
【情シス必見】ChatGPTに自社データを学習させる方法やプロンプトを悩み別に紹介

あなたは、ChatGPTを使って、自社専用のChatGPTを作る方法を知っていますか?
まさか、未学習のChatGPTをそのまま使用していませんよね?
ChatGPTをカスタマイズする方法について述べた以下のスライドは、すでに2万回以上も閲覧されています。
ChatGPT_APIのEmbedding_カスタマイズ入門 – Speaker Deck
この反響からわかるように、多くの企業が自社データの追加学習に関心を持っています。自社サービスを柔軟に拡張できるのですから、使わない手はありませんよね。
本記事では、「ChatGPTに自社データを学習させ、自社専用のChatGPTを作る方法」について解説します。最後まで読んだ方は、ChatGPTにおける自社データの効果的な活用方法をマスターし、生成AIに潜むデメリットを克服した上で社内で活用できるようになります。ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
そもそもChatGPTの学習データはどこから集めたものか
自社データをChatGPTに取り込む前に、そもそもChatGPTが回答するのに必要な学習データはどこから集めたものかご存じでしょうか。
未学習のChatGPTが学習するデータは、ウェブページや書籍、ニュース記事などのインターネット上で公開されている大量の情報です。インターネット上の情報は全てが正しいとは限りません。そのため、ChatGPTの回答精度はバラついてしまうのです。
ChatGPTに本当に回答してもらいたいのであれば、インターネット上の情報を学習させるのではなく、必要な情報を学習させる必要があります。そのために一番よいのは自社データを学習させることです。
次の章からChatGPTに自社データを学習させる方法を紹介していきますので、ぜひ最後までお読みいただき、業務効率を図ってみてください。
既存のChatGPTが学習したデータと限界
前述したように、ChatGPTのような大規模言語モデルはインターネット上に公開されているテキストデータを学習しています。
具体的には、以下のような情報が主な学習源となります。
- ウェブページ: 多種多様なウェブサイトのテキスト
- 書籍: デジタル化された書籍データ
- ニュース記事: さまざまなメディアのニュース記事
- 百科事典: Wikipediaのような包括的な知識ベース
- 論文: 学術論文や技術文書
これらのデータは、ChatGPTが幅広い知識を身につける上で非常に重要です。しかし、インターネット上の情報は玉石混交であり、常に正しいとは限りません。そのため、ChatGPTの回答には以下のような限界があることを理解しておく必要があります。
- 情報の正確性のバラつき(ハルシネーションのリスク):学習データに誤った情報や偏った情報が含まれている場合、ChatGPTもそれを学習し、事実とは異なる「ハルシネーション」を生成してしまう
- 最新情報の欠如:ChatGPTが持つ情報は一定の時点のもの。リアルタイムには対応できません。
- 企業固有の知識の欠如:インターネット上の公開情報だけでは、特定の企業が持つ社内規定、独自の製品情報、顧客データ、営業ノウハウなど、機密性の高い専門的な知識は学習できません。
これらの限界があるため、ChatGPTに本当に「自社に役立つ」回答を求めるのであれば、インターネット上の一般的な知識だけでなく、企業特有の情報を学習させる必要があります。
【悩み別】ChatGPTに自社データを学習させる方法

ChatGPTを活用するうえで、さまざまな問題点・悩みがあります。代表的な問題点・悩みと、その対策である「ChatGPTの学習方法」を以下の表にまとめました。
| 悩み | ChatGPTの学習方法 |
|---|---|
| 情報漏洩のリスクが気になる | OpenAI APIを利用する |
| 虚偽情報の生成(ハルシネーション)がされないようにしたい | エンベディング(Embedding) |
| できるだけ自社データを優先させて回答を生成したい | エンベディング(Embedding) |
| 回答生成で利用した自社データを把握したい | エンベディング(Embedding) |
| コストをかけずに学習させたい | プロンプトデザイン |
| 業務特化ではなく、業界に関する一般的な知識を向上させたい | ファインチューニング(Fine-tuning) |
これから、上記の問題点・悩みについて、具体的に解説します。


情報漏洩のリスクが気になる
ChatGPTに文章データを入力する際には、情報漏洩のリスクに関して細心の注意を払う必要があります。なぜなら、ChatGPTで入力した内容は、生成AIの学習に利用される可能性があるからです。
情報漏洩の対策としては、ChatGPTのAPIを利用しましょう。OpenAI社によると、API経由のデータは、ChatGPTの学習には利用されず、情報漏洩のリスクを低減できます。しかし、ChatGPTの利用に、APIを経由する場合は、次の2点に注意する必要があります。
- APIの利用料金
- APIを利用するためのシステムや機能の考慮
まずは、APIの利用料金についてです。APIの利用料金は、入力した文字数に応じて金額が決まります。例えば、「o4-mini」というAPIの種類の場合、100万トークンごとに1.100ドルが必要です。このトークン数は、言語によってカウントの仕方が違います。日本語で入力した場合のトークン数は次のようになっています。※1
- ひらがな1文字:1トークン
- 漢字1文字:2~3トークン
次にAPIを利用するためのシステムや機能を考慮する必要性について解説します。結論から言うと、APIを使用する際もセキュリティ対策が必要です。
APIを利用する際に適切なセキュリティ対策をすることで、情報漏洩リスクを低減できます。安易にAPIを信用せず、情報漏洩を防ぐための対策をしましょう。
虚偽情報の生成(ハルシネーション)がされないようにしたい
ハルシネーションとは、生成AIが実際のデータと異なる情報を生成することです。簡単に言うと、嘘の情報を生成することを指しています。これは、主に文章の生成などにおいて問題になるケースが多く、正確で意味のある出力をせず、誤った情報拡散の要因となります。
ハルシネーションの原因は、主に以下の3つです。
- 文脈内での正しさを重視するあまり誤った情報を生成してしまう
- 古い情報を参照することで、現在では通用しない情報を生成してしまう
- 学習データが不足しており、推測した情報を生成するが、それが誤りである
ハルシネーションに対する対策方法としては、エンベディングを行うことが有効です。エンベディングとは、独自のデータをChatGPTに教え込む学習方法です。
エンベディングによって、独自のデータから質問に最も関連する情報を検索し、回答に利用できます。この方法により、回答生成時に正しいデータを参照するので、ハルシネーションが起きにくくなるのです。
できるだけ自社データを優先させて回答を生成したい
新たに学習させた自社データを優先させて、ChatGPTに回答させたいと思っている企業も多いでしょう。しかし、自社データを利用して回答を生成する場合は、ChatGPTをそのまま使うだけではダメです。
なぜなら、ChatGPTはネット上などにある大量の文章データを学習し、自然言語を生成しているからです。そのため、自社データを優先して回答させるためには、特殊な処理が必要になります。
自社データを優先させてChatGPTに出力させる場合は、先ほどご紹介したエンベディングを弊社は推奨しています。
この時、「ファインチューニングじゃダメなの?」という疑問があるかと思います。結論としては、エンベディングの方が、より自社データに即した正確な出力が可能になるので、ファインチューニングよりもおすすめです。
ファインチューニングは、LLM自体に追加で数千件ほどの文章データを学習させるため、どの情報から回答を生成したのか分からなくなります。そのため、自社データではなく、事前学習の段階で得ていた情報から回答を生成する可能性が出てきます。
しかし、エンベディングを利用することで、より自社データに即した正確な回答を生成できるようになるのです。
回答生成で利用した自社データを把握したい
実業務で利用するためには、同じ精度の答えを常に出力しなければならず、回答の再現性が重要になります。例えば、カスタマーボットが同じ質問のたびに、違う回答を出してきたら困りますよね。
回答精度の再現性を高めるためには、回答生成時に利用するデータを把握し調整する必要があります。この場合は、エンべディングが有効です。エンベディングは、回答生成時に自社データを参照するので、参考にしたデータを確認でき調整も可能です。
ただし、エンベディングには、Pythonの知識とLangchainと呼ばれる生成系AIに特化したモジュールの理解が必要になります。エンべディングを活用する際は、注意してください。
コストをかけずに学習させたい
ここまでは、ChatGPTに自社データを学習させる上で発生する問題の解決策として、エンベディングやファインチューニングをご紹介しました。確かに2つとも有用な技術です。
しかし、ファインチューニングもエンベディングも、プログラミングやAIの知識が必要です。もし、そのノウハウがなければ、開発を外注しなければいけなくなり、費用が発生してしまいます。そこで、費用をかけずに解決する方法としてプロンプトエンジニアリングがあります。
プロンプトエンジニアリングとは、ChatGPTにわかりやすい質問の仕方をして、回答を求める方法です。質問をする際、OpenAIのAPIを利用しなければ自社データがChatGPTの学習に利用されます。APIを利用せず個人情報や機密情報を入力すると、情報漏洩にもつながるので注意してください。
業務特化ではなく、業界に関する一般的な知識を向上させたい
自社の業務特化ではなく、自社の業界に関する一般的な知識を向上させたい場合は、ファインチューニングが効果的です。例えば、アパレル業界で服の種類や素材など一般的な知識を身につけたチャットボットを開発したい時などです。
特定のデータを学習させる際はエンべディングを使用することも多いです。しかし、エンべディングは自社に特化したより詳細な情報を学習させることに長けています。そのため、業界の知識を学習させる際は、ファインチューニングを使用しましょう。
なお、ファインチューニングについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

ChatGPTに自社データを学習させる方法一覧

ここでは、ChatGPTに自社データを学習させる方法について、その詳細内容を解説します。ChatGPTに自社データを学習させる方法を、以下に表でまとめました。
| 学習方法 | 概要 |
|---|---|
| OpenAI API | APIを介してOpenAIのモデルを利用し、AI関連のタスクを解く手法 |
| プロンプトデザイン | 「ChatGPTに工夫して質問文を投げかける」という手法 |
| ファインチューニング | 「大量のデータで事前学習されたLLMに対して、解きたいタスクに応じてデータを追加で学習させる」という手法 |
| ベクトルデータベース | データをベクトル化して、管理するデータベースシステム |
| エンべディング | ベクトルデータベースと連携して、特定の情報や知識をプロンプトに組み込む手法 |
OpenAI API
OpenAI APIは、OpenAIのモデルを利用するためのAPIです。これを使用すると、自然言語処理タスクや他のAI関連のタスクを実行するために、OpenAIのモデルを利用できます。OpenAI APIを利用すれば、ChatGPT を使用して、テキスト生成や文章要約、質問応答、言語翻訳などの自然言語処理タスクも実行可能です。
また、APIを経由することで自社データは学習されず、情報漏洩のリスクが低減できます。ただし、利用するAPIによっては利用料金が発生する場合もあるため、注意してください。
プロンプトデザイン
プロンプトデザインとは、プロンプトエンジニアリングとも呼ばれ、「ChatGPTにわかりやすく質問文を投げかける」という手法です。質問する文章のことを「プロンプト」といい、このプロンプトをわかりやすく書くことで、ChatGPTの回答精度が向上します。
例えば「○○についてのブログ記事を書いてください」とプロンプトを書くよりも……
「あなたはプロのライターです。○○についてのブログ記事を1000文字程度で書いてください。ターゲット読者は20代男性無職です。」
というふうに、より詳しく書くことで、回答の精度が向上します。プロンプトデザインには、他にもさまざまなテクニックがあります。「深津式」や「シュンスケ式」など、多様な種類のテクニックがあるので、ぜひ試してみてください。
ファインチューニング
ファインチューニングとは、「大量のデータで事前学習されたLLMに対して、解きたいタスクに応じてデータを追加で学習させる」という手法です。ファインチューニングをするためには、一般的には数百〜数千件ほどのデータを用意する必要があります。この数が多いか少ないかは、企業にもよると思いますが、自社データの少ない企業にとっては「集められない」という場合もあるでしょう。また、ファインチューニングは、プログラミングのスキルやAIの知識を要するため、気軽には取り組めません。
ベクトルデータベース
ベクトルデータベースとは、データをベクトル化して、保存や管理するデータベースシステムのことです。ベクトルデータベースを利用すれば、通常のデータベースよりも効率よくデータを格納し、処理ができます。特に、「データの類似度」を測ることが得意なデータベースです。この「データの類似度」を測る技術を用いることで、次にご紹介するエンベディングにも応用できます。
エンべディング
本来、エンベディングとは「単語や文章のデータなどを、ベクトルに変換する手法」のことを指します。ChatGPTにおけるエンベディング手法では、特定の情報や知識をプロンプトに組み込む手法を指します。具体的には、ChatGPTに対して、特定の情報をプロンプトに加えて質問し、その情報を基に適切な回答をさせる方法です。
そのために、あらかじめ自社データをベクトル化してベクトルデータベースに格納しておき、以下の手順でプロンプトに特定の情報を組み込みます。
- ChatGPTに投げかけたプロンプト文をベクトル化
- ベクトルデータベース内で最も関連のあるデータを引っ張ってくる
- そのデータ(文章)を、元のプロンプトに加える
上記の手順ですれば、自社のデータをChatGPTのプロンプトに組み込めます。


ChatGPTに独自データ学習をさせるため3つのデータ
これから、ChatGPTに学習させるデータについて紹介します。ChatGPTに学習させるデータは、CSVやPDF、URLといったデータがあります。それぞれのデータの特徴を紹介していますので、ぜひ参考にしてください!
CSVファイル
CSVファイルを使用することで、ChatGPTは自社の独自データを効率的に学習できます。CSVファイルは、データをコンマで区切ったテキストファイルで、ExcelやGoogleスプレッドシートなどの一般的なソフトウェアで利用されます。このフォーマットは、異なるプログラム間で情報を共有する際に便利です。
ChatGPTにCSVファイルを読み込ませることで、自社固有の情報をAIに学習させ、精度の高い回答を得ることが可能になります。
PDFファイル
ChatGPTのGPTs(AskYourPDF Research Assistant)を使用することで、PDFファイルから直接データを読み込むことが可能です。このプラグインにより、ユーザーは大量のテキストをコピー&ペーストする手間を省くことができ、PDFファイルから質問と回答を生成できるようになります。この方法は、特に大量の文書や報告書を扱う際に有効で、ChatGPTが提供する精度の高い回答を得るための効率的な手段です。
URL
ChatGPTのプラグイン(WebPilot)を使用することで、与えられたリンクから情報を学習させることができます。この方法のメリットは、自社のウェブサイトやオンラインの資料から直接データを取り込むことが可能になる点です。そのため、ChatGPTは自社に特化した情報を基に、精度の高い回答ができます。
また、URLを読み込むことで最新の情報を常に取り入れられるため、AIの回答が時代遅れになるリスクを軽減できます。
なお、生成AIで自動化する方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

近年、注目されているAIによる自動化。AI自動化で業務効率化をしたいと検討している企業様には必見の記事になっています。
続きを読む
ChatGPTに自社データを学習させる最適な手法の選び方
ChatGPTをビジネスに導入する際、多くの企業が共通の課題や悩みを抱えています。例えば、「情報漏洩が怖い」「嘘の情報を出してほしくない」「とにかくコストを抑えたい」といった具体的なニーズがあるでしょう。
それぞれの課題には、課題に適したChatGPTの学習方法や活用アプローチがあります。ここでは、代表的な課題と、それを解決するための具体的な手法について、詳しく解説します。
ハルシネーションを抑え、自社データを優先したい場合:RAG (Retrieval-Augmented Generation)
「ChatGPTが最もらしい嘘をつくのは困る」「会社のデータに基づいて回答してほしい」「回答の根拠となった情報が何なのか知りたい」
上記を解決するためには、RAG(Retrieval-Augmented Generation:検索拡張生成) が最適。
既存のChatGPTは、学習した膨大な知識から最もらしい答えを生成しますが、その知識は特定の時点までのものであり、「本当に正しいか」「最新か」「自社固有の情報か」は保証されません。RAGは、この課題を根本的に解決する手法です。
RAG自体はそこまで構築するのが難しくなく、LINE botとして動かすこともできます。
情報漏洩・セキュリティリスクが気になる場合:API利用とセキュアな環境構築
ChatGPTを業務で活用する際に、最も懸念されるのが「情報漏洩」のリスクではないでしょうか。特に、機密情報や個人情報を含む自社データを扱う場合、その管理には細心の注意が必要です。
ChatGPTに情報を入力すると、その内容がモデルの学習データとして利用される可能性があり、これが情報漏洩のリスクにつながると指摘されています。しかし、このリスクを減らすための対策もあります。

ChatGPTの画面右上に「一時チャット」があります。こちらをクリックすることで、入力した情報は学習データとして使われなくなります。
また、OpenAIのAPIに関しては「デフォルトでは、ユーザーのビジネスデータを使用してモデルに学習させることはありません」と明記されています。
とはいえ、APIを利用するからといって、セキュリティ対策が不要になるわけではありません。APIを通じてデータが送受信される際の「通信経路」や、APIキーの「管理方法」など、企業側の責任で適切なセキュリティ対策を講じる必要があります。
既存モデルの知識をベースに、特定の業界・業務知識を深く習得させたい場合:ファインチューニング
ChatGPTは多種多様な知識を持っていますが、特定の業界用語や独自の表現、あるいは特定の形式での回答など、よりニッチで専門的なニーズに応えるには限界があります。このような場合に有効なのが「ファインチューニング(Fine-tuning)」。
ファインチューニングは、OpenAIが事前に学習させた事前学習モデルに対し、自社が用意した少量の追加データで再学習を行う手法です。これにより、モデルは自社特定のタスクやドメインに特化し、よりカスタマイズされた回答を生成できるようになります。
コストを抑えつつ、手軽に自社データに合わせた回答を生成したい場合:プロンプトエンジニアリング
「いきなり複雑なシステムを構築するのはハードルが高い」「まずは費用をかけずにChatGPTの可能性を探りたい」「手元にあるデータでサッと試したい」
このような場合、最も手軽でコスト効率の良い方法が「プロンプトエンジニアリング(In-context Learning)」です。
プロンプトエンジニアリングとは、簡単に言えば「ChatGPTへの質問や指示を工夫することで、より的確で望ましい回答を引き出す技術」です。モデル自体を学習させるわけではないため、費用はChatGPTのAPI利用料(または無料版の利用)のみで済み、開発コストを大幅に抑えられます。
ChatGPTに自社マニュアル(機密情報のない)を提示し、プロンプトを投げるだけで自社マニュアルを参照しながら回答してくれますので、最もコスパの良い方法です。
ChatGPTに自社データを学習させるメリット
ここでは、ChatGPTに自社データを学習させるメリットについて2つ紹介します。ChatGPTに学習させることで、専門的な回答や精度の高い回答を生成できるようになります。ぜひ、参考にしてみてください。
業界専門の回答ができる
ChatGPTに自社のデータを学習させると、業界固有の情報に基づいた専門的な回答が可能になります。自社独自のデータや業界特有の情報をChatGPTが学習することで、その分野に特化した知識を持つことができます。
例えば、自社製品に関する詳細な情報や業界の専門用語をChatGPTに学習させることで、顧客からの具体的な質問に対しても正確で専門的な回答をすることが可能です。したがって、ChatGPTに自社データを学習させることは、業界特有のニーズに応えるための重要な方法です。
精度の高い回答が可能になる
自社データをChatGPTに学習させることで、回答の精度が向上します。ChatGPTは、学習したデータを基に回答を生成するため、多くの情報を持つほど回答の質が高まります。
具体的には、自社の過去の取引履歴や顧客データなどをChatGPTに学習させることで、顧客の問い合わせに対して適切で詳細な回答が可能です。ChatGPTに自社データを学習させることは、顧客サポートの質を高めるための効果的な手段です。
ChatGPTに自社データを学習させるデメリット
次は、ChatGPTに自社データを学習させるデメリットを2つ紹介します。これから紹介するデメリットを知っておくことで、ChatGPTに自社データを学習させる際に「こんなはずじゃなかった」などと後悔することがなくなります。ぜひ、以下を参考にしてChatGPTに自社データを学習させるデメリットを理解してください!
ユーザーへの返答が遅くなる
ChatGPTに自社データを学習させると、回答スピードが低下する可能性があります。自社の独自情報を読み込むことで、ChatGPTが処理するデータ量が増加し、自然処理に必要な時間が長くなるためです。情報量が多いChatGPTは、推論速度が低下し、ユーザーへの反応が遅れることがあります。そのため、自社データを学習させる際は、回答スピードの低下を考慮する必要があります。
個人情報や機密情報が漏れる可能性がある
ChatGPTに自社データを学習させる際に個人情報や機密情報の取り扱いに気をつけないと、外部へ流出してしまう可能性があります。対策としては主に以下の2つです。
- ChatGPT APIを利用:API経由で通信するため、ChatGPTに情報が残らない
- オプトアウトを設定:自分で入力した情報をChatGPTに学習させないようにする機能
情報漏洩を一度でも起こしてしまうと企業の信用が大きく落ちてしまい、今後の業務に支障が出てしまいます。必ず対策を講じたうえでChatGPTを活用するようにしましょう。
なお、ChatGPTを企業利用する際のリスクを詳しく以下の記事で解説しています。ぜひご覧ください。

コストがかかる可能性がある
ChatGPTに自社データを学習させると、実装にかかるコストが増加することがあります。独自情報を追加学習することは可能ですが、通常よりもコントロールが難しくなり、微調整が必要になるためです。
自社データを学習させて実装するまでに、作業時間が長期化し、エンジニアの人材確保によりコストが増加することがあります。そのため、自社データを学習させる際は、追加のコストを考慮する必要があります。
ChatGPTに自社データを学習させたらできること
ここでは、ChatGPTに自社データを学習させることで、可能になることを2つご紹介します。具体的な内容を紹介しますので、自社での活用イメージがわきやすいはずです。ぜひ最後までお読みください。
自社専用のAIチャットボット開発
ChatGPTに自社データを学習させることで、自社専用のAIチャットボットを開発できます。AIチャットボットには専門知識を学習させられます。例えばマーケターやエンジニア、コンサルタントなど、専門家を複数登場させることも可能です。
AIチャットボットを作成すれば、社内の質疑にかかる工数を減らすことができ、余剰時間を増やせるでしょう。弊社は、透明性を重要視しており、このAIチャットボット作成手法を一般公開しています。以下の記事からご覧ください。
【ChatGPTハーレム】Slackに専門家美女AIを大量召喚したら全員反応してウザすぎたので調教する #Python – Qiita
自律型AIエージェントの開発
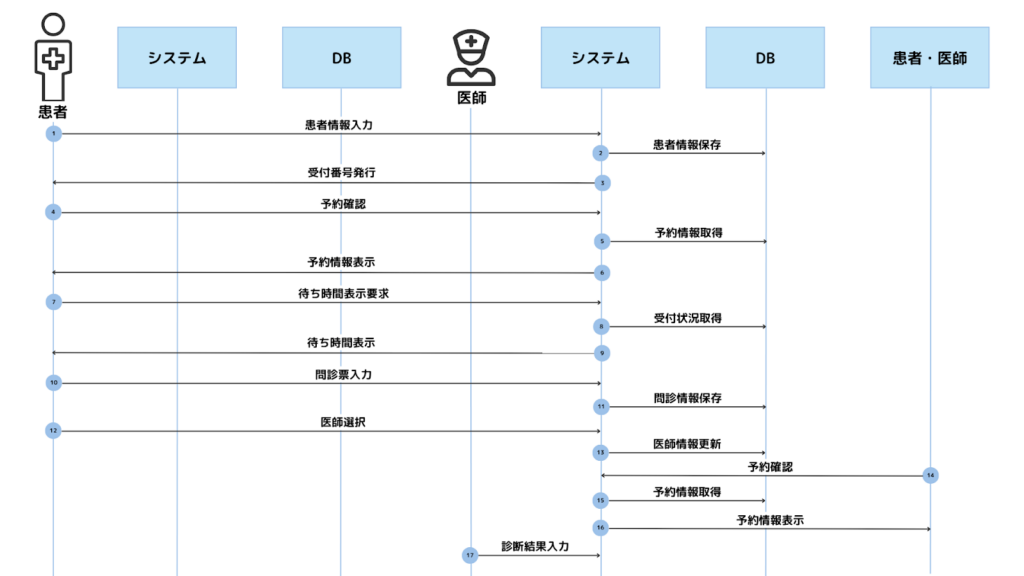
ChatGPTに自社データを学習させると、要件定義・業務フロー作成を80%自動化できる自立型AIエージェントの開発が可能になります。自律型AIエージェントを活用すれば、AIと対話をするだけで業務フロー図の作図やマニュアル作成、要件定義を半自動で行うことが可能です。そのため、全体の工数を(この例の場合)50%以上削減できるでしょう。
今後ITエンジニアが不足すると言われる中で、上流工程を担当する人は特に不足していくと思われます。IT業界の方や、社内DXを行う方にとって有用な事例になれば幸いです。
こちらがGPTが生成した業務フロー図になります。
ChatGPTに自社データを学習させよう
今回は、ChatGPTに自社データを学習させて、ChatGPT独自の課題を解決する方法について解説しました。各企業が持つ悩みに対する、自社データを活用したChatGPTの学習方法は、以下のようなものがあります。
| 悩み | ChatGPTの学習方法 |
|---|---|
| 情報漏洩のリスクが気になる | OpenAI APIを利用する |
| 虚偽情報の生成(ハルシネーション)がされないようにしたい | エンベディング |
| できるだけ自社データを優先させて回答を生成したい | エンベディング |
| 回答生成で利用した自社データを把握したい | エンベディング |
| コストをかけずに学習させたい | プロンプトデザイン |
これらの手法でChatGPTに自社データを学習させると、以下のようなシステムも作れます。
- 自社専用のAIチャットボット
- 自律型AIエージェント
自律型AIエージェントを開発すれば、AIや人からの命令に対して、理解・回答するだけでなく実行まで行わせることが可能になります。そうなれば、「記事のリサーチから執筆まで自動で行うAIライター」も作れるのです。

最後に
いかがだったでしょうか?
自社データを活用したAI導入で、業務効率や顧客対応の質が劇的に向上した企業が増えています。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。
※1:API料金


