
LLMのファインチューニング徹底解説!RAGとの違いや活用のコツをご紹介

WEELメディア事業部AIライターの2scです。
企業ITエンジニアのみなさん!LLMのファインチューニングを試されたことはありますか?
今後1兆3,000億ドル規模に達するとの予想もある生成AI市場では、ファインチューニングやRAGを活用したLLM系のAIツールが続々登場すると考えられます。
当記事では、そんな注目株「LLMのファインチューニング」について、メリット・デメリット・コツを徹底解説!完読いただくと、「意のままに動くAIツール」が開発できる……かもしれません。
ぜひぜひ、最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
LLMにおける「ファインチューニング」とは
「ファインチューニング」とは、事前トレーニング済みのAIモデルに微調整を加えて特定の処理能力を高めるプロセス全般のこと。AIモデルを新規開発するよりも安価かつ容易なため、AI分野で広く採択される手法です。
とりわけLLM(大規模言語モデル)の場合、このファインチューニングは質問と回答の例文集を学習させて回答を調整する工程を指します。ファインチューニングの効果としては、特定の質問に対して狙った文体・データ形式での回答が実現する、というものになります。
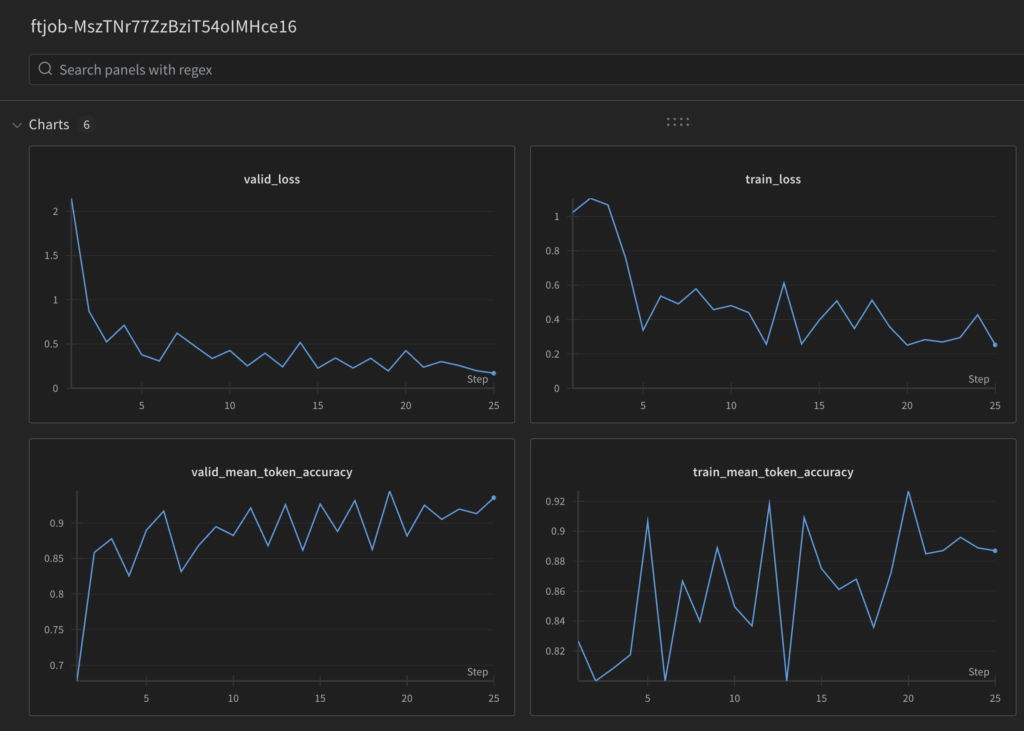
参考:https://platform.openai.com/docs/guides/fine-tuning/fine-tuning-integrations
そんなファインチューニングと同様にLLMの回答を調整できる「RAG ( Retrieval Augmented Generation)」という手法がありますが、こちらは全くの別物。下表のとおり、方法も効果も異なっています。
| ファインチューニング | RAG | |
|---|---|---|
| 具体的手法 | 質問&回答の例文集をLLMに学習させる →さしずめ「テスト勉強」のようなもの | 関係するデータを検索してプロンプトに加筆する →さしずめ「カンニング」のようなもの |
| LLMでの効果 | ・特定の口調・構造化データを含む回答が実現する ・特定の命令に対して、従いやすさが向上する | ・回答に学習範囲外の事実を反映できる |
| 代表的な用途 | ・キャラクターもののAIチャットボット ・プログラミング用のAIツール | ・AIチャットボット全般 ・ライティング用のAIツール |
当記事では、そんな「LLMにおけるファインチューニング」を徹底解説!RAGと比較しながら、そのメリット・デメリットを掘り下げていきます。


RAG比でのファインチューニングのメリット
まずは、RAGと比べたときのファインチューニングのメリットを3点ご紹介します。以下、処理速度・コストに影響する消費トークン数から、詳しくみていきましょう!
消費トークン数が少ない
RAGと比べて、ファインチューニングではLLMの消費トークン数が抑えられます。これはRAGで入力する内容がプロンプト+引用したデータであるのに対し、ファインチューニングの場合はプロンプトのみで完結するためです。実用面では「回答生成の速度の向上」や「質問毎でのコスト削減」といった効果が見込めるでしょう。
特徴・形式の反映に優れる
数個の事実を示すだけのRAGと違って、ファインチューニングでは数十〜数百の回答例を前もってLLMに提示します。そのため、下記に挙げたような抽象的な特徴・形式を回答に反映させることができます。
- 特定の口調(〜でござる、〜なのだ等)
- 特定のフォーマット(論文風、社内文書風等)
- 特定の構造化データ(JSON、SQL、カテゴリID等)
そんなファインチューニングは、「キャラクター性のあるAIチャットボット」や「特定のコマンドを返すAIツール」を開発したい場合に最適です。
複雑で難解なスキル・タスクも示せる
ファインチューニングでは、「1つのプロンプトに収まりきらないタスク」や「言語化できないスキル」までもLLMに反映できます。特定のタスク・スキルに特化したAIツールを開発する際に、活躍してくれるでしょう。
なお、GPT-4oのファインチューニングについて詳しく知りたい方は下記の記事もあわせてご確認ください。

RAG比でのファインチューニングのデメリット
ここまででご紹介した内容の反面、ファインチューニングよりもRAGのほうが最適な場面も多々あります。以下、そんなRAG比でのファインチューニングのデメリットも3点ご紹介。まずは、最も致命的な弱点からご覧ください!
事実性の担保に適さない
RAGとは対照的に、ファインチューニングでは「回答の事実性」が担保できません。これは、両者でLLMに示す内容が違っていることに起因します。
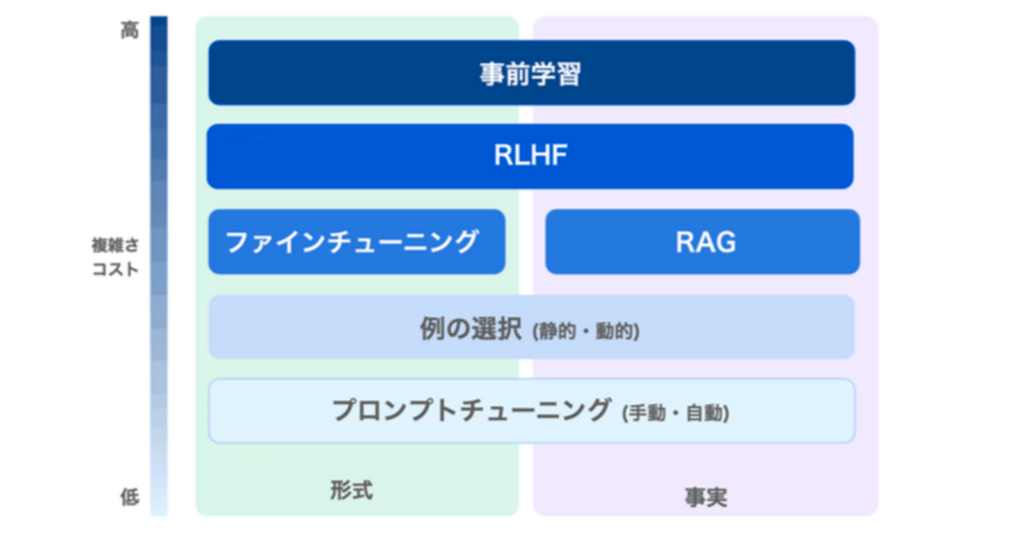
そもそもファインチューニングは、あらかじめ数十〜数百の回答例をLLMに学習させておく手法です。これは人間でいうところの「テスト勉強」で、個々の事実が回答に反映されない場合もあります。
対してRAGは、回答直前のLLMに答えを与える「カンニング」方式。RAGとは違い、ほぼダイレクトに事実が示せるというわけです。
回答の品質が安定しない
ファインチューニングでスキル・タスクをLLMに仕込んだとしても、望みどおりの回答が得られるとは限りません。プロンプトが短くて済むということは、回答の自由度・不安定さが増すということ。学習内容を無視した回答が返ってくるケースも多々あるのです。
多大なコストがかかる
OpenAI製のLLMでファインチューニングを行う場合、RAGと比べて学習・運用時のコストが高くつきます。最もコストと性能のバランスが取れた「gpt-4o-mini-2024-07-18」でコストを概算・比較してみると……
| ファインチューニング | RAG | |
|---|---|---|
| 学習コスト | 3(ドル/1Mトークン)÷ 10,000(トークン) = 約0.03ドル | 0.02(ドル/1Mトークン)÷ 10,000(トークン) = 約0.0002ドル ※text-embedding-3-small使用時 |
| 入力コスト | 0.3(ドル/1Mトークン)÷ 20トークン = 約0.003ドル | 0.15(ドル/1Mトークン)÷ 320(トークン) = 約0.0015ドル |
| 出力コスト | 1.2(ドル/1Mトークン)÷ 300(トークン) = 約0.012ドル | 0.6(ドル/1Mトークン)÷ 300(トークン) = 約0.006ドル |
| 見積額 | 初期投資:約0.03ドル 回答毎のコスト:約0.015ドル | 初期投資:約0.0002ドル 回答毎のコスト:約0.0075ドル |
以上のとおりその差は歴然。(※2)ファインチューニングでは初期投資にRAGの150倍、回答毎にRAGの2倍もの費用がかかってしまうんです。
さらに学習でトライ&エラーを繰り返すことも踏まえると、初期投資のコストはまだまだ増加します。ファインチューニングを導入したい場合は、導入効果がコストに見合うか否かを念入りに検証したほうがよいでしょう。
なお、RAGの進化形について詳しく知りたい方は下記の記事もあわせてご確認ください。

LLMのファインチューニングを成功させるコツ
ここからは、LLMでのファインチューニングを成功に導くコツを4点紹介!ファインチューニング込みでAIツール開発をお考えの方は以下も必見です。
学習データの一貫性を保つ
ファインチューニングでは口調の反映からデータ形式の指定まで、何を目標とする場合であっても「学習データの一貫性」が大事。学習データのフォーマットがブレていると、望みどおりの回答が得にくくなってしまいます。
したがって、ファインチューニングに際しては学習データを整える「前処理」が不可欠です。その方法はRAGの前処理とほぼ同じで……
- 質問 – 回答間の対応関係に一貫性をもたせる
- 言語を統一する
- 記号を含めない
- 内容を重複させない
- 表記揺れをなくす
- 「#」「-」等、プロンプトの構造を統一する
以上のとおりになっています。
質問から回答までの思考過程をわかりやすく規定する
いくらTransformer搭載のLLMといえど、学習データが難解だとファインチューニングは失敗に終わってしまいます。したがって、質問から回答までの思考過程をわかりやすくすることが重要です。
その「わかりやすさ」の目安としては……
誰がみても、質問から正しい回答が導き出せる状態
に尽きます。このわかりやすさを実現する具体的な方法は下記のとおりで、GPTsの作成時同様シンプルです。
- わかりやすい日本語で書く
- こそあど言葉を使わない
- 手順を細かいステップに分ける
- 無意識に踏んでいる手順も説明する
コストを抑えるためにも、学習データは徹底的にわかりやすさを追求しましょう。
プロンプトテクニックと組み合わせる
ファインチューニングでは、学習させた内容がうまく回答に反映されないことも多々あります。その場合は、プロンプトテクニックも併用すると回答が改善されるでしょう。
訓練とテストでデータを分ける
ファインチューニングで学習データを用意する際には、訓練用とテスト用でデータを分けるのがおすすめ。学習範囲外のテスト用データにてファインチューニングを検証することで、回答の改善度合いが正しく把握できます。
LLMにおけるファインチューニングの今後
今後、ファインチューニングでできることは増えていくと考えられます。その鍵はLLMの進化に伴って、入力トークン数の限界「コンテキストウィンドウ」が増えていることにあります。
膨大なコンテキストウィンドウを有する次世代のLLMは、一回のプロンプトで大量の知識吸収(Few-ShotならぬMany-Shot)が可能。例えば、100万トークンものコンテキストウィンドウを誇るGoogle製LLM「Gemini 1.5 Pro」は……
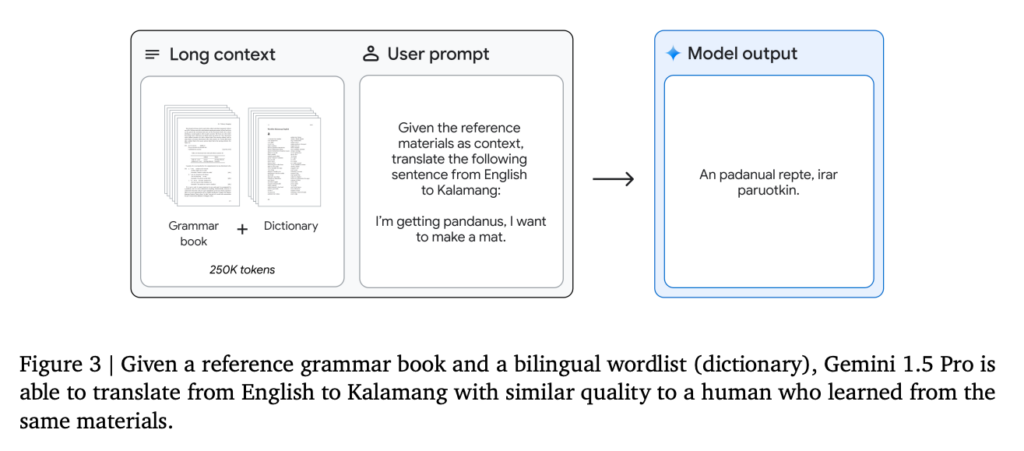
一度の入力で学習範囲外の新規言語が習得できます。
この次世代のLLMにファインチューニングを行うことで……
- 業界の暗黙知・ノウハウを学んだ自律型AIエージェント
- 誤動作の少ない生成AI搭載型のRPA
といったソリューションが実現するかもしれません。
なお、同じく膨大なコンテキストウィンドウを誇るLLMについて詳しく知りたい方は下記の記事もあわせてご確認ください。

LLMのファインチューニングは使い所を見極めよ!
当記事では「LLMでのファインチューニング」について、そのメリット・デメリットや開発時の注意点をご紹介しました。ファインチューニングのメリット・デメリット(RAG比)は、というと……
以上のとおりでした。
そんなファインチューニングは「キャラクターもののAIチャットボット」や「プログラミング用のAIツール」といったソリューションに最適です。
また、国内事例としてよく見るAIチャットボットやCSサポートの約8割はRAGによる事例です。ファインチューニングを使うことで、参入障壁を高くすることも可能だと思います。
予算とは要相談ですが、成功すれば意のままに動くAIツールが作れるかもしれません。

最後に
いかがだったでしょうか?
弊社では、
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

