
【RAG Fusion】LLMのハルシネーションを防ぐRAGの進化版!その効果を徹底検証

WEELメディア事業部AIライターの2scです。
ITエンジニアのみなさん!生成AIに学習範囲外の知識を与える「RAG Fusion」はご存知ですか?
RAG Fusionは、AIチャットボットに用いられるRAGの進化形。従来型RAGよりも深く知識が反映できて……
このように、質問の意図をよく理解するAIチャットボットが作れちゃうんです!
当記事では、そんなRAG Fusionの仕組みやRAGからの改善点を解説。加えて記事の最後に、Pythonを使ったRAG Fusionの実演も載せております。
完読いただくと、かしこいAIチャットボットが作れちゃう……かもです!
ぜひ最後までお読みくださいね。
\生成AIを活用して業務プロセスを自動化/
RAG Fusionの概要
「RAG Fusion」はLLM(大規模言語モデル)のハルシネーションを防ぐ方法の一種。学習範囲外の事実をプロンプトに挿入するRAG(Retrieval Augmented Generation)の進化版にあたります。
そもそもRAGのしくみは、
- ユーザーが質問を入力
- 質問に関連する事実をベクトルデータベースから検索
- 検索結果をプロンプト経由でLLMに提示(Few-shot Learning)
- LLMが事実を踏まえた回答を生成
というものでした。対してその進化版・RAG Fusionでは……
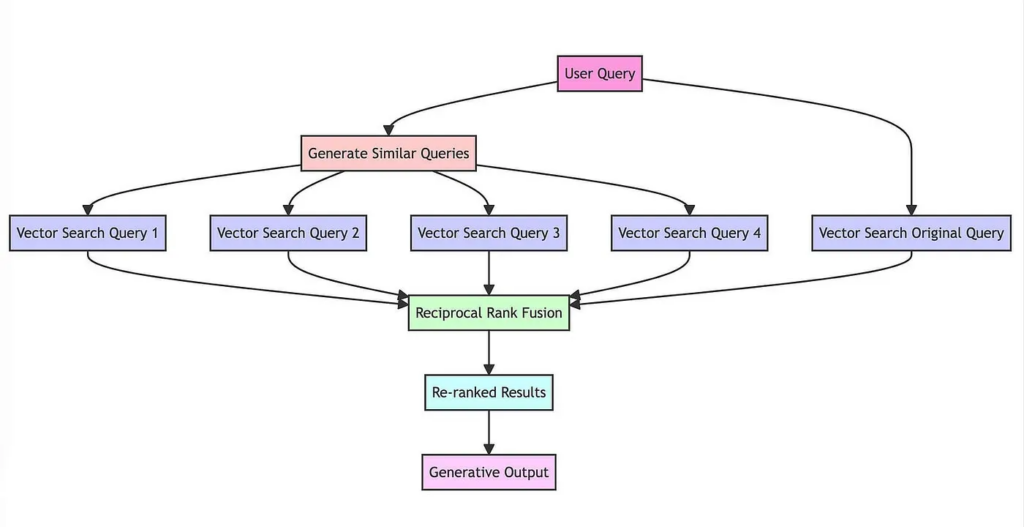
- ユーザーがオリジナルの質問を入力
- LLMが質問に関連する新たな質問を複数生成
- オリジナルの質問・新たな質問それぞれで、ベクトルデータベースから事実を検索
- 複数の質問で得られた検索結果をまとめて順位付け(リランキング)
- 上位の検索結果をプロンプト経由でLLMに提示(Few-shot Learning)
- LLMが事実を踏まえた回答を生成
以上のとおり、「LLMによる追加質問の生成」と「リランキング」の手順が加わっています。(※1、2)その効果のほどは、次項で詳しくみていきましょう!
なお、RAGの基本「Embedding」について詳しく知りたい方は、下記の記事をあわせてお読みください。

従来型RAG比でのRAG Fusionの長所
ユーザーの質問のみで検索を行っていた従来型RAGと異なり、RAG Fusionは「ユーザーの質問+LLMによる追加質問」でベクトルデータベースを検索します。そんなRAG Fusionには……
専門分野でも、深い回答が得られる:質問の不足箇所を追加質問で補うため
質問ミスがフォローできる:質問中のあいまいな表現やタイプミスを追加質問で補うため
といった長所があります。つまりは従来比で、より正確かつ包括的な回答が得られるということです。


RAG Fusionの短所
RAGの進化形・RAG Fusionも完璧ではありません。一度、「LLMに追加質問を生成させる工程」がはさまるため……
● 従来型RAG比で、トークン数の消費が増える
● 従来型RAG比で、回答速度が落ちる
● 意図から外れた回答や冗長な回答が返ってくることもある
という短所があるんです。
さて次項からは実際にPythonを使って、このRAG Fusionの効果を検証していきます。AIチャットボットの自社開発を目指すエンジニアのみなさんはぜひ、続きをご覧ください!
なお、トークン数を節約するテクニックについて詳しく知りたい方は、下記の記事をあわせてお読みください。

PythonでのRAG Fusion実践編
ここからは、Google Colaboratory(Google Colab)とPythonを駆使して、RAG Fusionの効果を検証していきます。その処理の流れは……
今回作るRAG Fusion(by Langchain)
- ユーザーがオリジナルの質問を入力
- GPT-3.5が質問に関連する新たな質問を複数生成
- オリジナルの質問・追加質問それぞれで、Pineconeのベクトルデータベースから事実を検索
- 複数の質問で得られた検索結果をまとめて順位付け
- 上位の検索結果をプロンプト経由でGPT-3.5に提示
- GPT-3.5が事実を踏まえた回答を生成
というふうになっています。以下、途中経過のスクリーンショットや使用したソースコードも掲載しておりますので、エンジニアのみなさんは必見です!
RAG Fusionに使用した環境・準備物
RAG Fusionの実践にあたって、今回使用した環境・準備物は以下の4点です。
● Python 3(Python 3.7.1以上)
● OpenAI Pythonライブラリ(openai)
● ChatGPTの有料アカウント
● Pineconeのアカウント(無料版も可)
あわせてPythonコードを実行するための場として、
- Google Colaboratory(Google Colab)
- Visual Studio Code
- Jupyter Notebook
以上のいずれかがあると、RAG Fusionが簡単に試せます。こちらについてはGoogle Colabを使用しました。
Pythonライブラリの用意
RAG Fusionを構築するにあたっては、LLMとベクトルデータベース、そして両者をつなぐフレームワークが必須。今回は……
- LLM:GPT-3.5
- ベクトルデータベース:Pinecone
- 連結用のフレームワーク:Langchain
を、以下のソースコードを使って用意しました。
#ライブラリインストール
!pip install openai langchain chromadb tiktoken langchain-pinecone langchain-openai langchainhubこちらのコードをGoogle Colabで実行すると……
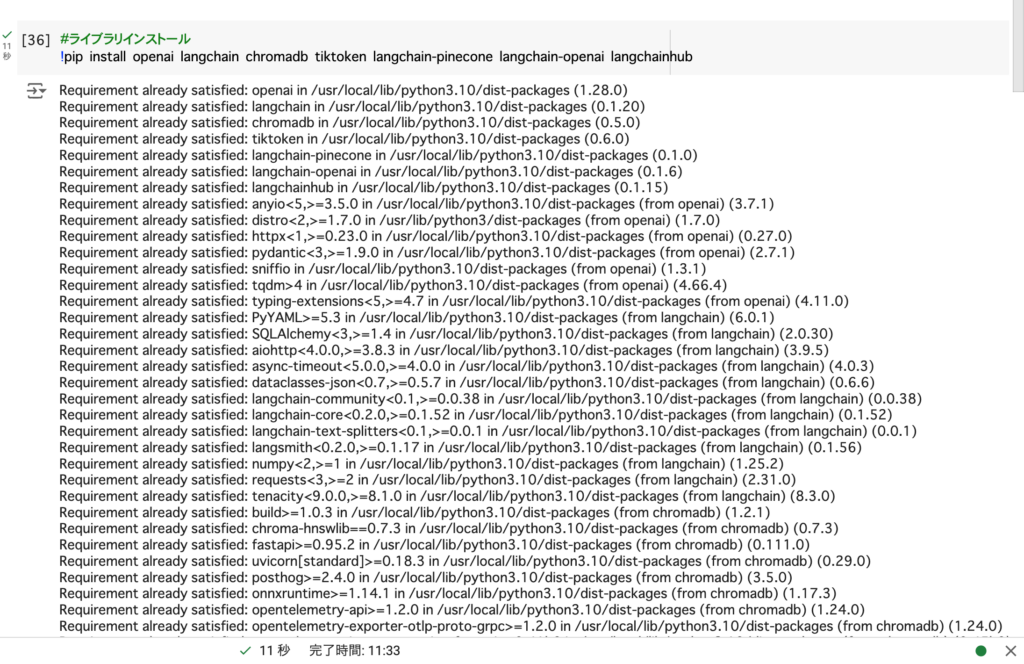
以上のとおり、必要なPythonライブラリがインストールされます。
APIとモジュールの下準備
続けてChatGPT APIとPineconeのそれぞれで、APIキーを発行して実行環境に反映します。
まず、PineconeのAPIキーについては、Pinecone Consoleから発行できます。同時に、後で使用するインデックスについても……
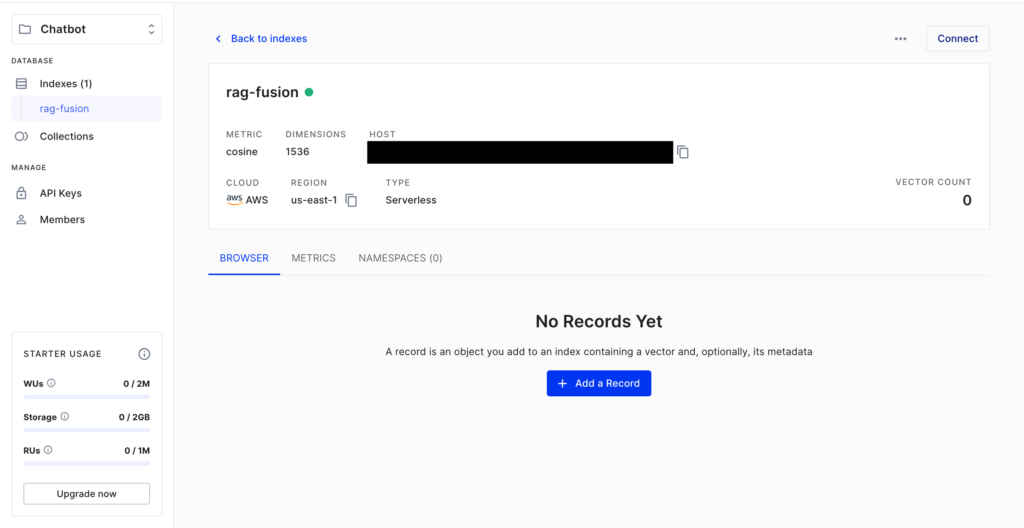
- インデックス名:rag-fusion
- 次元数:1536
という条件で作成しておきましょう。
次にChatGPT APIに関しては、こちらのAPIキー作成画面から発行が可能。それぞれ発行後は、以下のコードにペーストしてください。(※3)
#APIキー入力
import os
os.environ["OPENAI_API_KEY"] = "ChatGPT APIのAPIキー"
os.environ["PINECONE_API_KEY"] = "PineconeconeのAPIキー"あわせてRAG Fusionに使用するモジュールも、以下のコードを使ってインポートします。
#モジュールインポート
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain_pinecone import PineconeVectorStore
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate
from langchain.prompts.chat import (
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)以上2つのコードをそれぞれGoogle Colabで実行すると……
というふうに、APIとモジュールの準備が完了します。
記事の分割とエンベディング
ここからは、RAG Fusionの組み立て作業に移ります。
まずはRAG Fusionで示したい知識を用意する工程から、なのですが……
今回は当メディアの生成AIずかん全記事をスクレイピングして、テキストファイル「WEEL_Zenkiji.txt」にまとめました。まとめたテキストファイルは……
このように、ディレクトリ「sample_data」に収めています。
続けて生成AIずかん全記事を……
- チャンクに分ける(長文を細切れにする)
- Embeddingする(ベクトルに変換する)
- Pineconeのインデックスに格納する(先ほどのrag-fusionを使用)
という手順で加工して、ベクトルデータベースを作成します。うち、チャンク分けとEmbeddingについては……
%cd sample_data
#テキストをチャンクに分けて埋め込む
loader = TextLoader("WEEL_Zenkiji.txt",encoding="utf-8")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(disallowed_special=())こちらのコードで可能。(※4、5)実行すると……
このように記事全文が加工されます。
続けて、加工した記事全文を……
index_name = "rag-fusion"
vectorstore = PineconeVectorStore.from_documents(docs, embeddings, index_name=index_name)以上のコードで、先ほどのPineconeインデックス「rag-fusion」へ格納します。実行すると……

このように、生成AIずかん全記事を格納したベクトルデータベースが完成しました。
Chainの作成
最後に……
- GPT-3.5で追加質問を生成する工程
- 得られた複数の検索結果に順位をつける工程
- 上位の検索結果をもとにGPT-3.5に回答させる工程
をコーディングして、RAG Fusionを完成させます。今回は各工程を一連で実行できるLangchainの機能「Chain」を活用して、下記のコードを用意しました。(※4、5)
#複数クエリの生成
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain import hub
prompt = hub.pull("langchain-ai/rag-fusion-query-generation")
generate_queries = (
prompt | ChatOpenAI(temperature=0) | StrOutputParser() | (lambda x: x.split("\n"))
)
#関連度の高い順にドキュメントを返すようにする
from langchain.load import dumps, loads
def reciprocal_rank_fusion(results: list[list], k=60):
fused_scores = {}
for docs in results:
for rank, doc in enumerate(docs):
doc_str = dumps(doc)
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
previous_score = fused_scores[doc_str]
fused_scores[doc_str] += 1 / (rank + k)
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
return reranked_results
# 10個の関連文書を取ってくるようにする
retriever = vectorstore.as_retriever(search_kwargs={'k': 10})
#関連する質問を生成させるためのプロンプト
template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.
{context}
Question: {question}
"""
prompt2 = ChatPromptTemplate.from_messages(
[
HumanMessagePromptTemplate.from_template(template),
AIMessagePromptTemplate.from_template(""),
]
)
retrieve_chain = (
{"original_query": lambda x: x}
| generate_queries
| retriever.map()
| reciprocal_rank_fusion
)
chain = (
{
"context": retrieve_chain,
"question": lambda x: x,
}
| prompt2
| ChatOpenAI(temperature=0)
| StrOutputParser()
)こちらをGoogle Colabで実行すると……
以上のとおり、RAG Fusionの流れが完成しました。ではさっそく、次項からRAG Fusionの効果を試していきましょう!
RAG Fusionの効果検証
LangChainで構築したRAG Fusionを使ってGPT-3.5に質問する際は……
for s in chain.stream("任意の質問"):
print(s, end="", flush=True)以上のコードを実行するだけでOK。まずは下記の質問について、RAG Fusion経由でGPT-3.5から回答を得てみましょう!
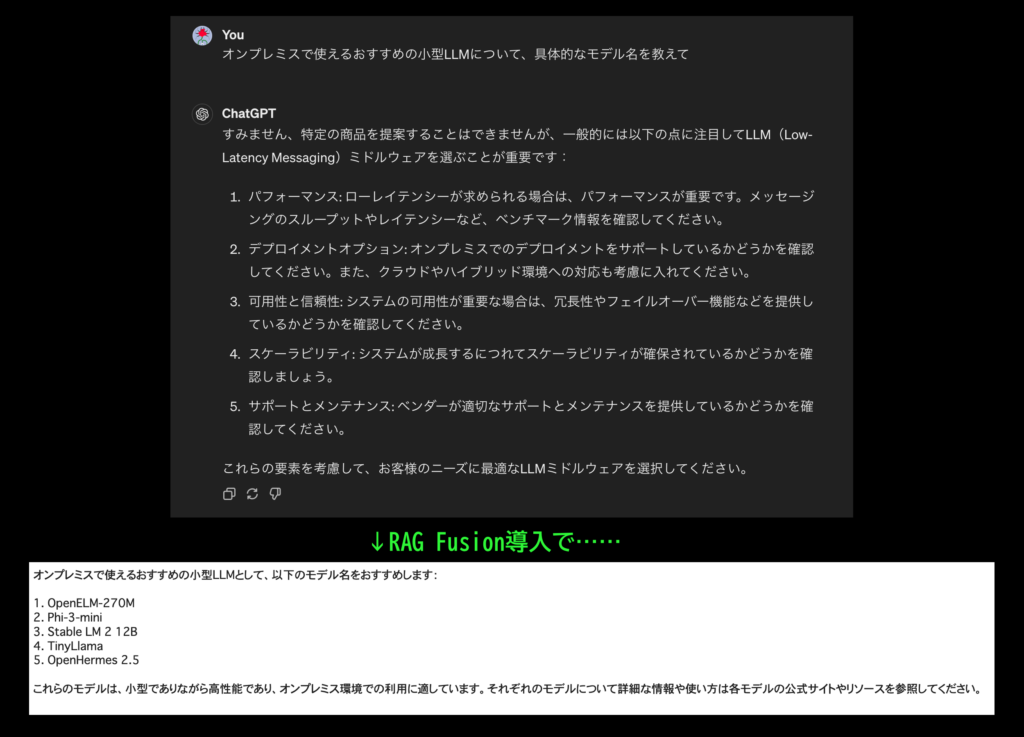
オンプレミスで使えるおすすめの小型LLMについて、具体的なモデル名を教えて

するとこのように、学習範囲外の具体的なツール名(2021年9月以降登場)が回答に反映されています。従来型RAGの回答と比較してみると……
RAG Fusionでの回答
オンプレミスで使えるおすすめの小型LLMとして、以下のモデル名をおすすめします:
OpenELM-270M
Phi-3-mini
Stable LM 2 12B
TinyLlama
OpenHermes 2.5
これらのモデルは、小型でありながら高性能であり、オンプレミス環境での利用に適しています。それぞれのモデルについて詳細な情報や使い方は各モデルの公式サイトやリソースを参照してください。従来型RAGでの回答
申し訳ありませんが、具体的なモデル名については情報が得られませんでした。お探しの情報を提供できず申し訳ありません。以上のとおり、違いは一目瞭然。RAG Fusionは元記事に一句もない表現「オンプレミス」を理解して、具体的なツール名を引用してくれているんです!
ちなみに以下の質問についても、RAG Fusionと従来型RAGでGPT-3.5の回答を比較してみると……
GPT-4を無料で使えるツールって知ってる?日本語で教えて。RAG Fusionでの回答
GPT-4を無料で利用できるツールとして、GPT EngineerとGPT4FREEが挙げられます。GPT Engineerはオープンソースであり、誰でも無料で利用することができます。具体的な使い方として、まずgptengineer.appにアクセスし、登録を完了させることで、テキストボックスにアプリの説明を入力し、「Create」をクリックすることでアプリを開発することができます。また、ChatGPTを利用したい場合は、GPT EngineerのGPTsを利用することができます。ただし、ChatGPTの有料ユーザー向けであることに留意してください。もう一つの無料ツールであるGPT4FREEは、GPT-4などの言語モデルにアクセスを提供するプロジェクトです。テキスト生成、チャットボット作成、言語生成、翻訳、コード支援など、多様な用途で利用可能であり、Pythonパッケージを介してインストールすることができます。ただし、GPT4FREEはアクセス制御と利用規約を回避することにより、倫理的及び法的問題が議論されている点に留意する必要があります。
これらのツールを利用することで、GPT-4を無料で活用することが可能です。ただし、利用する際には各ツールの利用規約や倫理的な観点に留意することが重要です。
従来型RAGでの回答
はい、GPT-4を無料で使えるツールにはGPT4FREEやGPT Engineerなどがあります。これらはオープンソースのプロジェクトで、テキスト生成やチャットボット作成など多様な用途で利用可能です。ただし、正規のGPT-4を利用するよりも安全性が低いため、利用には注意が必要です。このようにRAG Fusionのほうで、より具体的な回答が返ってきています。
なお、従来型RAGのPythonコードについて詳しく知りたい方は、下記の記事をあわせてお読みください。

そもそもLLM(大規模言語モデル)とはなにか
LLM(大規模言語モデル)は、人工知能技術の進歩がもたらした言語処理の革命的な進展を象徴するものです。Large Language Modelの略称であるLLMは、日本語では「大規模言語モデル」と訳され、膨大なテキストデータを学習して高度な言語理解と生成能力を獲得したAIシステムを指します。
これらのモデルは、インターネット上の膨大な文章を学習材料として活用し、複雑な文脈を理解し自然な文章を生成する能力を持っています。ChatGPTの進化は世間を驚かせましたね。その影には膨大な学習データを得た背景があったのです。LLMの特筆すべき点は、質問応答、要約、翻訳など、多岐にわたる言語タスクに柔軟に対応できることにあるでしょう。
技術的には、深層学習を駆使して、文脈に基づいて次に来る可能性が高い単語を確率的に予測するアプローチを採用しています。ChatGPTのように対話AIが実現し、人間らしい自然な会話ができることはまさにLLMの恩恵といえますね。
LLMには課題がまだまだある
そんなLLMですが、その利用には慎重なアプローチが求められています。高度な文章生成能力を持つLLMですが、出力される情報の正確性には常に注意を払う必要があるためです。ChatGPTもバージョンアップに伴い正確性はアップしてきました。それでも、学習データに含まれる誤りやバイアスが結果に反映される可能性があるため、重要な情報については人間による確認が不可欠です。
また、LLMにはプロンプトインジェクションというリスクも存在します。特定の入力によって開発者の意図しない回答を引き出される可能性があるため、ビジネス利用の際にはこのリスクへの対策も重要となるでしょう。
LLMの学習データの偏りによるバイアスも考慮すべき点です。データが特定の文化や視点に偏っている場合、出力にもその影響が現れることも。グローバルに展開する資料や記事などは、見識に偏りがあれば国際問題に発展することもあるため特に注意が必要です。多様性や公平性の観点からLLMにはまだまだ重要な課題が存在するのです。
LLMの課題を克服する「RAG」とは
そんなLLMの課題ですが、いくつかはRAGという技術で克服できるため、生成AIのトレンドとなっています。
RAG(Retrieval Augmented Generation)は、最新の自然言語処理技術の一つで、日本語では「検索拡張生成」と呼ばれています。この技術は、従来のシステムと最新の生成AIモデルにおける長所を巧みに融合させたものといえるでしょう。
RAGの仕組みは、ユーザーからの質問やプロンプトに対して、まず外部のデータベースから関連する情報を検索・取得し適切な回答を生成するというものです。この方法により、RAGは常に最新の情報を反映した正確な回答を提供することが可能となったのです。
さらに、RAGの優れた点は、単に検索データを要約するだけでなく、取得した知識を処理・統合し自然な言葉で文脈を反映した説明を作成する能力を持っているところです。これにより、ユーザーとの自然なやり取りが可能となり、より人間らしい対話や説明を実現しました。
LLMとRAG(検索拡張生成)はどう違う?
LLMは学習データに含まれていない情報、例えば企業の内部規程や最新のニュース記事などについては適切に回答できないという限界がありました。例えばChatGPTの場合、GPT-3.5では誤情報をアウトプットする割合が多すぎて、明らかに正確性に難がありましたね。まさにこの課題をRAGが克服してくれます。
RAGの採用により、LLMは従来知識の範囲外だった情報についても回答できるようになりました。具体的には、企業固有の規則や直近の出来事など、LLMがもともと学習していない内容にも対応できるようになったのです。
この技術の仕組みは、人間が参考資料を見ながら回答するのに似ています。RAGは、ユーザーの質問に関連する情報を外部ソースから取得し、それをLLMに提供します。
そして、LLMは単なる情報の複製ではなく、与えられた情報の意味を理解し、それを基に適切な解答を生成する能力を持っているところも特筆すべき点です。そのため、RAGによって必要な情報が提供されれば、LLMはその内容を理解し、文脈に合わせて正確で意味のある回答を作成できるのです。
RAGはLLMの潜在能力を引き出す
LLMは社内データなどのクローズドな情報を扱えないため、時として間違った情報を提示する場合もあります。生成AIは時として、データベース上に存在しない情報をあたかも正解のように解答してしまうこともあるでしょう。そして誤った情報は、非常に大きな混乱を巻き起こすこともしばしば。RAGは、これらのLLMの短所を補完しつつその長所を最大限に活かすために開発された技術です。
あくまで正確な情報をデータベースに登録することで、LLMが間違った回答を提示するリスクを大幅に低減できます。
RAGを活用することで、データベースに登録された情報のみを使用して、LLMに文章や画像を生成させることも可能です。この機能は、例えば医療機関や学術研究など絶対的に情報の正確性を求められる環境での利用に適しているでしょう。
このアプローチにより、LLMの応用範囲が大きく広がり、より柔軟で実用的なAIシステムの構築が可能になったといえます。まさにRAGは、LLMの潜在能力を最大限に引き出す重要な技術といえるでしょう。
RAGの概要と種類

RAG(Retrieval-Augmented Generation)は、テキスト生成プロセスに外部情報の検索・取得を組み込む先進的な手法です。注目すべきは、従来の生成モデルとは異なり、RAGはリアルタイムで外部情報源にアクセスし、その情報を元に出力を生成できる点でしょう。これにより、より正確で状況に適した回答が可能となりました。
では、RAGは実際どのような種類があるのでしょうか。ここでは、LangChainで実装されている「Self-RAG」「Adaptive RAG」「CRAG」の3点を紹介します。
Self-RAG(Self-Retrieval-Augmented Generation)
Self-RAGの特徴
1. 自動検索機能:モデルが自律的に必要な情報を検索し、生成プロセスに活用します。
2. リアルタイム情報更新:最新のデータや状況に応じた情報を動的に取得し、生成に反映させます。
3. 高度な検索能力:モデルが自ら適切な検索クエリを生成し、関連情報を効果的に抽出します。
Self-RAGの利点は、まずユーザー入力の簡素化が挙げられます。事前に情報を提供する必要がなく、モデルが自動的に必要な情報を収集するため、ユーザーの手間が大幅に軽減できるでしょう。
そして、柔軟な対応も可能になります。常に最新の情報を参照するため、刻々と変化する状況にも適応できるのが特徴です。さらに、知識の拡張も重要な利点です。外部ソースから情報を取得することで、モデルの知識ベースにない情報も活用できるようになります。
Self-RAGの応用分野は幅広く、インテリジェントなカスタマーサポートシステム、動的なドキュメント生成、リアルタイムのニュース分析や解説など、様々な分野で活用されています。
Adaptive RAG(Adaptive Retrieval-Augmented Generation)
Adaptive RAGは、RAGのひとつの進化形です。検索と生成プロセスを動的に調整する先進的な技術といえるでしょう。
Adaptive RAGの特長
1. 動的な検索クエリ生成
– ユーザー入力とコンテクストに基づき、検索クエリを適応的に生成
– 関連性の高い情報を効率的に取得
2. 柔軟な生成プロセス
– 検索結果に応じて情報の生成方法を調整
– 結果が豊富な場合は詳細な生成、少ない場合は既存知識に基づく生成
3. 学習と最適化能力
– 経験を通じて最適な戦略を学習
– 時間とともにパフォーマンスが向上
4. コンテクスト適応
– ユーザーの意図や過去の対話を考慮
– 検索・生成戦略を継続的に調整
Adaptive RAGの活躍の場として、カスタマーサポートが挙げられます。的確な回答を動的に生成し、ユーザーの好みに合わせたパーソナライズドコンテンツを提供が可能です。
また、ニュースやドキュメントの更新において最新情報を反映できる点も注目です。この技術は、複雑なユーザーニーズに対応し、より関連性の高い出力を実現します。ビジネスシーンで活躍できる場がまだまだありそうです。
種類に応じて、とてもニーズの多い技術ですので、今後の発展に注視したいですね。これにより、AIによる情報処理の質が大幅に向上し、様々な分野での活用が期待されています。
CRAG(Corrective-Retrieval-Augmented Generation)
CRAGは、RAGの一種で、生成された出力の正確性と信頼性を向上させるための訂正・修正プロセスを組み込んだ技術です。
CRAGの特長
1. 訂正メカニズムの統合
– 生成テキストを外部データベースと照合
– 誤りを検出し、適切な情報で修正
2. フィードバックループ
– 初期生成結果が不正確な場合、再検索と修正を実施
– 最終出力の正確性を向上
3. エラーチェックと修正
– 一貫性や正確性を評価するアルゴリズムを搭載
– モデルによる自律的な誤りの修正
4. 信頼性の向上
– 正確で信頼できる情報提供が主目的
– 医療、法律、技術文書など重要分野での応用に期待
CRAGは、正確性を求められる医療分野での活躍が期待されています。医療分野での診断や治療情報の正確性を確保し、法律分野では法的文書の正確性を確認・訂正します。
また、教育分野では学習教材やテストの信頼性を向上させられる点において適性があるでしょう。この技術のメリットとしては、訂正プロセスによる情報の質向上、高い信頼性、誤情報リスクの軽減、自動訂正による効率的な正確情報の提供などが挙げられます。
正確性は、生成AIにとって重要な課題ですので、CRAGも今後のAIの発展を担う技術なのではないでしょうか。
RAG(Retrieval-Augmented Generation)とファインチューニングの違い
しかし、RAG(Retrieval-Augmented Generation)とファインチューニングの違いはあるのでしょうか。AIのパフォーマンスを向上させるという点では一緒ですが、実はアプローチが違います。
RAGは外部知識の検索とテキスト生成を組み合わせ、リアルタイムで最新情報を取り入れることで、迅速な情報提供が可能に。一方、ファインチューニングは特定のタスクや業界に特化したモデルを作成します。
特定のデータセットに焦点を当てて、モデルを再学習するスタイルが特長。さらに異なる点として、ファインチューニングは時間とコストがかかりますが、RAGは計算量とストレージの必要性を減らしてプロセスをスピードアップできる点は無視できません。
RAGは、外部の知識ベースやデータベースから情報を取得し、それを統合して応答を生成する手法です。この点も大きく違います。これにより、質問応答システムで正確かつ詳細な回答が可能となり、リアルタイムで最新情報を反映できるのです。
一方、ファインチューニングは既存のモデルの内部パラメーターを調整し、特定のタスクに最適化する手法です。そのため、追加のデータセットを用いて再学習することで、特定のニーズに応じた高精度なモデルを短期間で作成できますが、データの偏りや過学習のリスクもあります。あくまでファインチューニングは特定の業界やタスクに適したモデルを作成していくことが前提となります。
RAGの主な活用事例

RAGは様々な種類があり、各シーンで実装され、活用されています。そして今後もその活躍の場は増えていくことでしょう。ここではRAGの主な活用事例を種類ごとにご紹介します。
チャットボットと顧客サポートの自動化
- コールセンターや社内FAQシステム… RAGを活用して、外部データベースから製品情報やサービスガイドをリアルタイムで参照し、顧客の質問に即座に正確な回答を提供します。社内マニュアルや過去事例からの情報収集もできるため、実装することにより、迅速かつ的確な問題解決が可能となるでしょう。
- 顧客サポートの自動化…よくある質問に対して関連情報を検索し、適切な回答を生成します。そのため顧客の待ち時間を減らし、サポートの品質向上を実現。電話対応などマンパワーが必要な現場で活躍します。
マーケティング・市場調査の支援
- パーソナライズされた商品・サービスの提案… ユーザーの行動履歴や好みに基づき、外部データベースから関連情報を取得し、提案を実現します。よりパーソナライズされた回答は顧客満足度に直結するでしょう。
- 最新トレンドの反映… ECサイトやSNS運用で、最新情報を組み込んで運用できます。トレンドに敏感なユーザーの期待に応えられます。
大学や研究機関での情報収集と分析の効率化
- 論文検索と要約の自動生成…RAGを実装して効率的な情報収集と研究品質の向上を実現。情報の正確性が求められる分野で、外部文献を的確に抜粋します。
メーカー業界での活用
- 生産計画の最適化…大規模データセットを解析し、需要予測、在庫管理、工程管理の精度を向上します。
- 異常検知システム…センサーから取得したデータをリアルタイムに解析し、異常を即座に特定。緊急性の高い現場でこそ活躍します。
在庫管理の効率化
- 正確な需要予測と自動発注…過去の販売トレンドや季節性を考慮し、在庫管理を最適化。自動発注システムと連携し、人的ミスの減少につながります。
- 在庫回転率の最適化…在庫回転率をリアルタイムで監視し、不必要な在庫を削減します。
専門分野での情報検索と分析
- 法律や医学などの分野での支援…最新の研究結果やケーススタディから関連情報を検索し、専門家の意思決定を支援します。研究や診断の精度向上につながります。
ここではRAGの主な活用事例をタイプ別にご紹介しました。現状でも既に実装されている環境もありますが、今後はますます発展していくでしょう。業務を効率化するために生成AIの活用を考えている方も、RAGは避けては通れない技術ですので注目しておいて損はありません。
なお、RAGの導入事例について詳しく知りたい方は、下記の記事を合わせてご確認ください。

RAG Fusionなら深い回答が得られる!
当記事ではRAGの進化版「RAG Fusion」について解説を行いました。RAGと比べたときのRAG Fusionの強みは……
専門分野でも、深い回答が得られる:質問の不足箇所を追加質問で補うため
質問ミスがフォローできる:質問中のあいまいな表現やタイプミスを追加質問で補うため
以上のとおり。実践編でも、引用元にない「オンプレミス」の意味まで踏まえた回答が返ってきていました。チャットボットで高度な知識を扱いたい場合はぜひ、このRAG Fusionをお試しください!


最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

