開発した「cotomi」も、小規模言語モデルの要件に準拠する日本語特化の小型LLMになります。その特徴は以下のとおりです。
- 日本語ベンチマーク「Japanese MT-Bench」でGPT-4級の回答精度を発揮
- 省メモリ・省電力
- クラウド / 専用ハードウェアの両方で稼働可能
このcotomiは丁寧な日本語文の生成が得意で、ビジネスユースでも通用するクオリティとなっています。(※5)
失敗しないSLM×LLMハイブリッド設計
小規模言語モデルは日進月歩で、すでに高速・低コストながらも単体でビジネスユースに耐えうる精度のものが登場しています。ただ、全体的な回答の質はLLMにもう一歩及ばない、というのが現状です。
そこでSLMを導入・活用するにあたっておすすめしたいのが、SLMとLLMを組み合わせて効率と精度を両立させるハイブリッド設計です。このハイブリッド設計には様々な手法がありますが、なかでも下表の方式は簡単に導入ができて恩恵も得られやすくなっています。
| SLMの役割 | LLMの役割 | 全体での効果 | |
|---|---|---|---|
| ルールベースルーティング | 平時の回答生成を高速・低コストで行う | SLMが答えられない(回答の信頼度が一定のしきい値を下回る)質問にのみ回答 | 回答生成の7%をLLMに任せるだけで、SLM単体よりも60%精度が向上(※6) |
| Collab-RAG | 複雑なクエリを単純なサブクエリに分解 | サブクエリをもとにベクトルデータベースを検索・参照し、回答を生成 | LLM単体との比較で、1.8%〜14.2%精度が向上(※7) |
このハイブリッド設計については弊社・株式会社WEELでも、下記のとおり開発事例があります。
生成AI導入で「コストも精度も諦めたなくない」とお考えの方はぜひ一度、お気軽にご相談ください。
小規模言語モデルと大規模言語モデルをうまく使い分ける

小規模言語モデルと大規模言語モデルにはそれぞれメリットとデメリットがあります。基本的には大は小を兼ねると思われがちなため、大規模言語モデルの方が汎用性があって使いやすいと思う方もいらっしゃるでしょう。
もちろん汎用性が高いということは、さまざまなシーンに対応できるため便利ではありますが、処理速度が遅かったり、ハルシネーションを起こす可能性も高いです。
それに比べて、小規模言語モデルは対応範囲は狭いものの、利用方法によっては大規模言語モデルよりも性能が高く、処理速度もあげることができます。
しかし、生成AIの活用方法は人それぞれなので一概にどちらが良いとは言えません。そのため、生成AIを導入して果たしたい目的や用途をしっかりと決めた上で、専門知識を持ったエンジニアに相談しながらモデル規模を決めていく必要があるでしょう。

最後に
いかがだったでしょうか?
SLMとLLMの最適な使い分けやハイブリッド設計の導入は、ビジネスの成否を左右する重要な選択です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。
- ※1:生成AIを低コストで 小規模言語モデル「SLM」参入活発 – 日本経済新聞
- ※2:Gemma 3n model overview | Google AI for Developers
- ※3:新手法「TAID」を用いた小規模日本語言語モデル「TinySwallow-1.5B」の公開
- ※4:NTT版大規模言語モデル「tsuzumi」 | NTT R&D Website
- ※5:NEC開発の生成AI「cotomi」: NEC Generative AI | NEC
- ※6:[2504.07878] Token Level Routing Inference System for Edge Devices
- ※7:[2504.04915] Collab-RAG: Boosting Retrieval-Augmented Generation for Complex Question Answering via White-Box and Black-Box LLM Collaboration

【監修者】田村 洋樹
株式会社WEELの代表取締役として、AI導入支援や生成AIを活用した業務改革を中心に、アドバイザリー・プロジェクトマネジメント・講演活動など多面的な立場で企業を支援している。
これまでに累計25社以上のAIアドバイザリーを担当し、企業向けセミナーや大学講義を通じて、のべ10,000人を超える受講者に対して実践的な知見を提供。上場企業や国立大学などでの登壇実績も多く、日本HP主催「HP Future Ready AI Conference 2024」や、インテル主催「Intel Connection Japan 2024」など、業界を代表するカンファレンスにも登壇している。

